深度学习:从线性回归到神经网络
初识深度学习
什么是深度学习
关系:人工智能 --> 机器学习 --> 深度学习 --> 卷积神经网络
深度学习和机器学习的关系:
- 机器学习:随着数据量增加会改进性能的算法
- 深度学习:使用多层神经网络学习。深度学习是机器学习的子集。
传统系统和深度学习的区别:
- 传统编程系统:定义规则,输入数据获取输出(定义f(x)、x求得y)
- 深度学习系统:输入答案和数据,输出规则(定义x、y求得f(x),且f(x)具有泛化性)
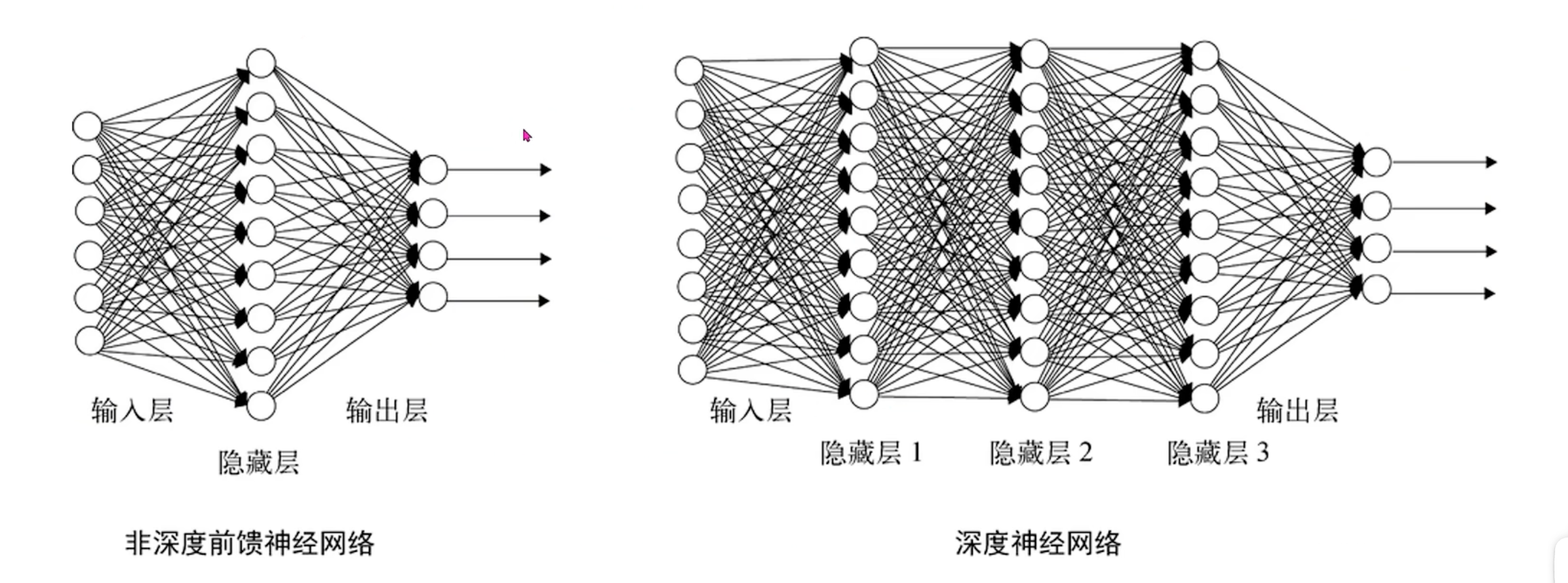
深度神经网络
什么是过拟合
过拟合:过多地学习了数据,会导致泛化性下降。
训练次数过多,且数据集较为单一。模型会增加对一套算法的依赖性,从而降低了泛化性。
使用一个关卡训练 AI 找到最佳打法,因为关卡较为固定,AI 找到了最优打法并高度依赖、不断精益求精,遗忘掉了其他打法的可能性。
神经网络参数
w 权重:描述特征的重要性
b 偏置:用于实现经过原点线性可分
深度学习框架
框架封装了不同的模型,提高易用程度。
- TensorFlow + Keras
- PyTorch
需要安装的模块:
- TensorFlow
- keras
- numpy
- matplotlib
- pandas
- sklearn==0.0
线性回归模型与梯度下降法
线性回归模型与枚举法
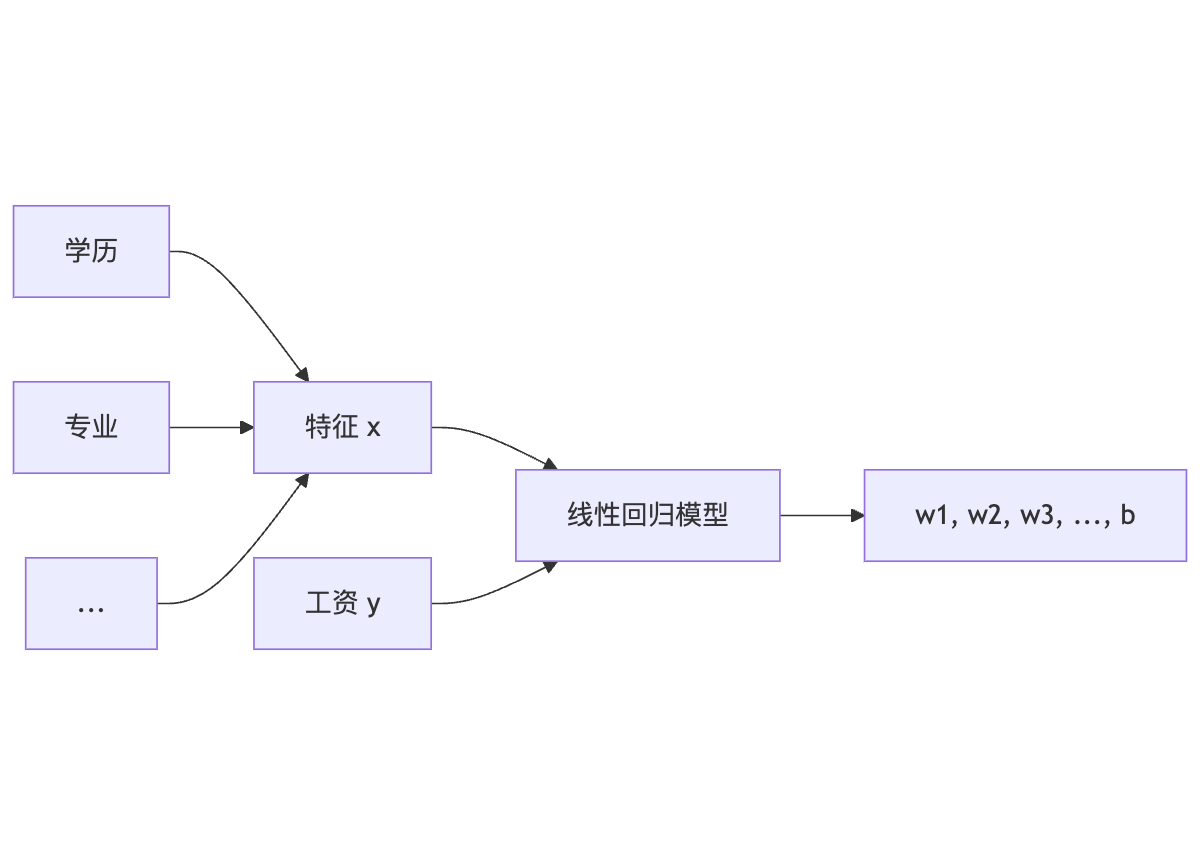
线性回归模型定义:

- w:权重
- b:偏置
损失函数:用于计算输出和真实值之间的误差
线性回归的目标:寻找一组参数w、b,使损失函数最小。(预测结果接近真实数据)
如何求w、b --> 枚举法求解:猜呗!慢慢猜 w 是多少!😅(不现实)
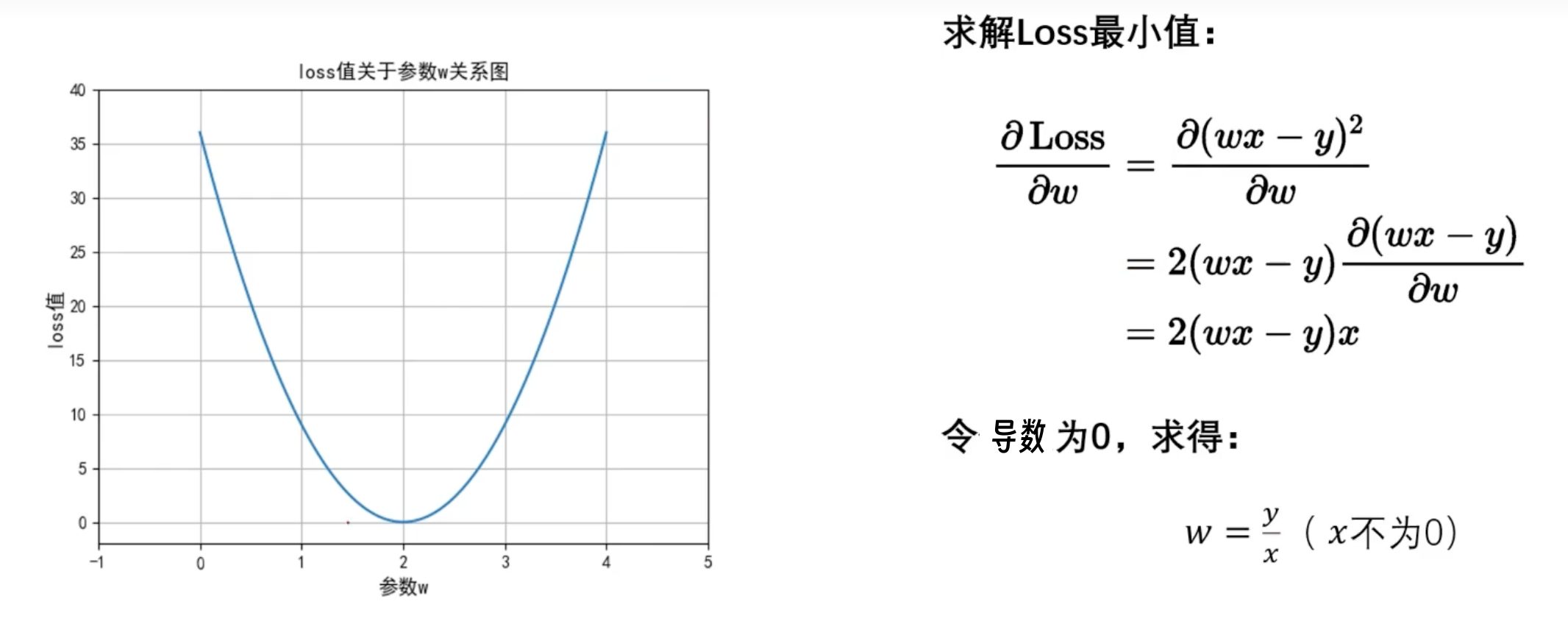
最小二乘法
满足二次函数,通过
😋 不要怕数学。学好数学并不难。
对于向量形式:
利用 导数为零 得到极小值。

矩阵可逆的充要条件之一是其行列式不为0,当矩阵的行列式等于0时,矩阵一定不可逆。
存在问题:由于
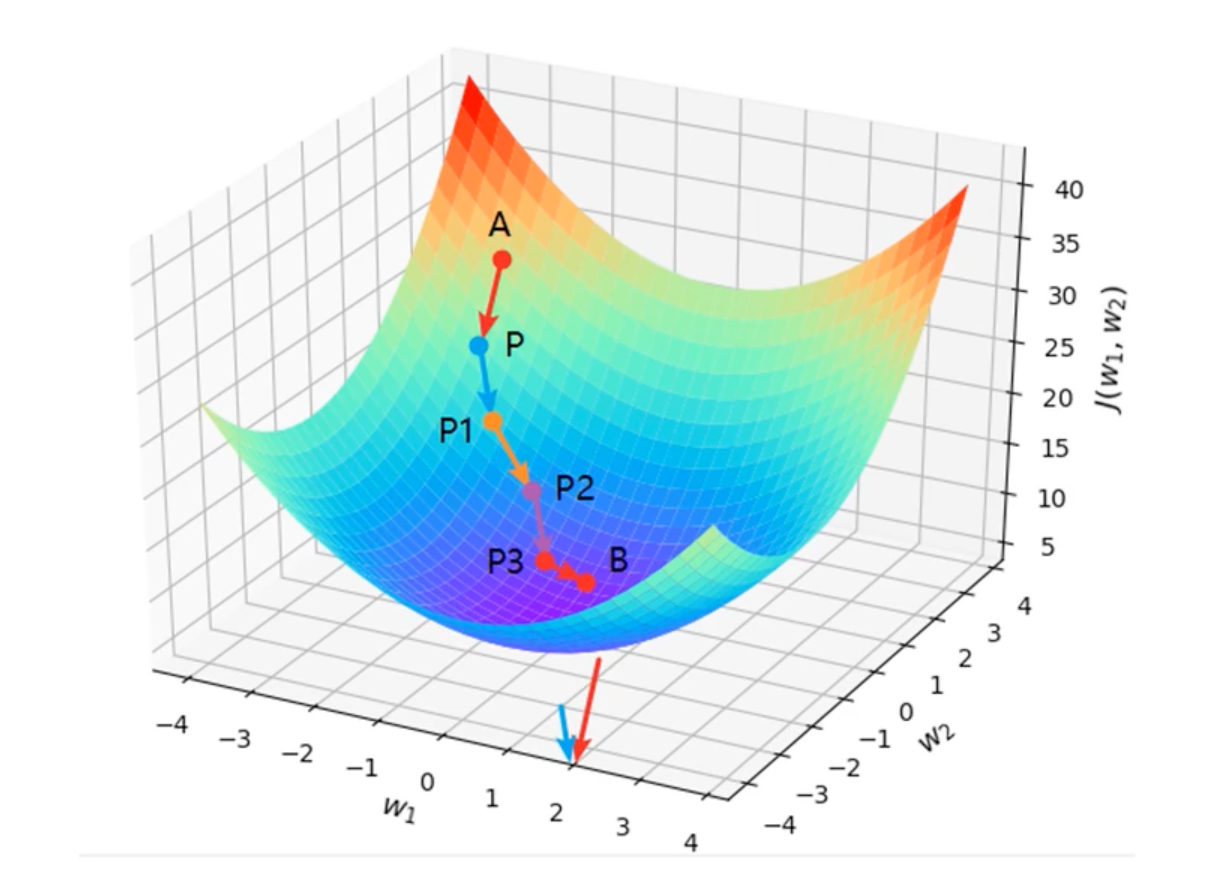
⭐️ 梯度下降法
带有方向的穷举法
核心:方向、步伐
梯度下降法参数更新的计算公式:
:学习率(步伐) :当前值的导数值,取负数(下降的方向)
小案例:

学习率较为重要,常常为经验值(0.01、0.1...)。
多参数求解:求偏导数
代码实现
深度学习过程:
- 定义模型(线性回归、逻辑回归...)
- 数据:特征 (x) 与标签 (y)
- 损失函数:定义预测值与真实值的差距
- 梯度下降法更新参数(权重w和偏置b)
# 线性回归模型
def forward(x):
# y' = wx
return w * x
# 损失函数 (多个数值求平均损失)
def cost(x, y):
cost_val = 0
for xx, yy in zip(x, y):
# loss = (wx - y)^2
cost_val += (xx * w - yy) ** 2
return cost_val / len(x)
# 梯度下降 (多个数值求平均损失)
def gradient(x, y):
# 梯度值
grad = 0
for xx, yy in zip(x, y):
# w = w - a(dLoss(w) / dw)
# dLoss(w) / dw = 2x(wx - y)
grad += 2 * xx * (w * xx - yy)
return grad / len(x)
if __name__ == '__main__':
# 数据集:特征
x_data = [1, 2, 3, 4]
# 数据集:标签
y_data = [10, 20, 30, 40]
# 学习率 (经验值)
learn_rating = 0.01
# 初始化参数 w (随机值/经验值)
w = 1
# 多次更新w参数
for epoch in range(100):
w -= learn_rating * gradient(x_data, y_data)
cost_num = cost(x_data, y_data)
if epoch % 10 == 0:
print(f'Epoch: {epoch}\tw: {w:.8f}\tcost: {cost_num:.8f}\t')
# 使用更新过的 w 进行预测
test_data = 5
print(f'对于5的预测结果是: {forward(5)}')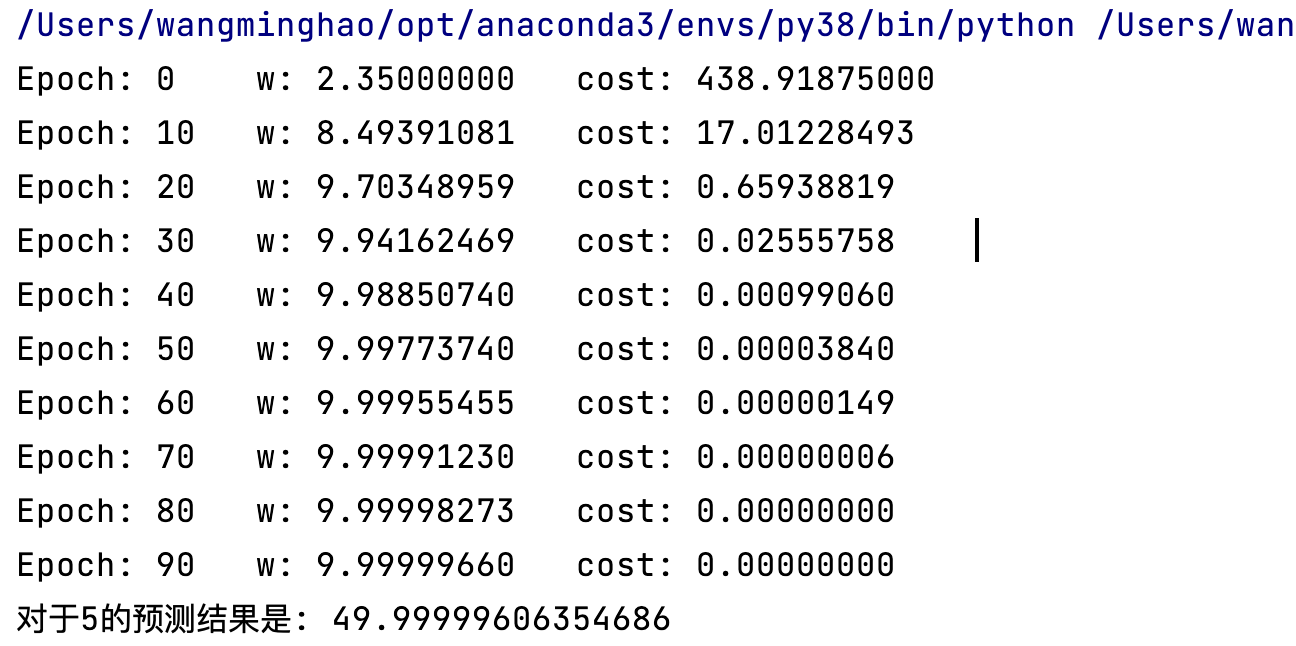
逻辑回归模型
机器学习的分类
机器学习的两个种类:
- 有监督学习:数据集带标签(题目有正确答案)
- 无监督学习:数据集不带有标签,比如聚类算法
有监督学习两大任务:
- 回归任务:预测结果是无限个值,是连续值(体重值、分数值、可能性百分比...)
- 分类任务:预测结果的种类有限,是离散值(是/不是、健康/不健康...)
逻辑回归模型原理
逻辑回归是利用回归的方法进行二分类。
常用
或者 表示 sigmoid 函数。


线性回归模型的结果通过 sigmoid 函数映射到0-1的区间,通过阈值将其二分类。

损失函数
定义损失函数(以一维为例):
- 对于一个样本,其真实标签为
(取值为 0 或 1)。我们希望当 时, 尽可能地接近 1,当 时, 尽可能地接近 0。 - 可以通过最大化
和 的乘积来实现这一点,即 。 - 同时,也希望最小化
和 的乘积,这样能使预测为负类时的概率尽可能地小,即 。 - 对数函数有助于更方便地处理概率,提高计算稳定性。
权重 w 的更新
使用梯度下降更新 w 权重值:

偏置 b 的更新
使用梯度下降更新 b 偏置值:

模型的评价指标
分类模型(离散结果)
定义正类。比如及格为正类,不及格为负类。
- 真正(TP):真实及格,预测也是及格
- 真负(TN):真实不及格,预测也是不及格
- 假正、误报(FP):真实为不及格,预测成了及格
- 假负、漏报(FN):真实为及格,预测成了不及格
准确率:
对于样本不均衡数据(原始的数据中,正类和负类数量不一致),准确率ACC不能完全衡量模型好坏。
精确率:在正类中猜对的概率。
召回率(查全率):在所有正类中,预测到的概率。
召回率有局限性:若全猜正类,FN(漏报)为0,召回率100%。
F1值:精确率和召回率的均值。
回归模型(连续结果)
平均绝对误差(MAE)

均方误差(MSE)

均方根误差(RMSE)

MAPE

代码实现
特征数据 x 中不同特征的物理量纲不同,模型依赖数值较大的特征。
解决办法:归一化(求平均值化为0~1之间)
# 0. 导入模块
# 数据处理
import numpy as np
import pandas as pd
# 划分数据集合测试集
from sklearn.model_selection import train_test_split
# 用于特征数据的归一化
from sklearn.preprocessing import MinMaxScaler
# 导入逻辑回归模型
from sklearn.linear_model import LogisticRegression
# 计算评价指标
from sklearn.metrics import classification_report
# 1. 读取数据
dataset = pd.read_csv('heart_disease.csv')
# print(dataset)
# 2. 划分特征与标签
# [:, :-1] 表示选择所有的行(":")和除了最后一列之外的所有列(":-1")
X = dataset.iloc[:, :-1]
Y = dataset.iloc[:, -1]
# 3. 对特征值进行归一化
scaler = MinMaxScaler(feature_range=(0, 1))
X = scaler.fit_transform(X)
# 4. 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.2)
# 5. 实例化模型
lr = LogisticRegression()
lr.fit(x_train, y_train)
# 6. 训练完成,输出w和b的值
print(f'w: {lr.coef_}')
print(f'b: {lr.intercept_}')
# 7. 使用模型数据进行预测
result = lr.predict(x_test)
# print(f'预测结果: {result}')
# print(f'y_test: {y_test.values}')
check = 0
for i, j in zip(result, y_test.values):
if i == j:
check += 1
print(f"准确率: {check / len(result) * 100 : .5f}%")
# 8. 查看模型评测结果
report = classification_report(y_test, result, labels=[0, 1])
print(report)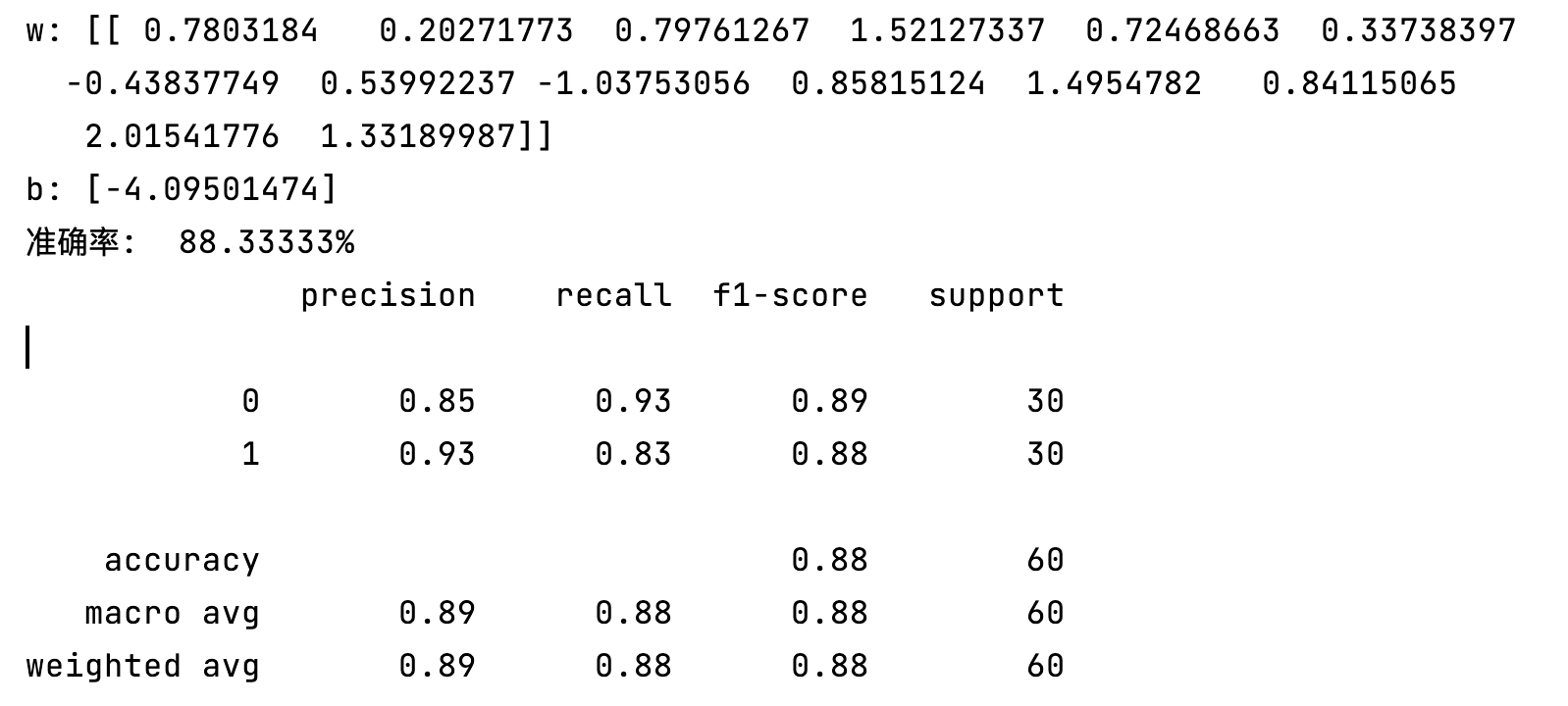
全连接神经网络
全连接神经网络的结构
整体结构
神经网络:类似神经元,前一层可以不断地传递给下一层。
神经网络模型由多个单元结构组成。
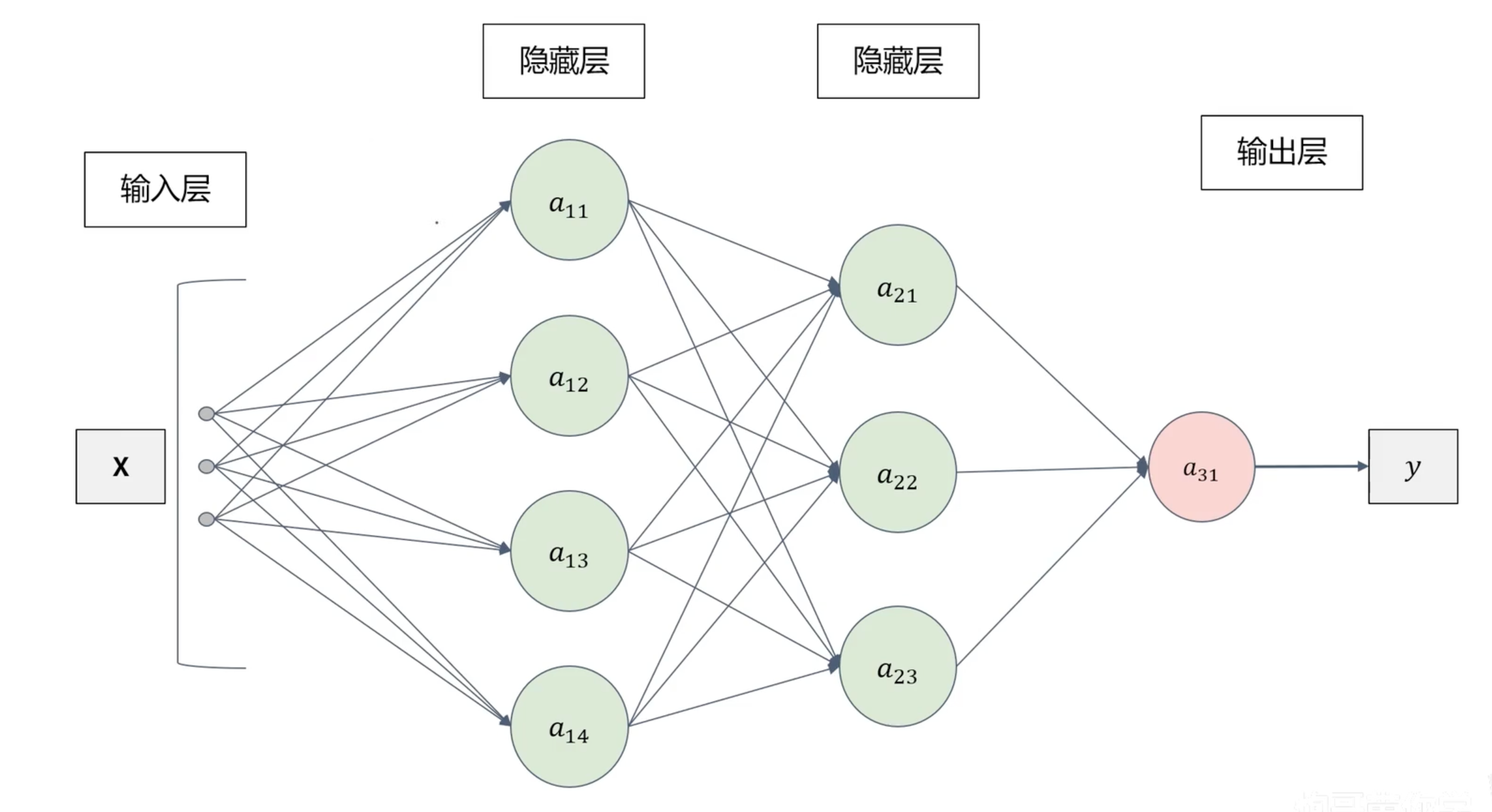
单元结构
单元结构的数学公式:
h(x):激活函数
- 比如sigmoid就是激活函数之一
- 隐藏层大多需要激活函数
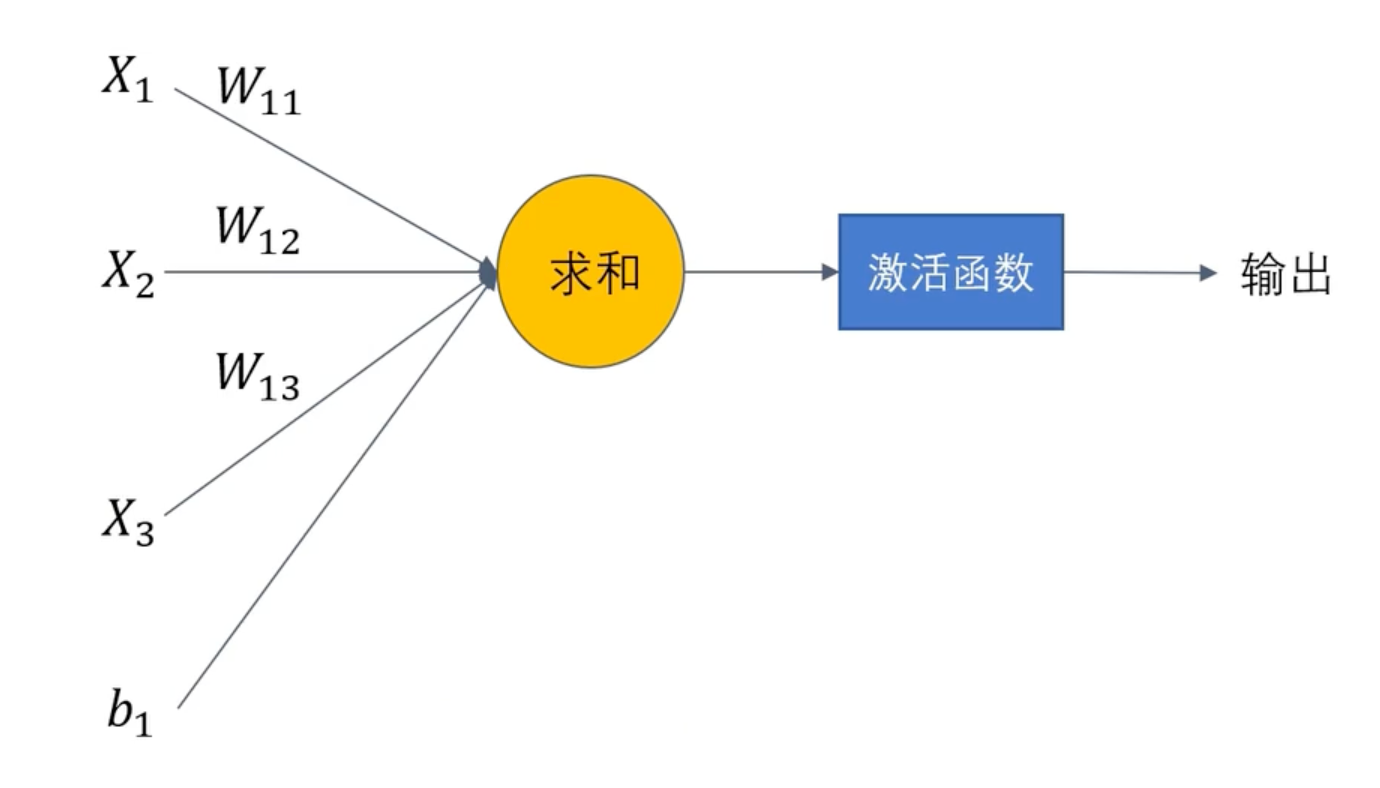
激活函数
激活函数概述
激活函数是非线性的函数(图像不是直线的)。
非线性激活函数引入了非线性变换,使得神经网络可以逼近任意复杂的函数,从而更好地完成分类、回归和其他任务。增加神经网络的表达能力,使其能够学习和表示更加复杂的模式和关系。
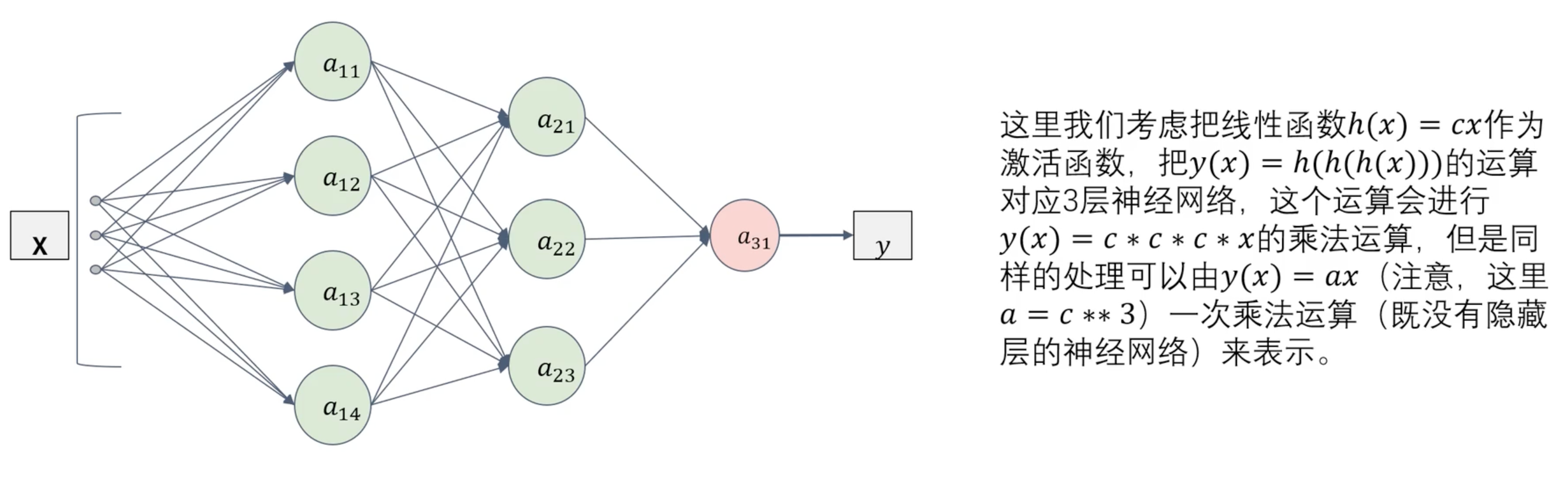
激活函数必须是非线性的,因为如果激活函数是线性的话,无论神经网络有多少层,整个网络都可以被简化为单层网络。
和 都是线性回归。
Sigmoid函数
函数公式和导数:
函数及其导数图像:
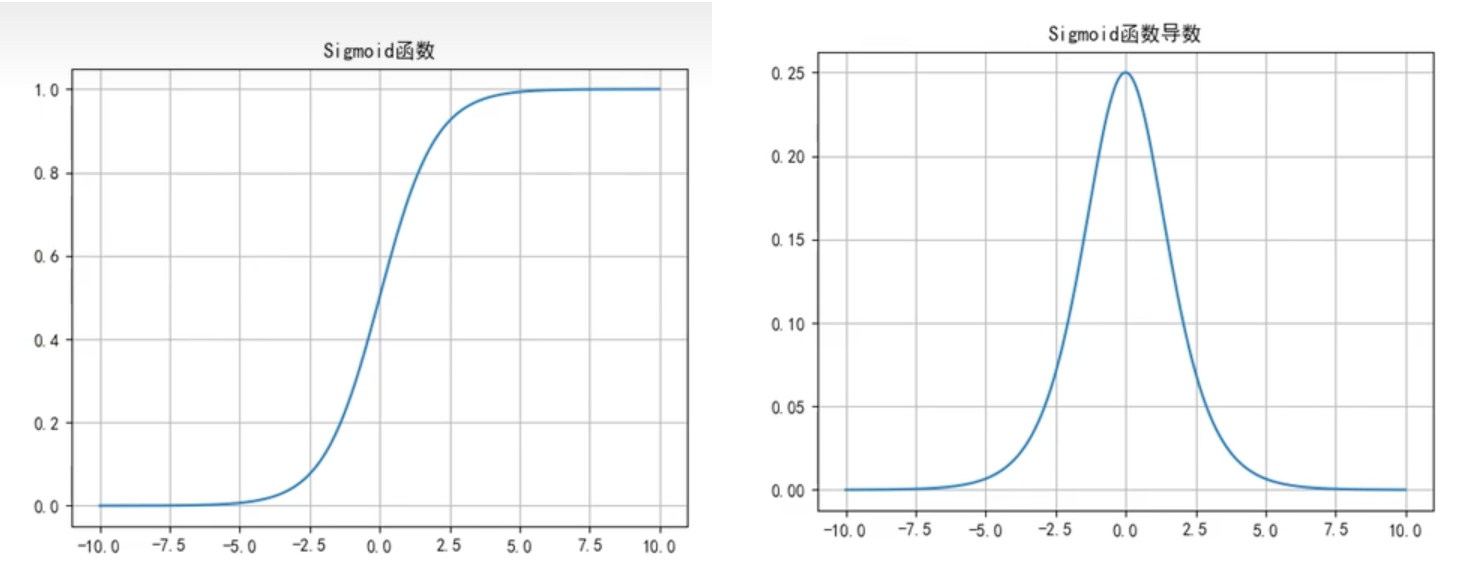
Sigmoid函数优点:简单、非常适用分类任务;
Sigmoid函数缺点:
- 反向传播训练时有梯度消失的问题;
- 输出值区间为(0,1),关于0不对称;
- 梯度更新在不同方向走得太远,使得优化难度增大,训练耗时。
Tanh函数
函数公式和导数:

函数及其导数图像:
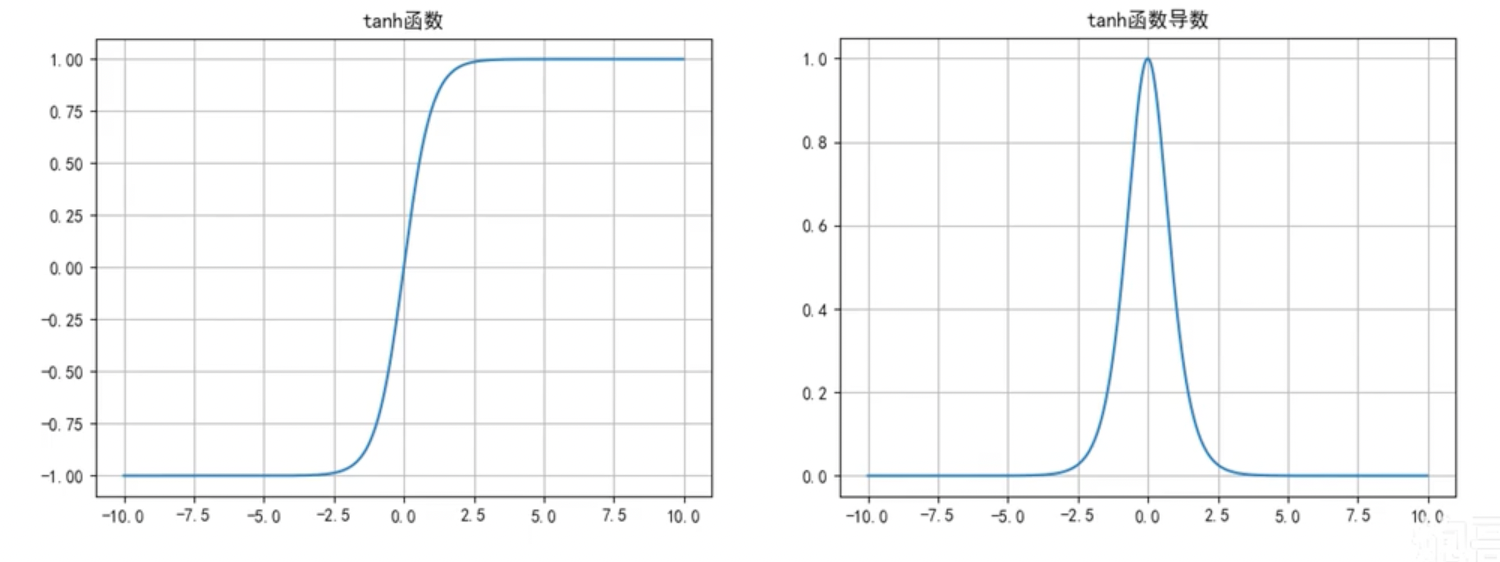
Tanh函数优点:
- 解决了Sigmoid函数输出值非0对称的问题,
- 训练比Sigmoid函数快,更容易收敛;
Tanh函数缺点:
- 反向传播训练时有梯度消失的问题,
- Tanh函数和Sigmoid函数非常相似。
ReLU函数
函数公式和导数:

函数及其导数图像:
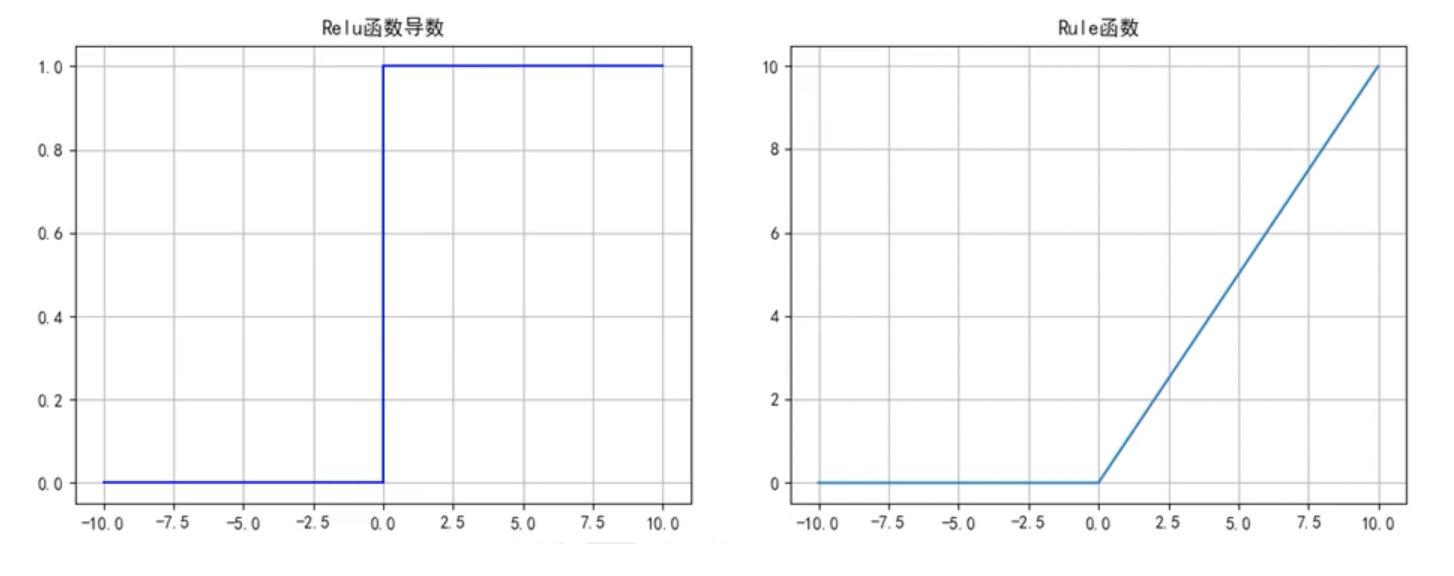
ReLU函数优点:
- 解决了梯度消失的问题;
- 计算更为简单,没有Sigmoid函数和Tanh函数的指数运算;
ReLU函数缺点:
- 训练时可能出现神经元死亡(损失函数导数为0,无法更新参数)
- 不关于原点对称
Leaky ReLU函数
函数公式和导数:

函数及其导数图像:
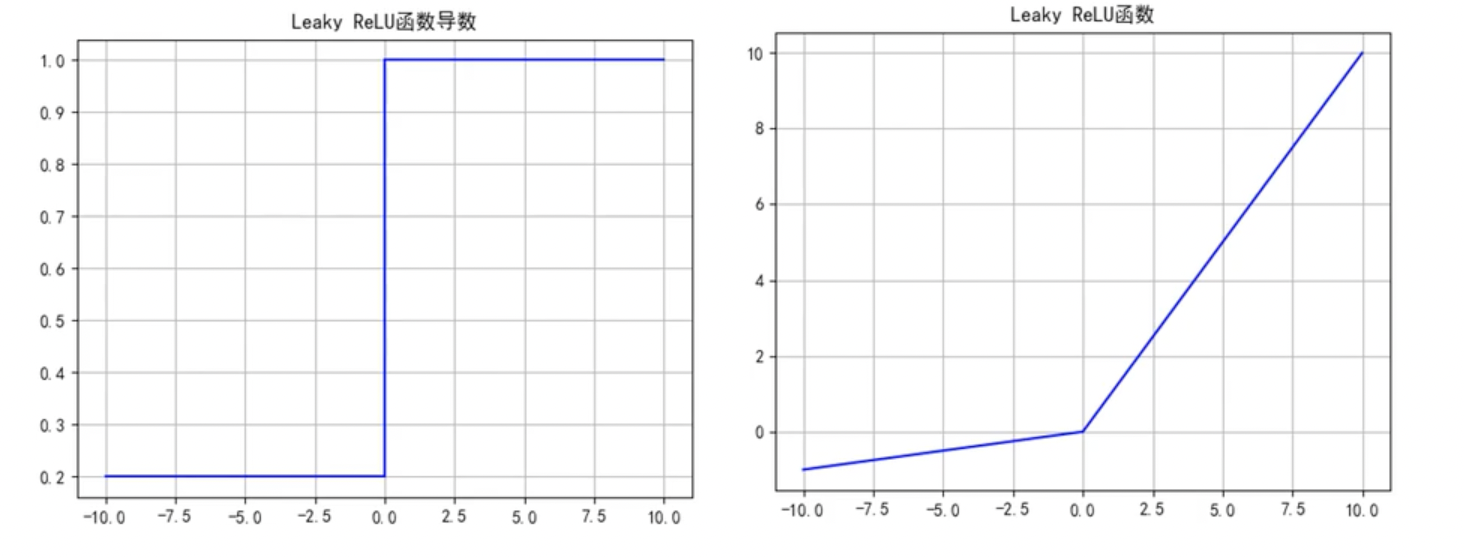
Leaky ReLU函数优点:解决了ReLU的神经元死亡问题;
Leaky ReLU函数缺点:无法为正负输入值提供一致的关系预测(不同区间函数不同)
当输入是正数时,神经元的输出会受到一个比较大的斜率的影响,而当输入是负数时,神经元的输出会受到一个比较小的斜率的影响。这种情况下,神经元对于正数和负数的处理方式不同,可能会导致模型学习到不一致的特征表示,从而影响模型的性能。
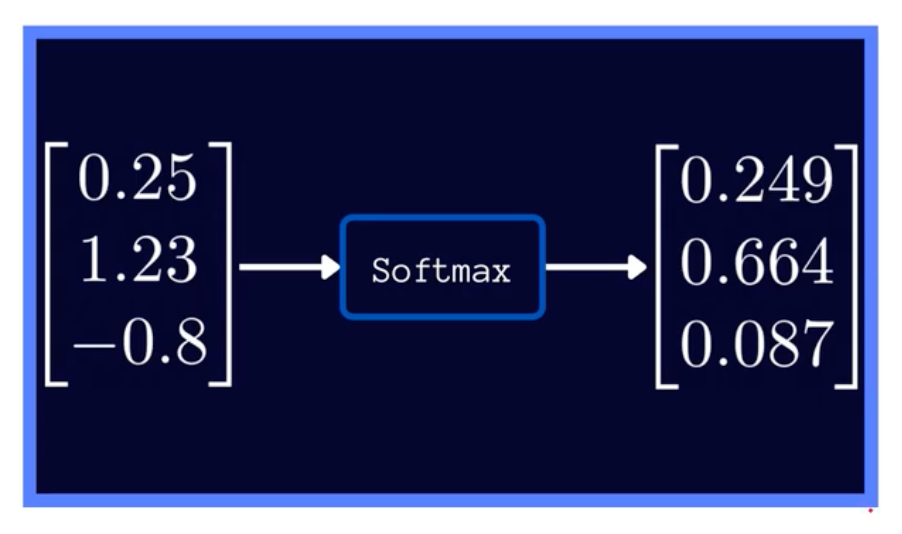
SoftMax函数
函数公式和导数:
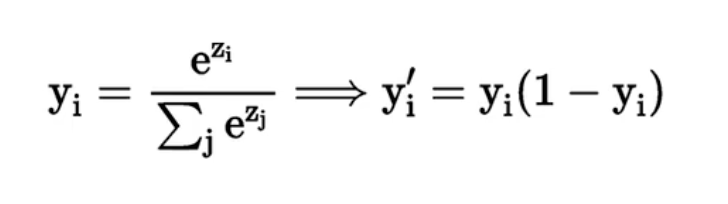
SoftMax函数常常作为输出层,用于多分类。
前向传播
前向传播:模型推理的过程。
将输入数据通过网络层层传递,最终得到输出结果的过程。
已知w、b,通过 x 求 y 的过程
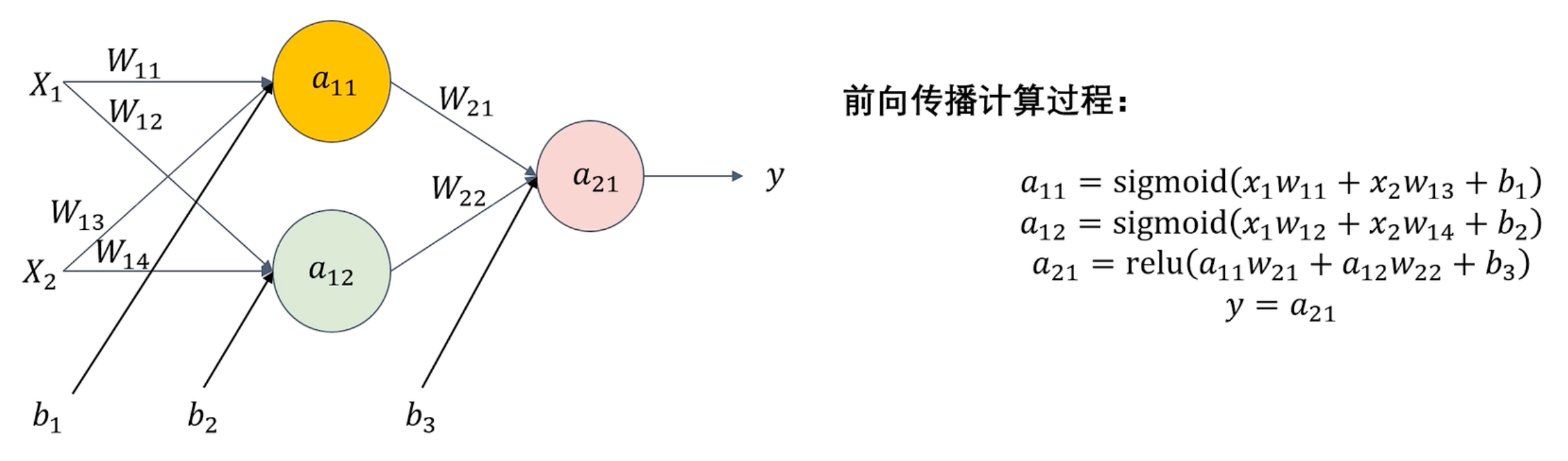
前向传播计算过程:
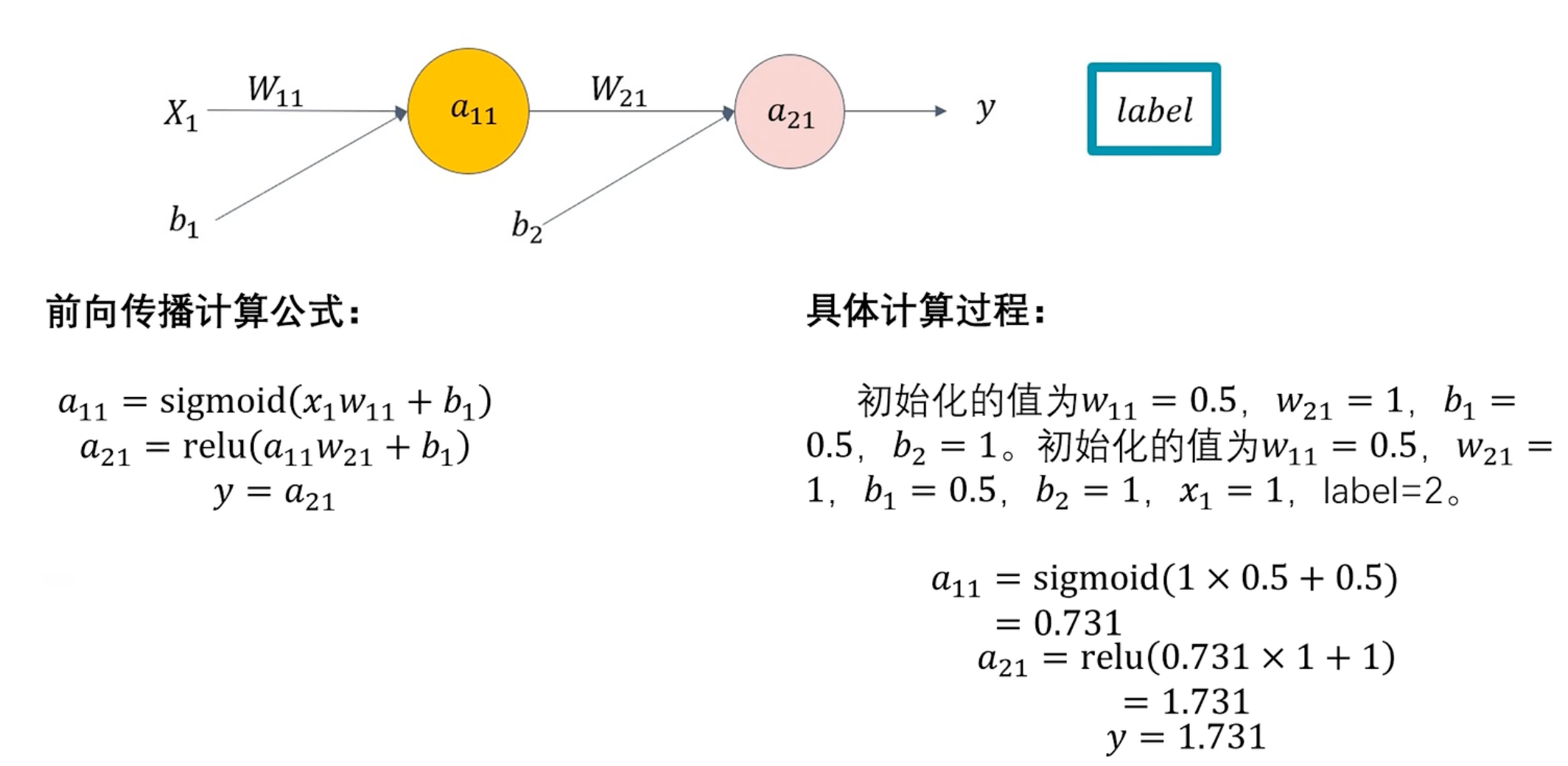
数据会被划分三类:
- 训练集
- 验证集
- 测试集
- 制作两份损失函数图像:训练集损失图和验证集损失图,避免产生过拟合。
链式求导法则
单变量链式法则定义:

单变量链式法则算例:

多变量链式法则定义:
求偏导:把无关项当成常量,两次求导相加。

多变量链式法则算例:

反向传播
反向传播:通过损失函数和梯度下降求得w、b的过程。
神经网络学习的过程:
- 划分数据集(csv → X/Y → x/y_train/test)
- 选择模型
- 前向传播(计算推理值)
- 计算误差(计算推理值和真实值的差距)
- 计算梯度(计算损失函数对于每个参数的变化率/导数值)
- 反向传播(利用梯度下降更新参数)
- 设置学习轮次
- 导出模型
- 应用模型
分类检测代码实现
导入依赖
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 归一化
from sklearn.preprocessing import MinMaxScaler
# 划分数据集
from sklearn.model_selection import train_test_split
# 计算评价指标
from sklearn.metrics import classification_report
import keras
# 创建全连接层(稠密层)
from keras.layers import Dense
# 转换"独热编码"
from keras.utils import to_categorical
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False数据预处理
独热编码:将多分类任务转化为独热向量,减小不同分类直接的影响。
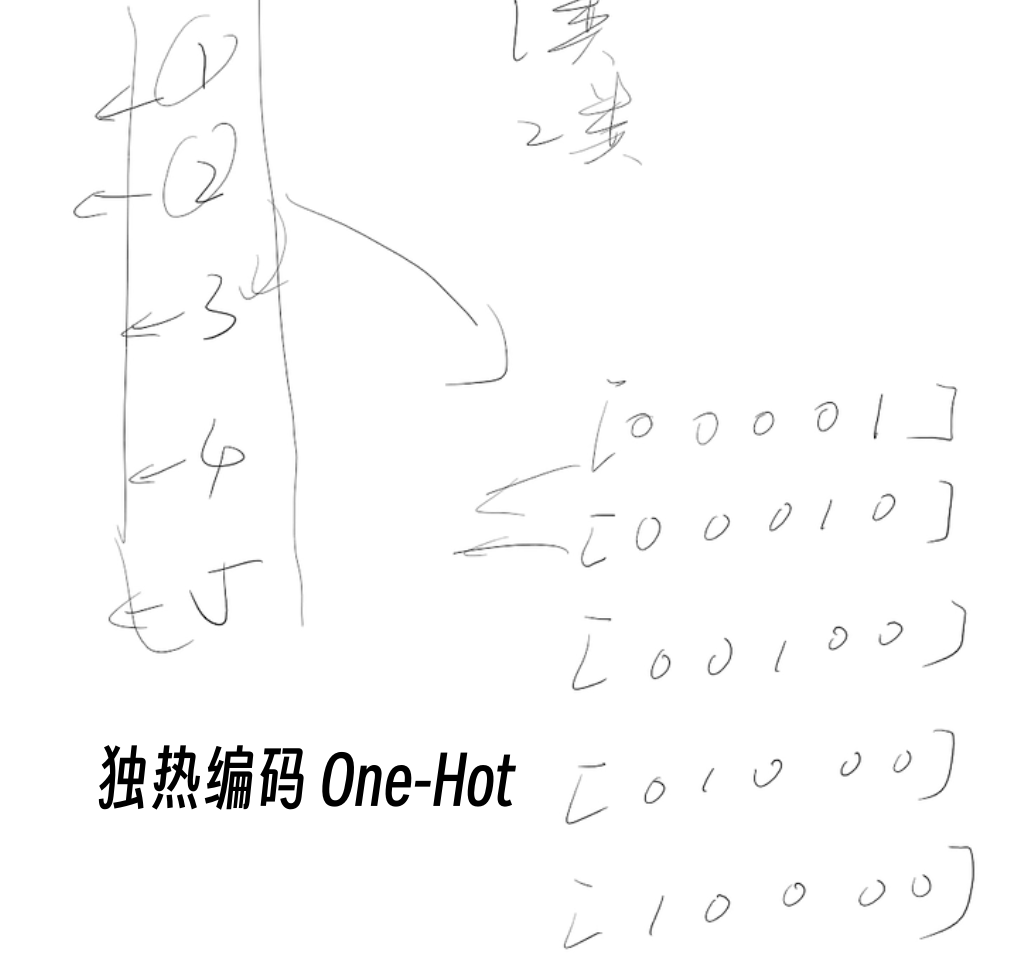
# 加载数据集
dataset = pd.read_csv("../heart_disease.csv")
# 划分数据集
X = dataset.iloc[:, :-1]
Y = dataset['target']
# 将特征规归一化
sc = MinMaxScaler(feature_range=(0, 1))
X = sc.fit_transform(X)
# 将标签转化为独热向量
Y = to_categorical(Y, 2)
# 划分测试集和训练集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.2, random_state=114514)
模型训练
# 利用Keras搭建模型
model = keras.Sequential()
# 隐藏层第一层
model.add(Dense(10, activation='relu'))
# 隐藏层第二层
model.add(Dense(10, activation='relu'))
# 二分类 -> 输出两个神经元
model.add(Dense(2, activation='softmax'))
# 编译模型
# loss损失函数: 交叉熵
# optimizer优化器: 优化模型参数
# metrics评估指标: 评估模型性能
model.compile(loss="categorical_crossentropy", optimizer="SGD",
metrics=["accuracy"])
# 模型训练
# validation_data: 验证集
# verbose: 显示训练过程
his = model.fit(x_train, y_train, epochs=100, batch_size=16,
validation_data=(x_test, y_test), verbose=2)
# 保存模型
timestamp = datetime.datetime.now().strftime('%Y-%m-%d-%H:%M:%S')
os.makedirs(f"./log_{timestamp}")
model.save(f"./log_{timestamp}/model.keras")
# loss对比图
plt.plot(his.history['loss'], 'b', label='训练集损失')
plt.plot(his.history['val_loss'], 'r', label='验证集损失')
plt.legend()
plt.savefig(f"./log_{timestamp}/loss.png")
plt.show()
# 准确率对比图
plt.plot(his.history['accuracy'], 'b', label='训练集准确率')
plt.plot(his.history['val_accuracy'], 'r', label='验证集准确率')
plt.legend()
plt.savefig(f"./log_{timestamp}/accuracy.png")
plt.show()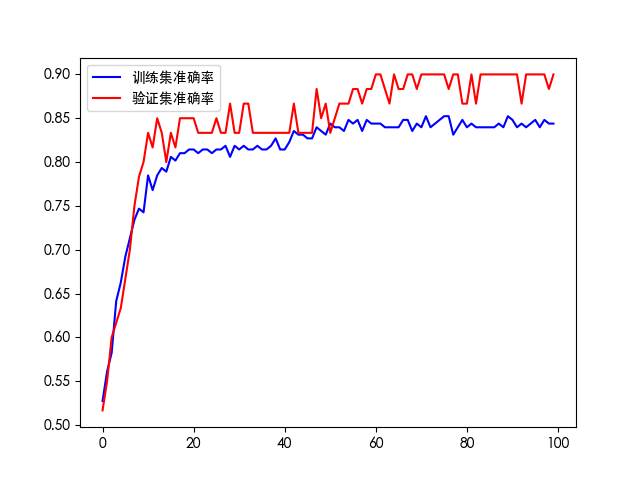
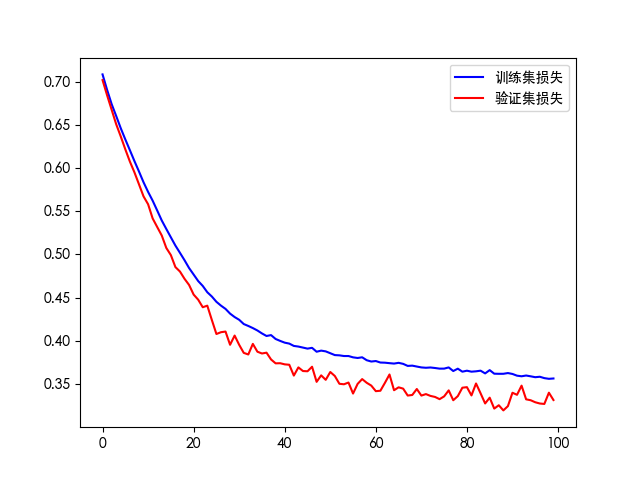
如果训练轮次过多会出现过拟合现象。
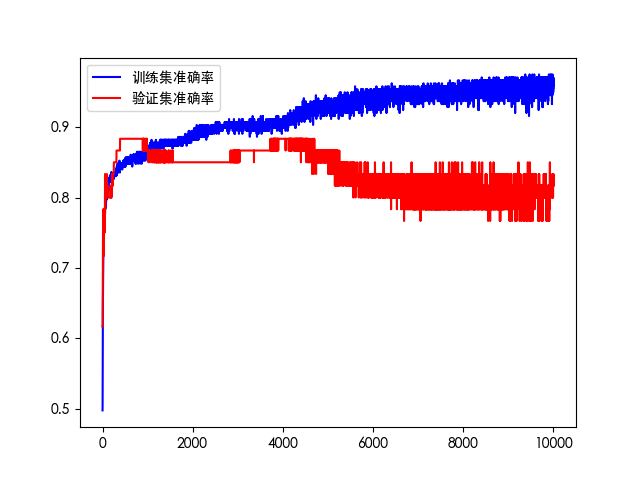
模型预测
# 加载数据集
dataset = pd.read_csv("../heart_disease.csv")
# 划分数据集
X = dataset.iloc[:, :-1]
Y = dataset['target']
# 将特征规归一化
sc = MinMaxScaler(feature_range=(0, 1))
X = sc.fit_transform(X)
# 划分测试集和训练集
_, x_test, _, y_test = train_test_split(X, Y, test_size=.2, random_state=114514)
# 导入模型
model = keras.models.load_model("./log_2024-01-26-20:12:37/model.h5")
# 推演
pre_test = model.predict(x_test)
# 将预测结果转化为0,1
# axis: 0表示按列处理,1表示按行处理
pre_test = np.argmax(pre_test, axis=1)
# 计算准确率
check = 0
for i, j in zip(pre_test, y_test.values):
if i == j:
check += 1
print(f"准确率: {check / len(pre_test) * 100 : .5f}%")
# 评估模型
report = classification_report(y_test, pre_test)
print(report)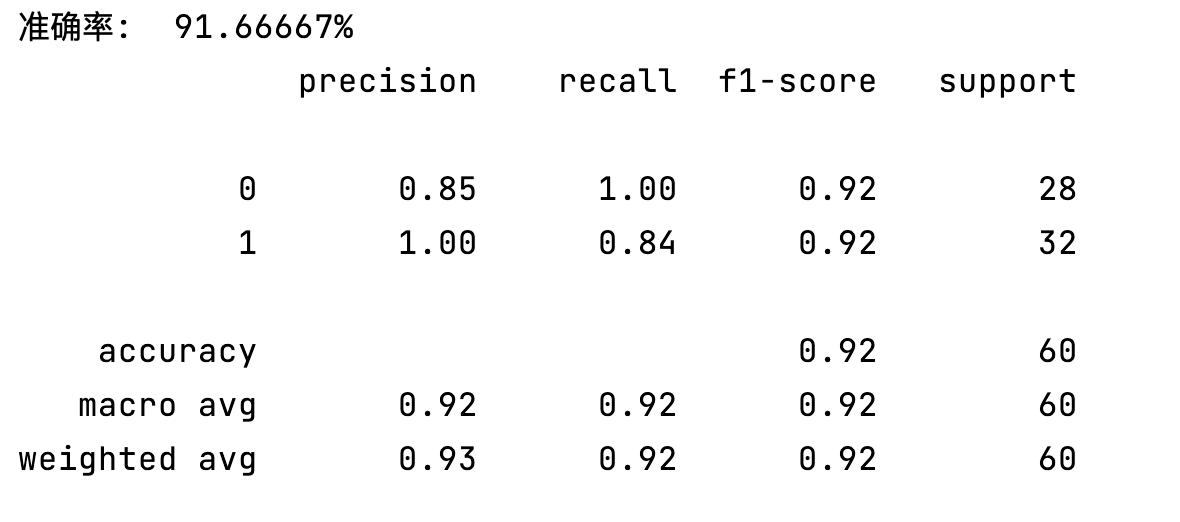
回归预测代码实现
损失函数的选择:
- 分类模型:交叉熵
- 回归模型:均方误差
模型训练
这里没有找到合适数据,成功率较低。仅供参考思路。
import datetime
import os
import pandas as pd
import matplotlib.pyplot as plt
# 归一化
from sklearn.preprocessing import MinMaxScaler
# 划分数据集
from sklearn.model_selection import train_test_split
import keras
# 创建全连接层(稠密层)
from keras.layers import Dense
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 加载数据集
dataset = pd.read_csv("../heart_disease_age.csv")
# 将特征与标签归一化
sc = MinMaxScaler(feature_range=(0, 1))
dataset = sc.fit_transform(dataset)
# 格式转换
dataset = pd.DataFrame(dataset)
# 划分数据集
X = dataset.iloc[:, :-1]
Y = dataset.iloc[:, -1]
# 划分测试集和训练集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.2,
random_state=123)
# 利用Keras搭建模型
model = keras.Sequential()
# 隐藏层第一层
model.add(Dense(10, activation='relu'))
# 隐藏层第二层
model.add(Dense(10, activation='relu'))
# 输出层:不使用激活函数
model.add(Dense(1))
# 编译模型
# loss损失函数: 均方误差
# optimizer优化器: 优化模型参数
# metrics评估指标: 评估模型性能
model.compile(loss="mse", optimizer="SGD")
# 模型训练
# validation_data: 验证集
# verbose: 显示训练过程
his = model.fit(x_train, y_train, epochs=200, batch_size=8,
validation_data=(x_test, y_test), verbose=2)
# 保存模型
timestamp = datetime.datetime.now().strftime('%Y-%m-%d-%H:%M:%S')
os.makedirs(f"./log_{timestamp}")
model.save(f"./log_{timestamp}/model.h5")
# loss对比图
plt.plot(his.history['loss'], 'b', label='训练集损失')
plt.plot(his.history['val_loss'], 'r', label='验证集损失')
plt.title(f"loss-{timestamp}")
plt.legend()
plt.savefig(f"./log_{timestamp}/loss.png")
plt.show()模型预测
反归一化:需要将归一化过的特征和标签合并后反归一化,
import keras
import numpy as np
import pandas as pd
# 划分数据集
from sklearn.model_selection import train_test_split
# 归一化
from sklearn.preprocessing import MinMaxScaler
# 加载数据集
dataset = pd.read_csv("../heart_disease_age.csv")
# 将特征与标签归一化
sc = MinMaxScaler(feature_range=(0, 1))
dataset = sc.fit_transform(dataset)
# 格式转换
dataset = pd.DataFrame(dataset)
# 划分数据集
X = dataset.iloc[:, :-1]
Y = dataset.iloc[:, -1]
# 划分测试集和训练集
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.2,
random_state=123)
# 导入模型
model = keras.models.load_model("./log_2024-02-01-22:54:44/model.h5")
# 推演
pre_value = model.predict(x_test)
# 合并数据
test_data = np.concatenate((x_test, pre_value), axis=1)
# 反归一化
test_data = sc.inverse_transform(test_data)
# 提取标签列
y_pre = test_data[:, -1]评估模型
- 均方根误差(RMSE)
- MAPE
# 计算rmse和mape
from sklearn.metrics import mean_squared_error
print("rmse:", mean_squared_error(y_test, y_pre))
print("mape:", np.mean(np.abs((y_test - y_pre) / y_test)))
# 画出真实值和预测值对比图
import matplotlib.pyplot as plt
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
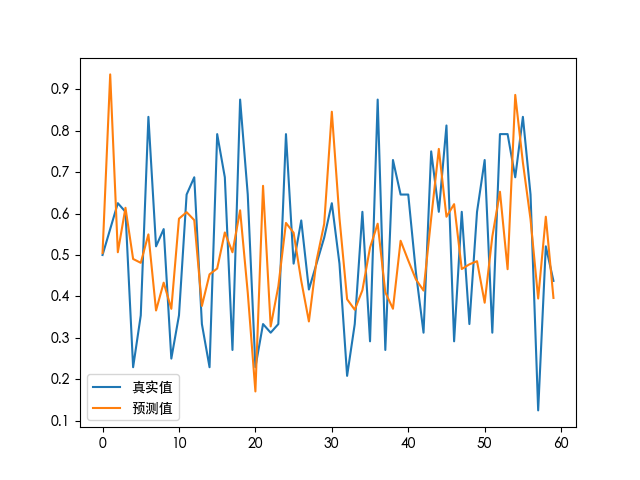
plt.plot(np.array(y_test), label="真实值")
plt.plot(pre_value, label="预测值")
plt.legend()
plt.show()
卷积神经网络
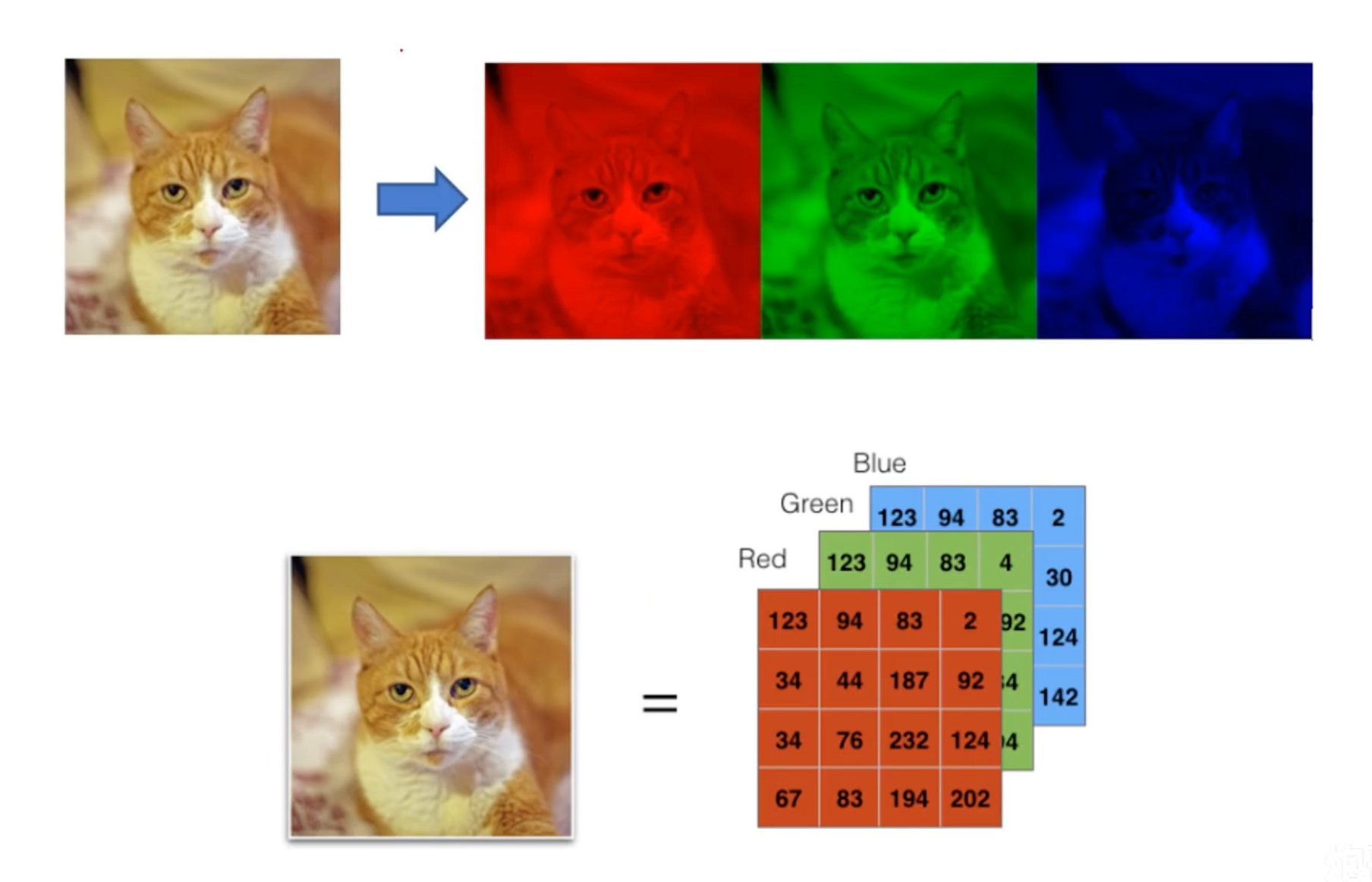
图像的本质
图像是一个或多个数值矩阵(亮度、RGB)
灰度图:一个存有亮度信息的矩阵

彩色图:三个矩阵分别存储RGB色彩信息
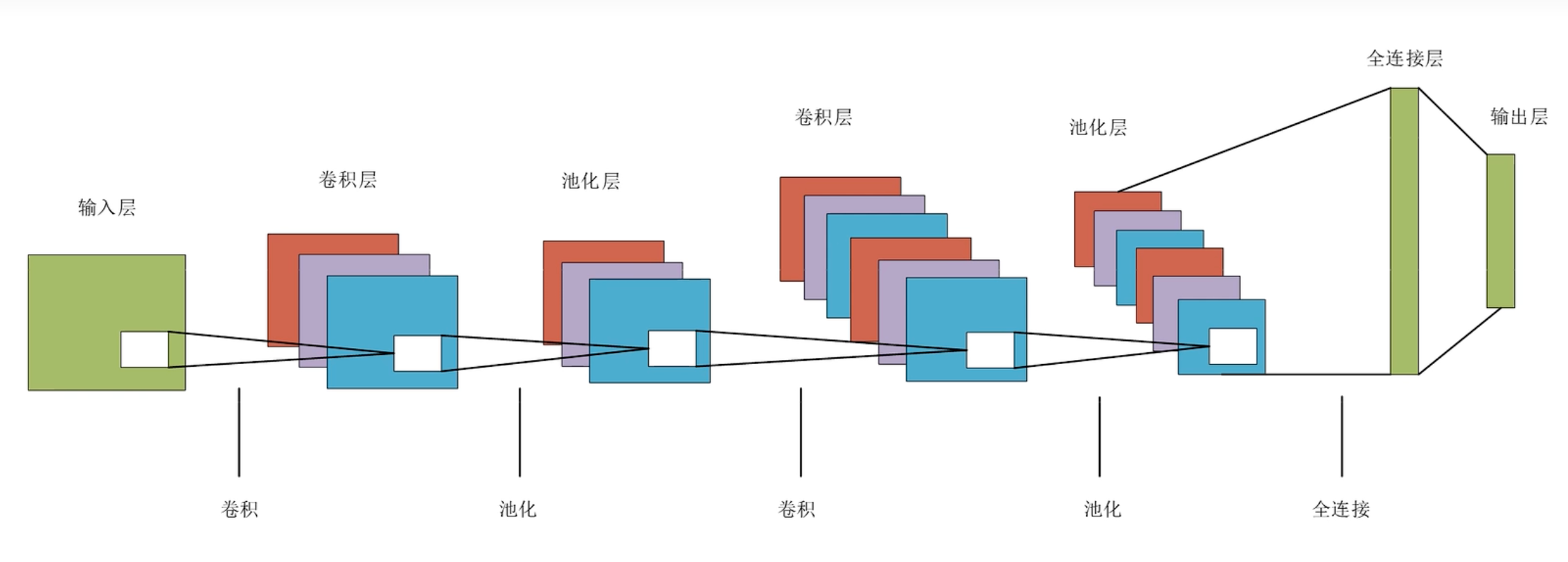
卷积神经网络结构
卷积神经网络结构特征
- 卷积:将单通道变成多通道,修改原始矩阵的大小
- 池化:通道数不变,不一定改变原始矩阵的大小
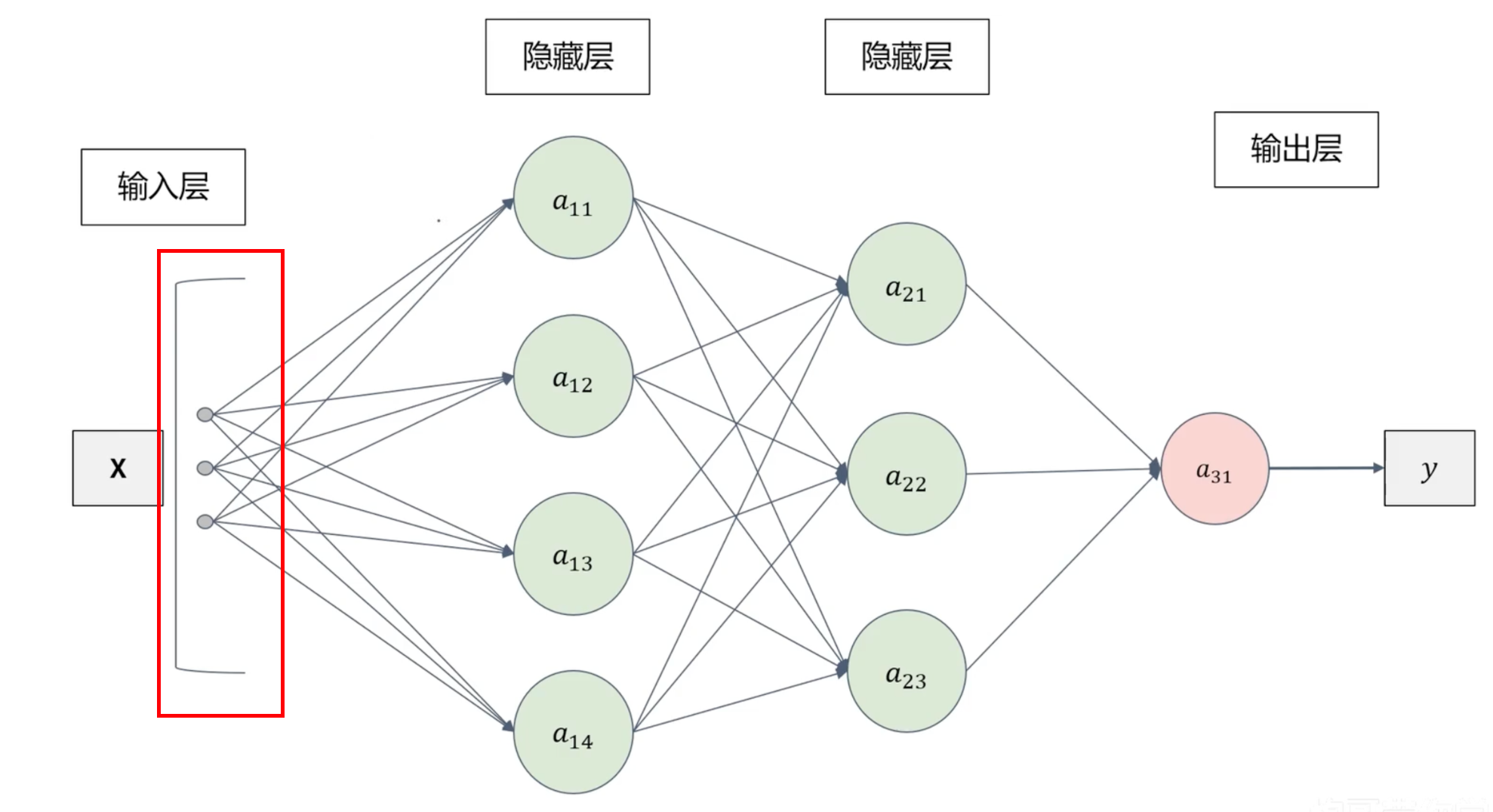
全连接神经网络存在的问题
全连接神经网络的输入必须是线性(条状)的
把图片切割成条状会损失图片的空间信息 → 精度低
卷积神经网络的参数比全连接神经网络参数少,避免过拟合,计算量小。
卷积运算
卷积
- 输入:特征
- 卷积核:权重 w
- 偏置:b
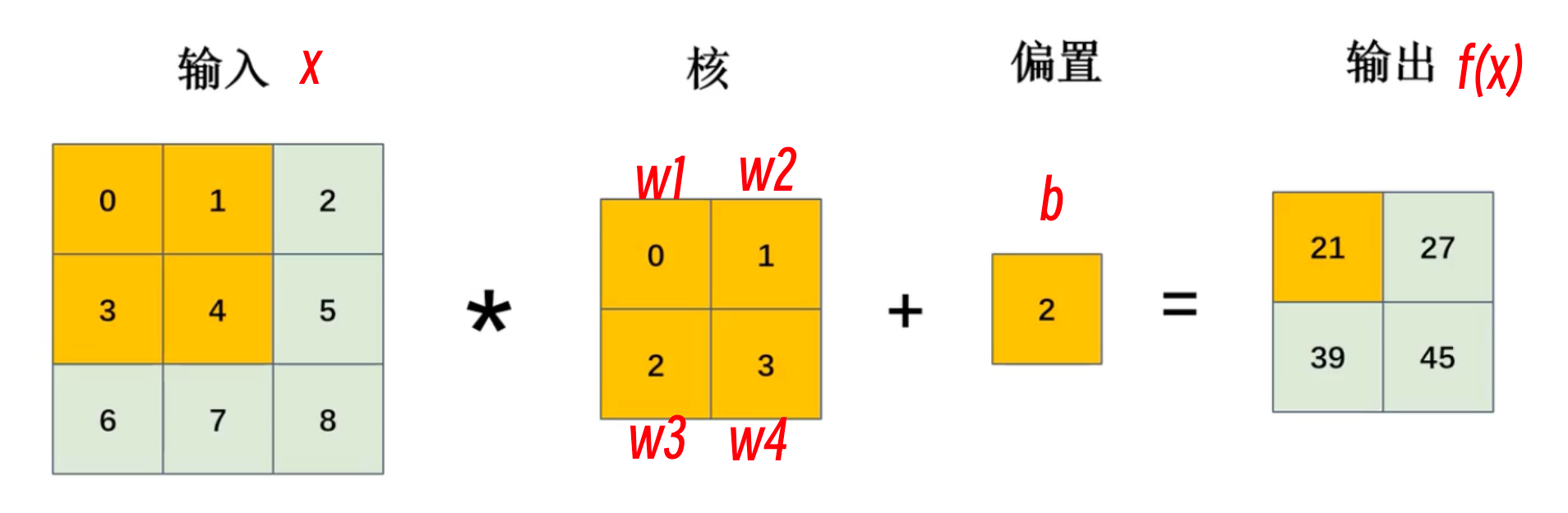
相比于全连接神经网络模型(
权重共享:是指在神经网络中多个部分共享相同权重。
这意味着不同部分的神经元使用相同的权重来进行计算,这样可以减少需要训练的参数数量,节省计算资源,并且有时可以提高模型的泛化能力。
填充
填充:在输入数据周围添加额外的像素值(通常是0),以便在进行卷积运算时能够保持输入和输出的尺寸一致或者满足特定的需求。
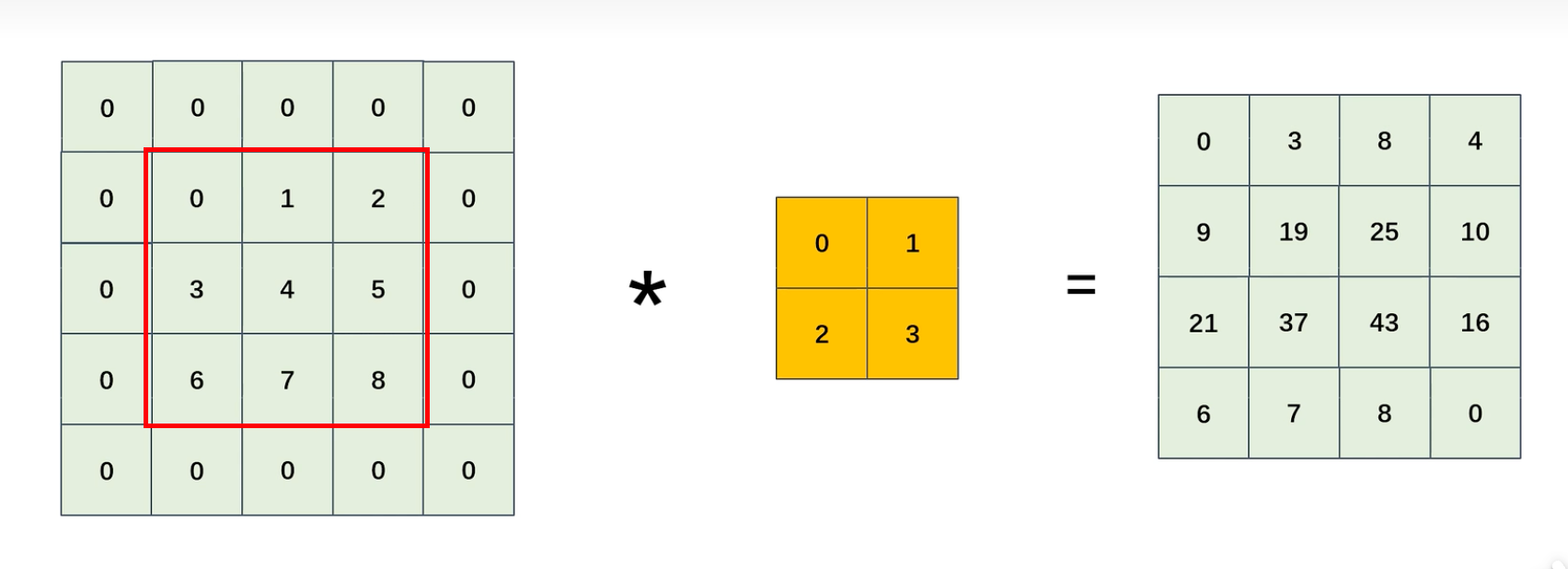
步幅
步幅:指在进行卷积操作时,滑动卷积核的间隔距离。可以想象成在图像上移动卷积核的步长。
如果步幅为1,那么卷积核每次移动一个像素;如果步幅为2,那么卷积核每次移动两个像素。
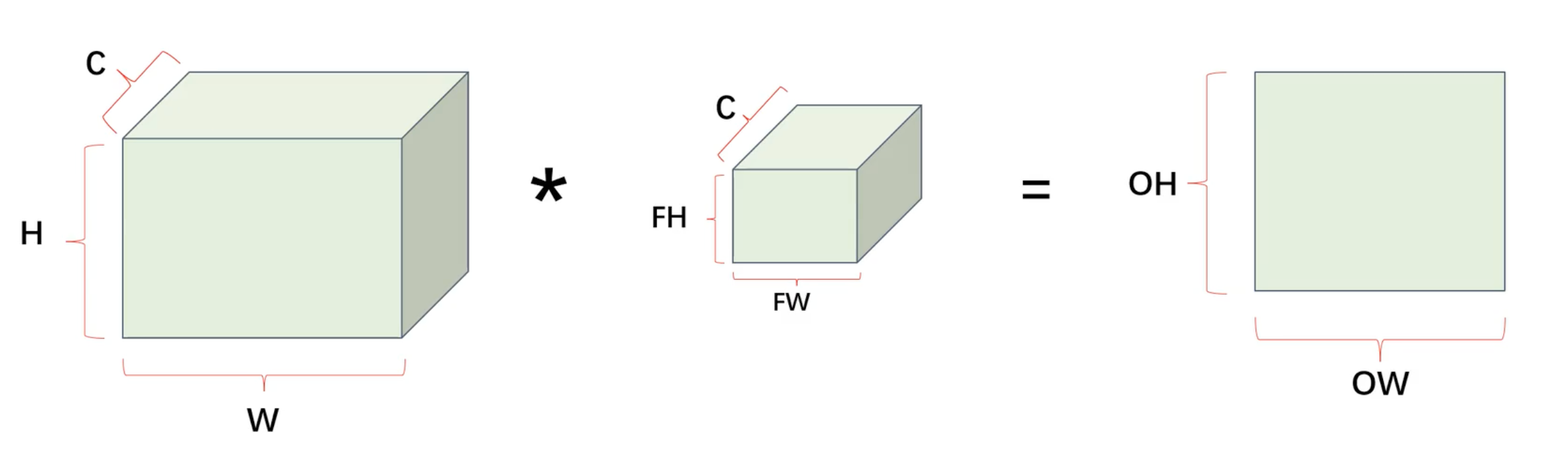
卷积后的特征图大小
- H:特征图的高
- P:填充的范围
- FH:卷积核的高
- S:步幅
- OH:卷积运算后的高
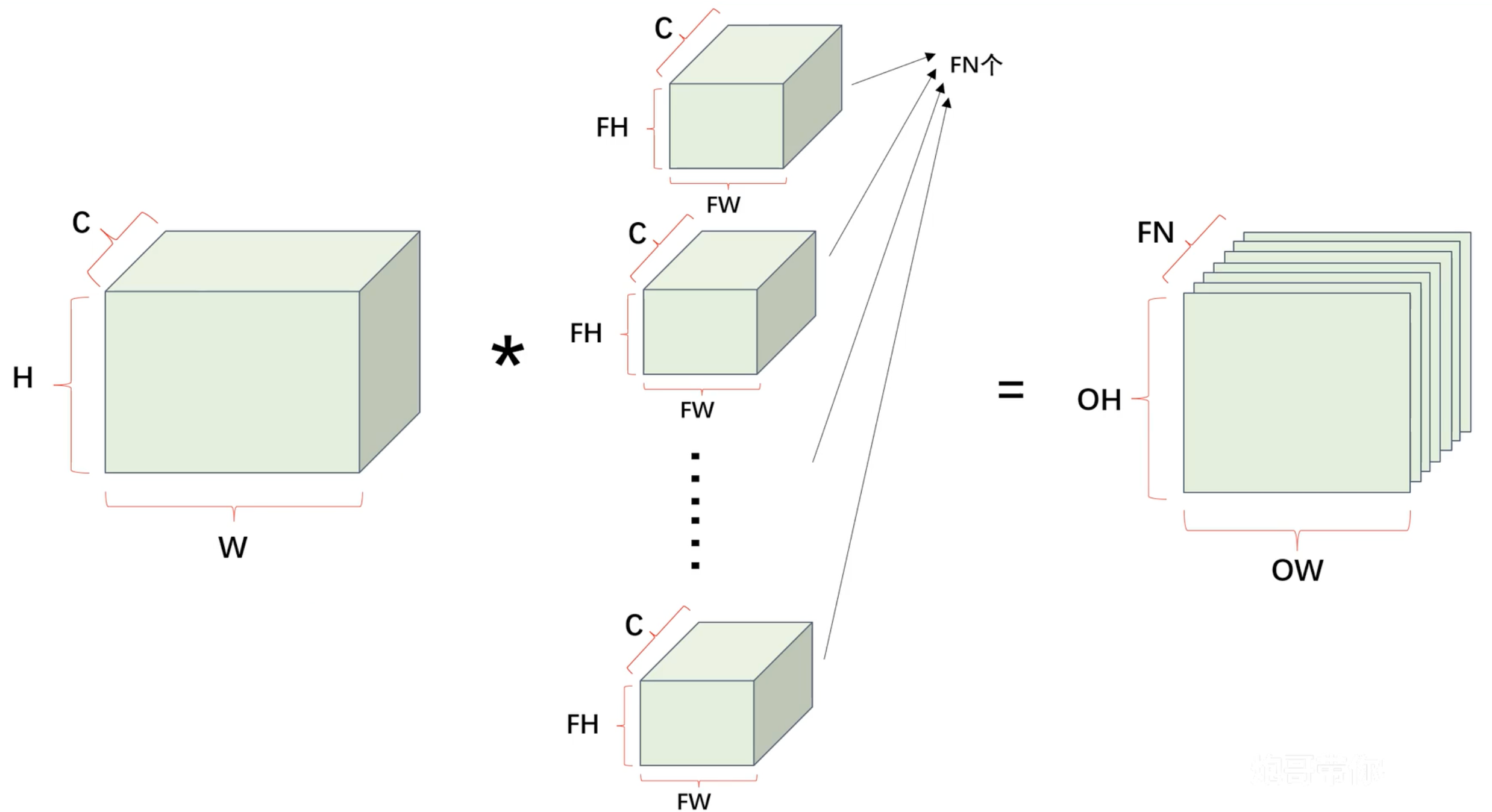
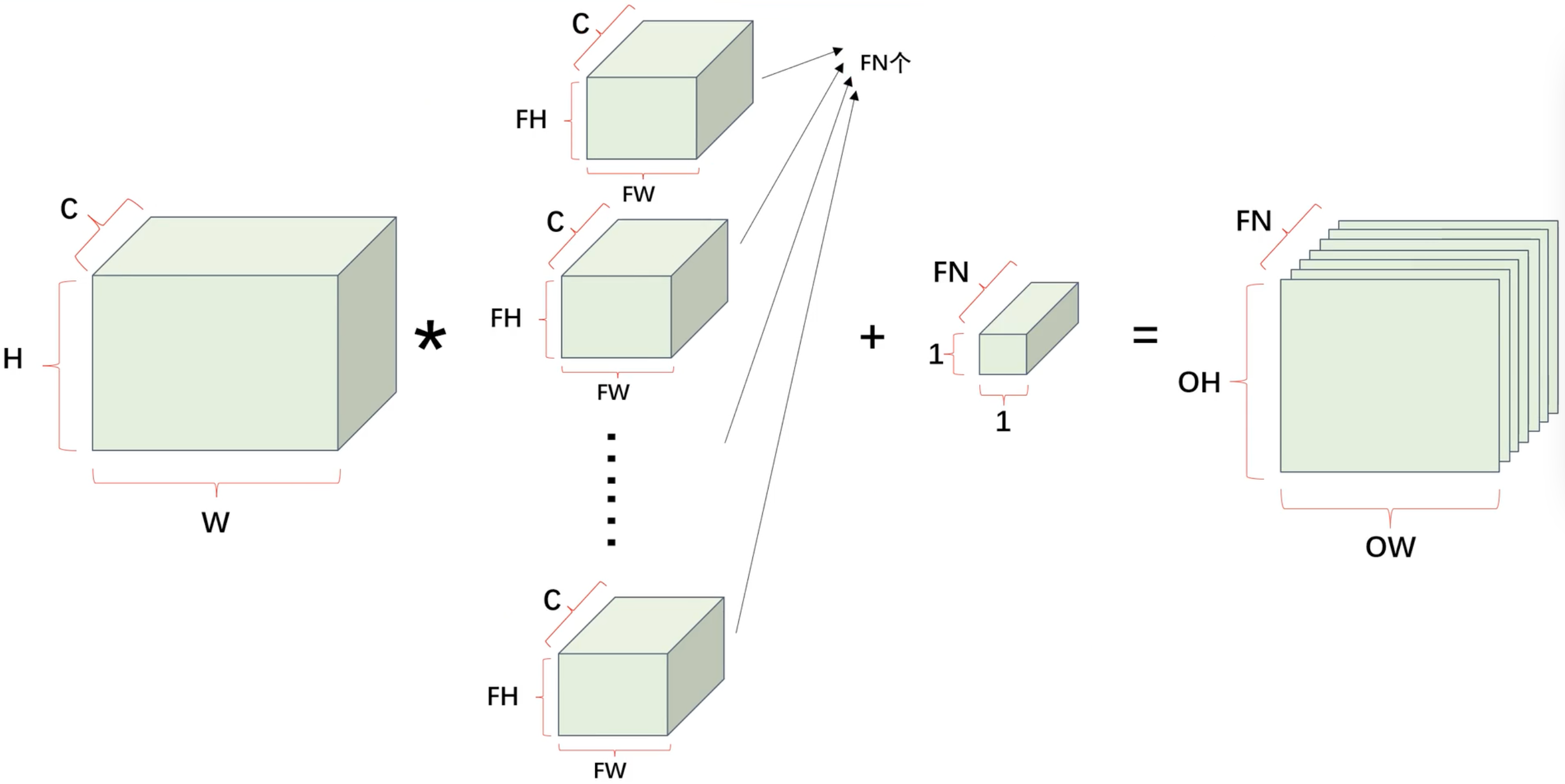
卷积层 - 多通道卷积
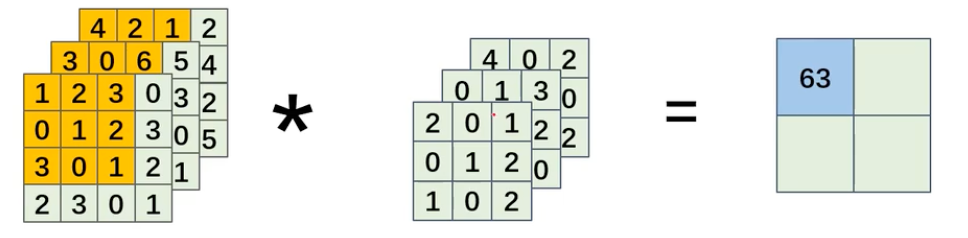
使用立方体表示卷积运算
池化运算
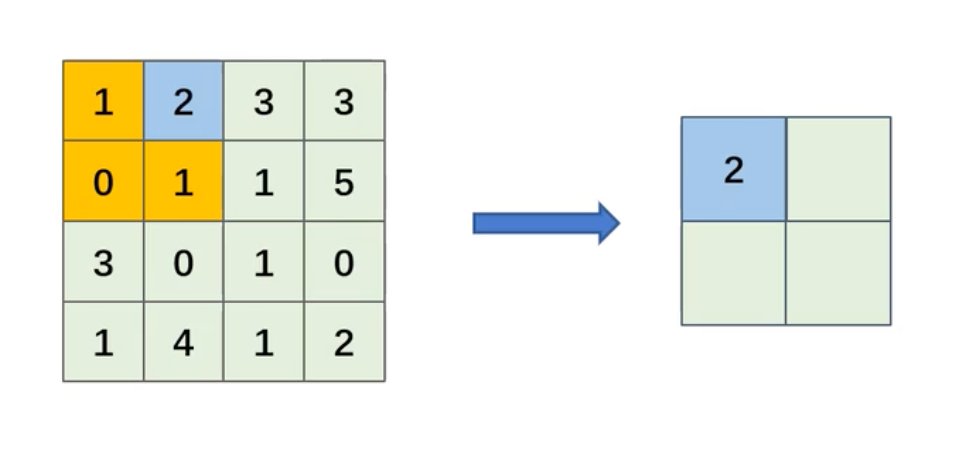
最大池化
- 池化核:每次池化运算的区域大小
- 步伐:滑动池化核的间隔距离
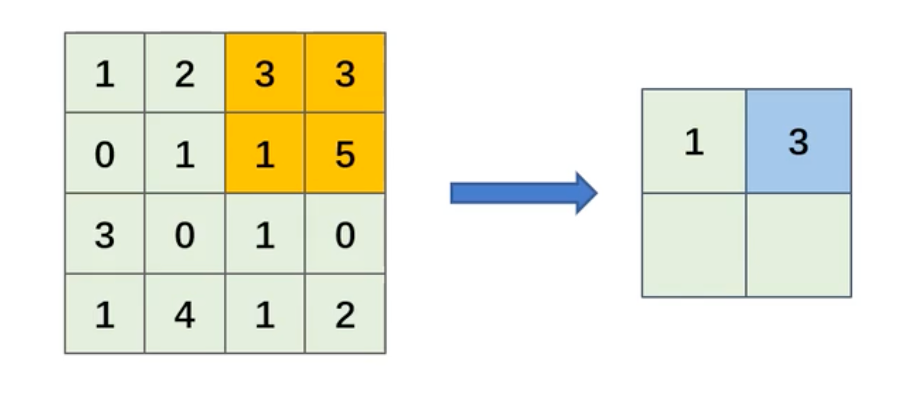
平均池化
池化的优点
输入的数据不仅有长和高,还有通道。但是池化不会对输入特征图的通道进行改变,池化操作是按通道独立进行计算的。
池化层对微小的位置变化具有鲁棒性,使模型更加的健壮。当输入特征数据发现微小的变化的时候,输出的特征图的结果仍然是一样的。

池化后的特征图大小
- H:特征图的高
- P:填充的范围
- FH:池化核的高
- S:步幅
- OH:池化运算后的高
LENET实现
LENET模型介绍
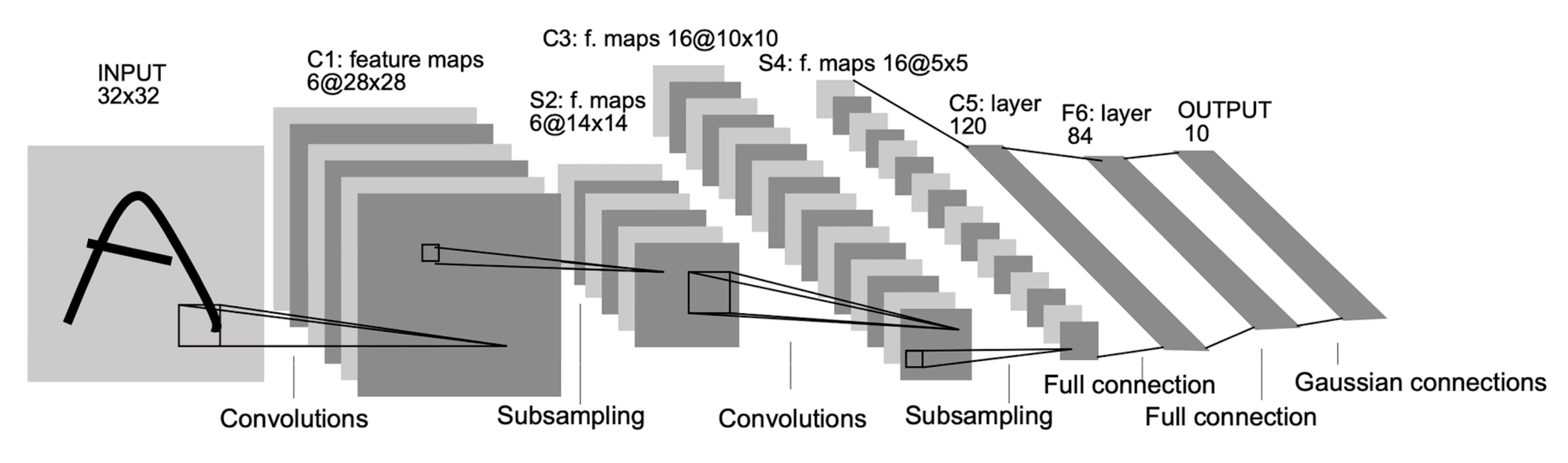
- 卷积核:5*5,步幅:1,填充:0
- 池化核:2*2,步幅:2,填充:0
模型训练
import os
from datetime import datetime
import numpy as np
import pandas as pd
import pathlib
import matplotlib.pyplot as plt
import keras
from keras.layers import Dense, Flatten, Conv2D, MaxPool2D
# 解决中文显示问题
plt.rcParams['font.sans-serif'] = ['Heiti TC']
plt.rcParams['axes.unicode_minus'] = False
# 读数数据
train_data = pathlib.Path('./data/train')
test_data = pathlib.Path('./data/test')
# 给数据类别放置到列表
label = np.array(['0', '1', '2'])
# 把图片设置成 32*32
img_size = 32
batch_size = 16
# 数据归一化生成器
img_generator = keras.preprocessing.image.ImageDataGenerator(rescale=1.0 / 255)
# 生成训练数据
train_data_gen = img_generator.flow_from_directory(
directory=train_data,
batch_size=16,
shuffle=True,
target_size=(img_size, img_size),
classes=list(label)
)
test_data_gen = img_generator.flow_from_directory(
directory=test_data,
batch_size=16,
shuffle=True,
target_size=(img_size, img_size),
classes=list(label)
)
# 使用Keras搭建CNN模型
model = keras.Sequential([
# 卷积层
# filters: 卷积核数量
# kernel_size: 卷积核尺寸
Conv2D(filters=6, kernel_size=5, input_shape=(32, 32, 3), activation='relu'),
# 池化层
# pool_size: 池化窗口尺寸
# strides: 步长
MaxPool2D(pool_size=(2, 2), strides=2),
# 卷积层
Conv2D(filters=16, kernel_size=5, activation='relu'),
# 池化层
MaxPool2D(pool_size=(2, 2), strides=2),
# 平展层
Flatten(),
# 全连接层
Dense(84, activation='relu'),
Dense(3, activation='softmax')
])
model.compile(loss="categorical_crossentropy", optimizer="Adam", metrics=["accuracy"])
his = model.fit(train_data_gen, epochs=40, validation_data=test_data_gen)
# 保存模型
timestamp = datetime.now().strftime('%Y-%m-%d-%H:%M:%S')
os.makedirs(f"./log_{timestamp}")
model.save(f"./log_{timestamp}/model.h5")
# loss对比图
plt.plot(his.history['loss'], 'b', label='训练集损失')
plt.plot(his.history['val_loss'], 'r', label='验证集损失')
plt.legend()
plt.savefig(f"./log_{timestamp}/loss.png")
plt.show()
# 准确率对比图
plt.plot(his.history['accuracy'], 'b', label='训练集准确率')
plt.plot(his.history['val_accuracy'], 'r', label='验证集准确率')
plt.legend()
plt.savefig(f"./log_{timestamp}/accuracy.png")
plt.show()模型预测
tf.expand_dims 用于在输入数据的最前面添加一个维度,将原本的 3 维数据(长、宽、通道)扩充为 4 维数据(批大小、长、宽、通道)。
因为大部分深度学习模型的输入数据都是以批量的形式进行处理的,即使你只有一张图像作为输入,也需要将其扩充为一个大小为 1 的批量。
import tensorflow as tf
import cv2
import keras
import numpy as np
# 给数据类别放置到列表
label = np.array(['0', '1', '2'])
img_size = 32
# 导入模型
model = keras.models.load_model("./log_2024-02-02-12:24:42/model.h5")
# 数据预处理
src = cv2.imread("./data/test/0/43.jpg")
scr = cv2.resize(src, (img_size, img_size)).astype("int32")
scr = scr / 255
# 扩充数据维度:添加一个batch_size维度
test_img = tf.expand_dims(scr, 0)
# 模型预测
pre_val = model.predict(test_img)
score = pre_val[0]
print(f"预测值:{label[np.argmax(score)]}")
print(f"预测概率:{np.max(score) * 100}")循环神经网络
RNN模型
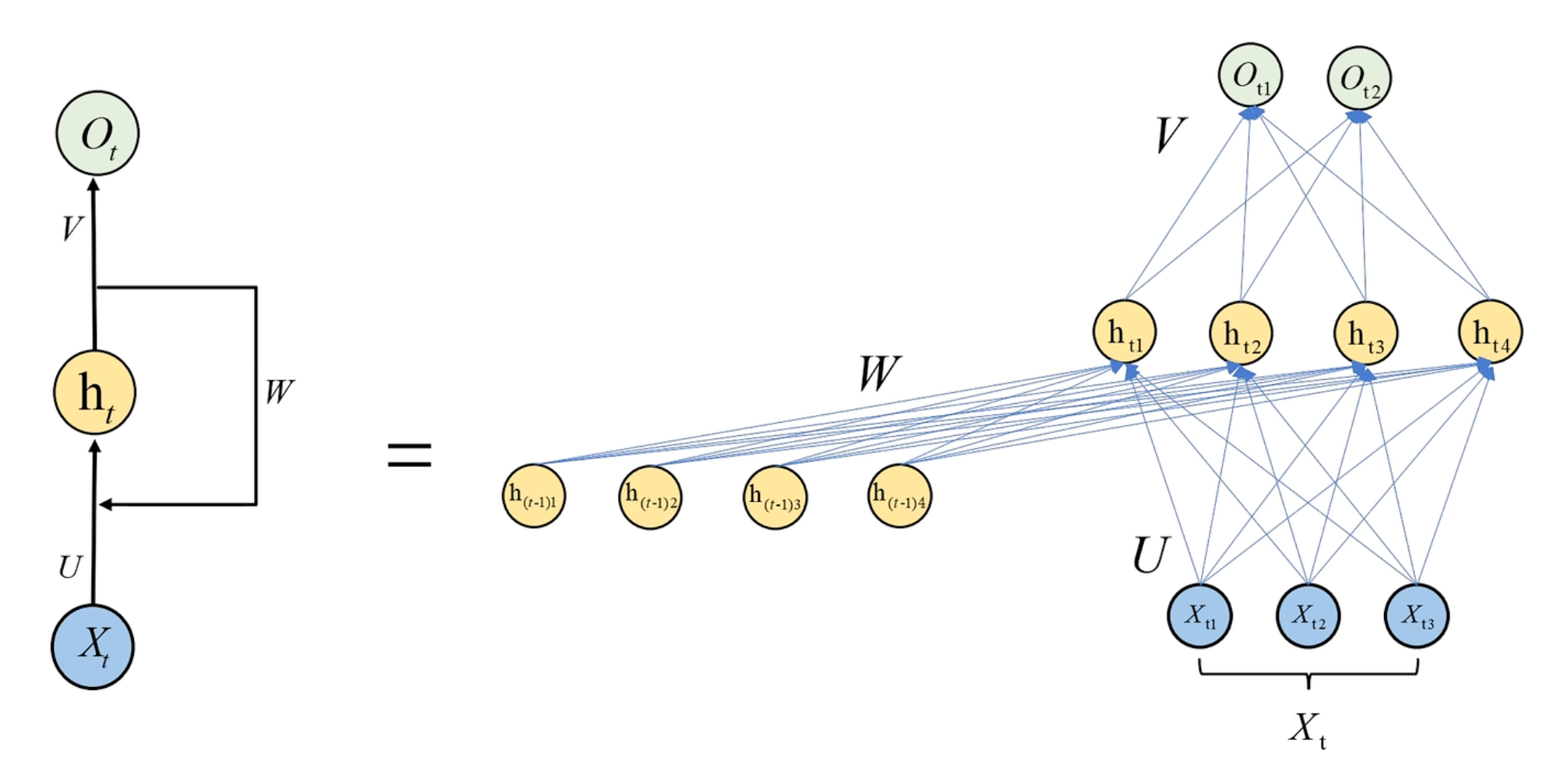
RNN基本结构
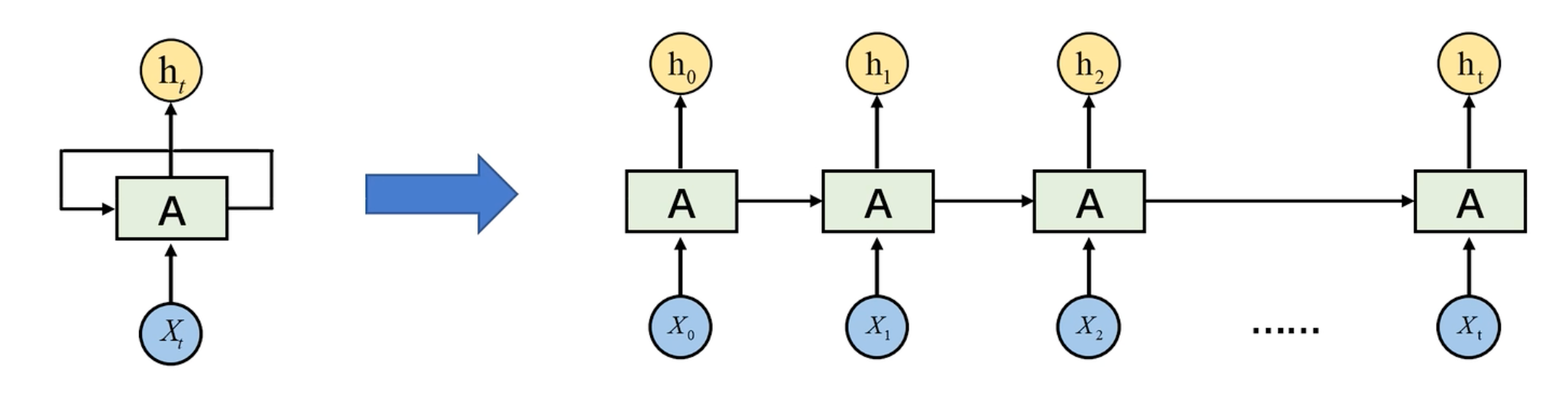
是隐藏层。
输入数据是有顺序的,比如输入一句话,是存在先后关系的。前一层的输出作为下一层的输入,可以保存数据的时间步特征(上下文信息)。
它接受一个输入(比如一个词),并输出一个结果(比如对应的词的预测)。在这个过程中,RNN 会记住之前的输入信息,并将其与当前的输入一起使用来产生输出。这种记忆和信息传递的机制使得 RNN 能够处理序列数据,并且能够考虑到上下文信息。
类比在阅读一本小说,一次读一句。每当你阅读下一句时,你会根据前面句子的内容来理解当前句子的意思。这种理解是基于你之前读过的内容,并且会影响你对后面内容的理解。在这个过程中,你会不断地更新你对故事的理解,并且将之前的信息与新信息结合起来。
RNN与全连接的区别:
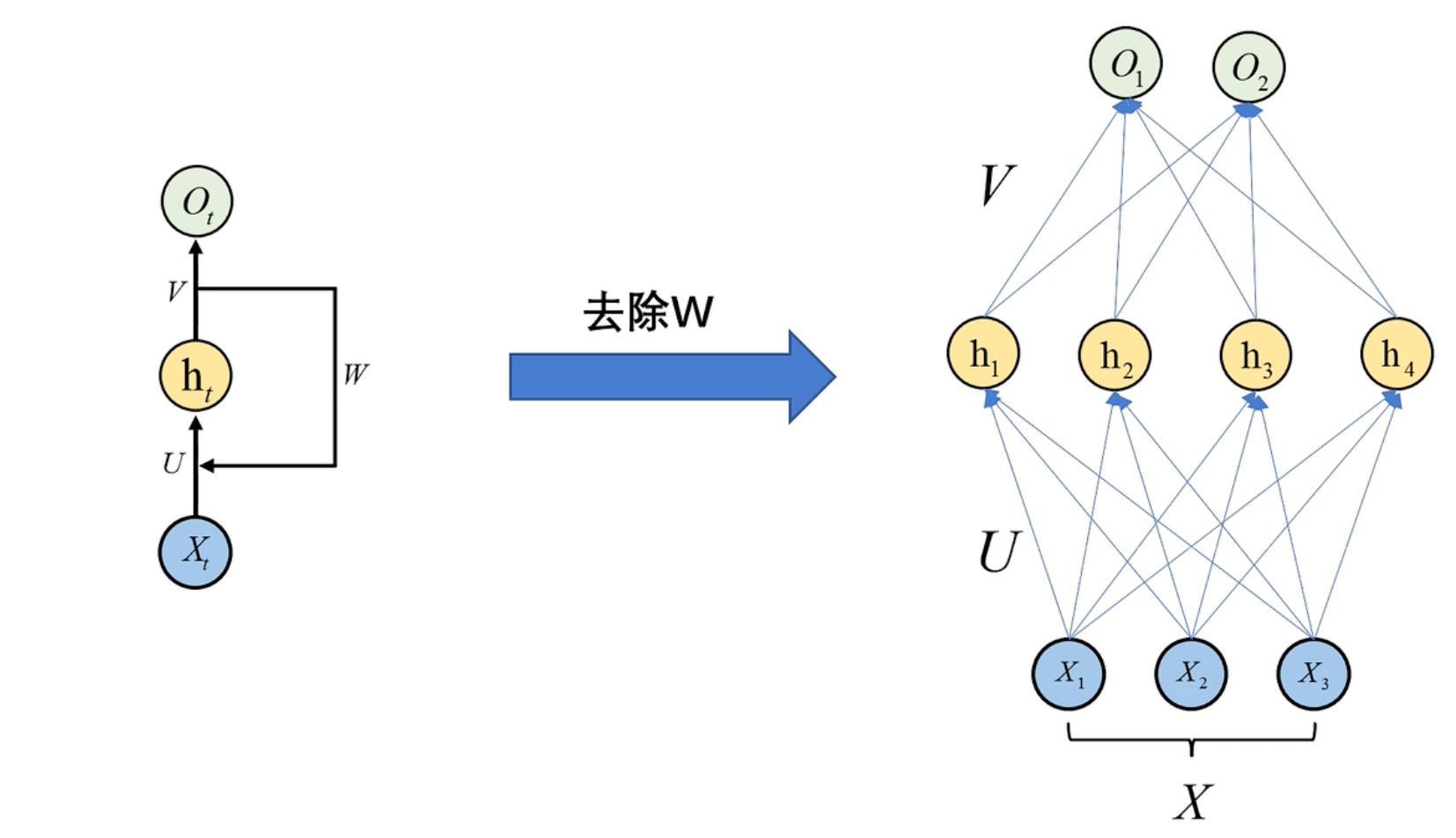
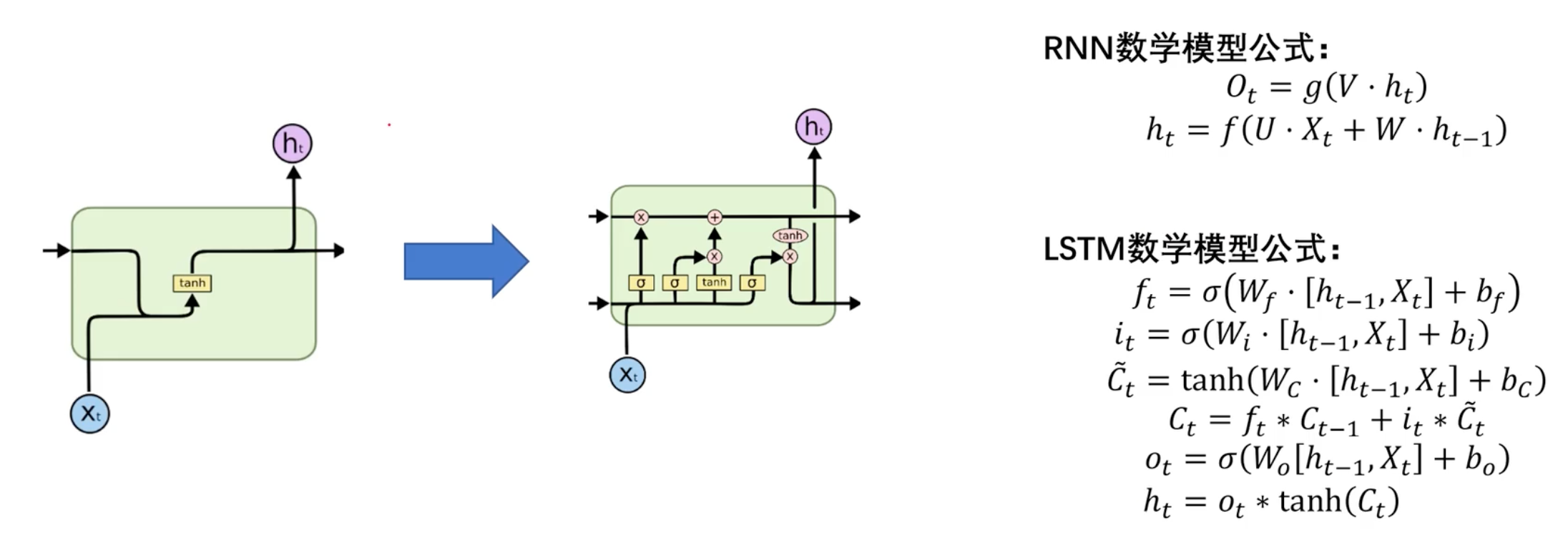
RNN数学模型
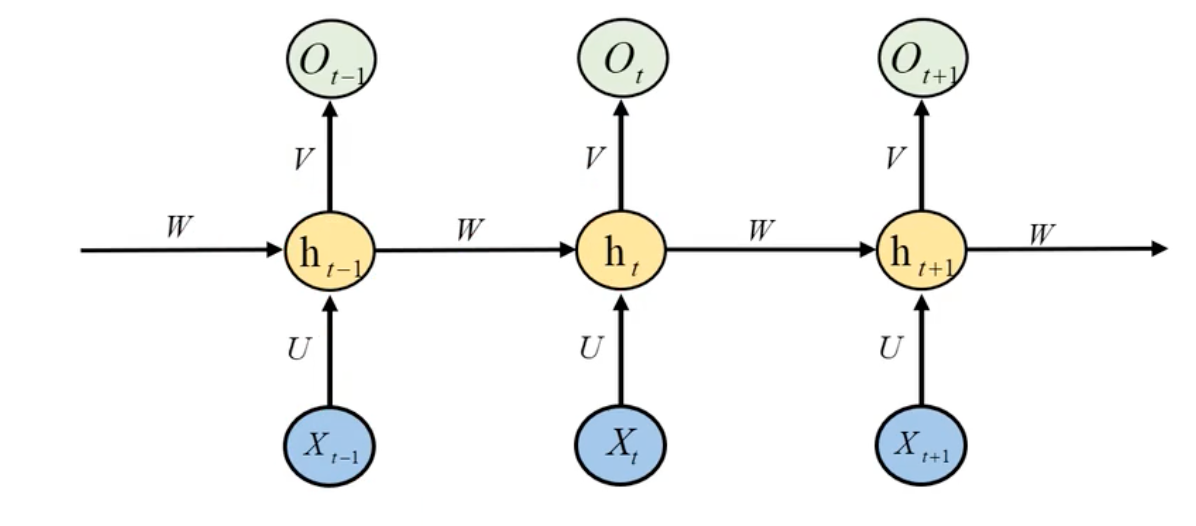
输出层:
隐藏层:
权重共享:W、V、U参数只有一个(参数过多容易造成过拟合)
RNN案例
前向传播
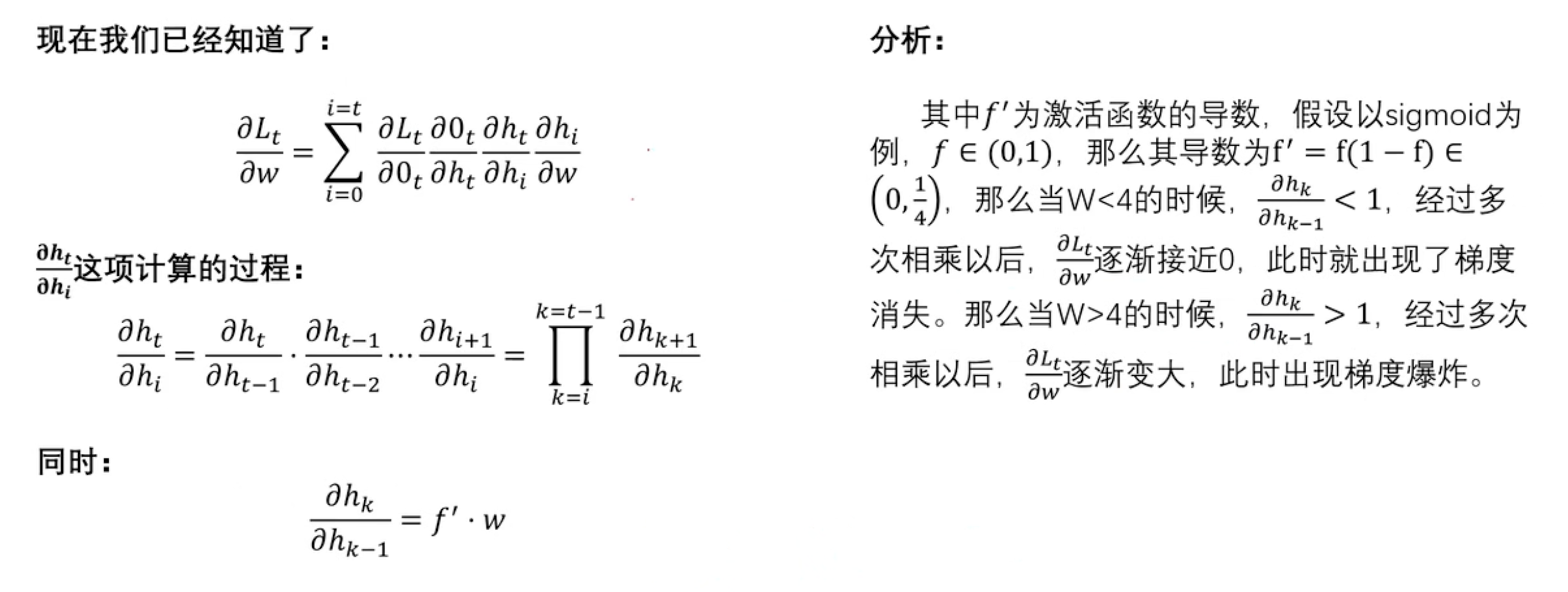
RNN会导致梯度消失(梯度为0)和梯度爆炸(梯度为∞)的问题 → LSTM

第一个时间步:
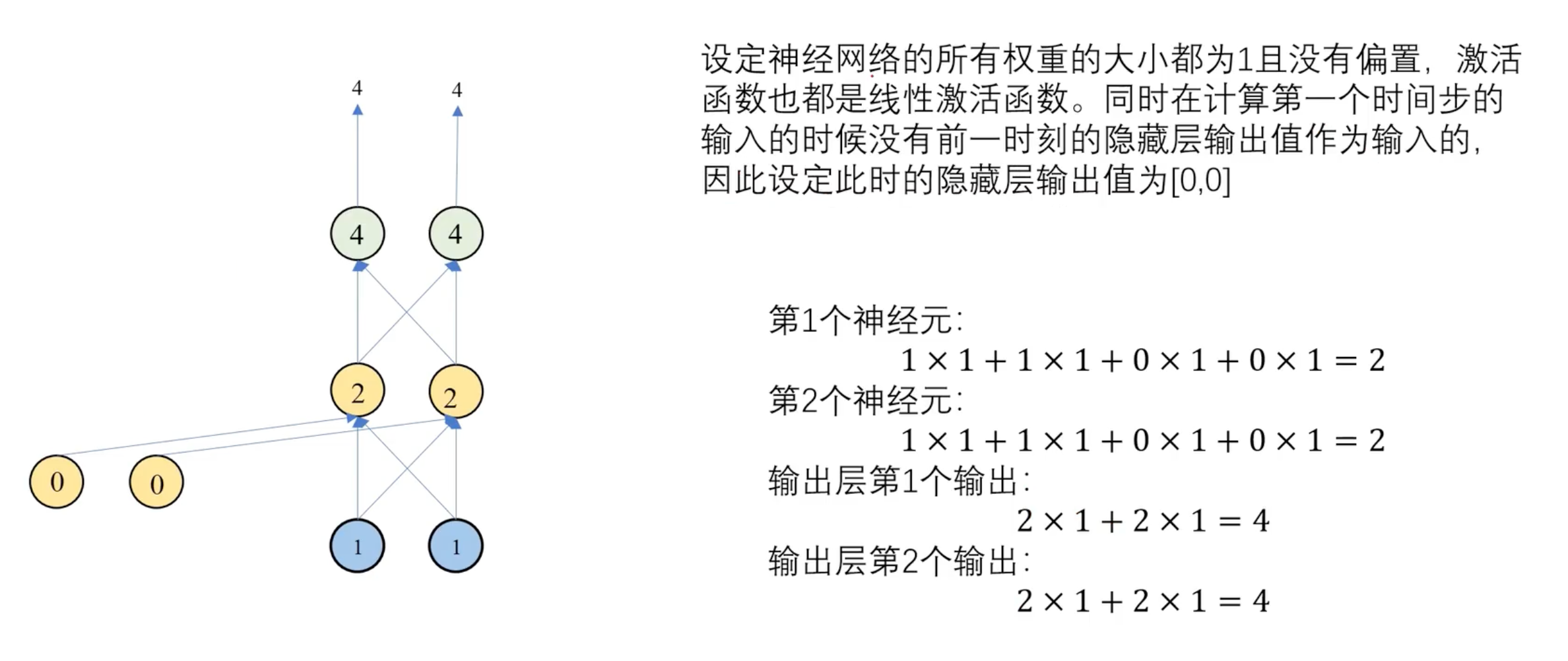
第二个时间步:
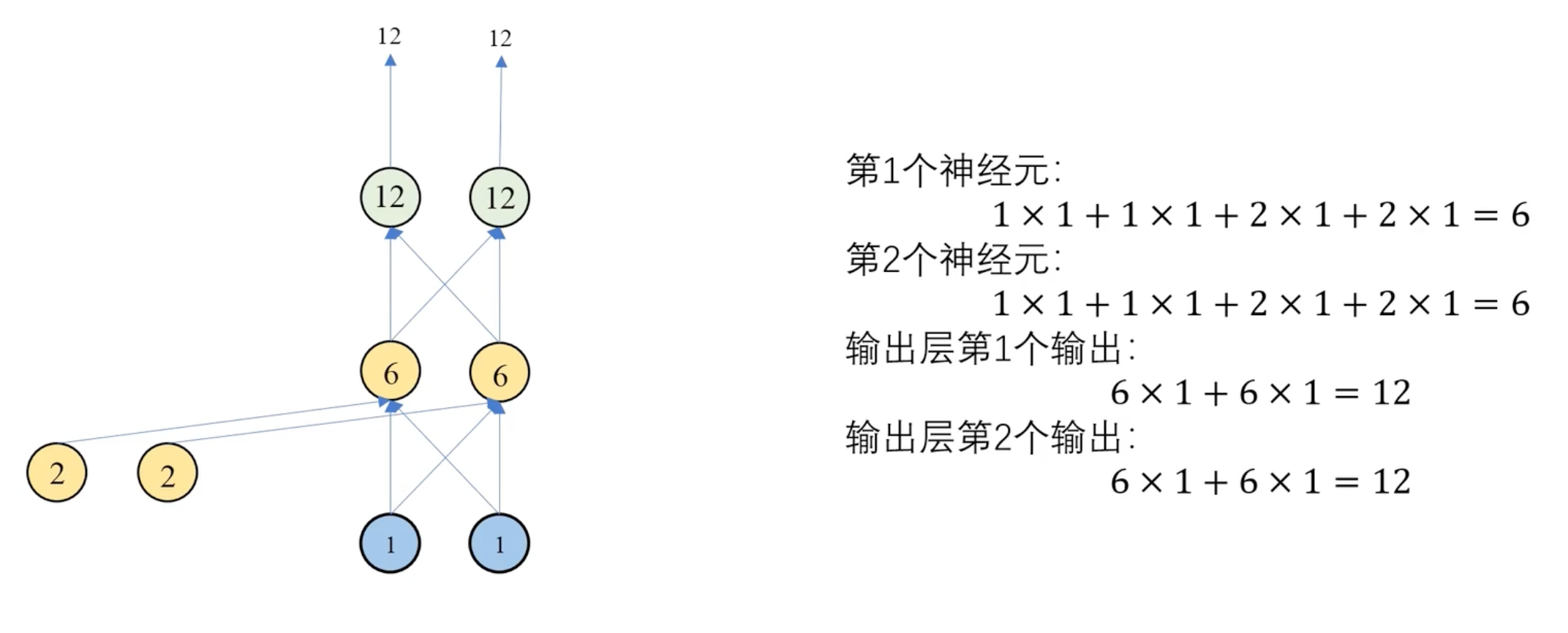
第三个时间步:
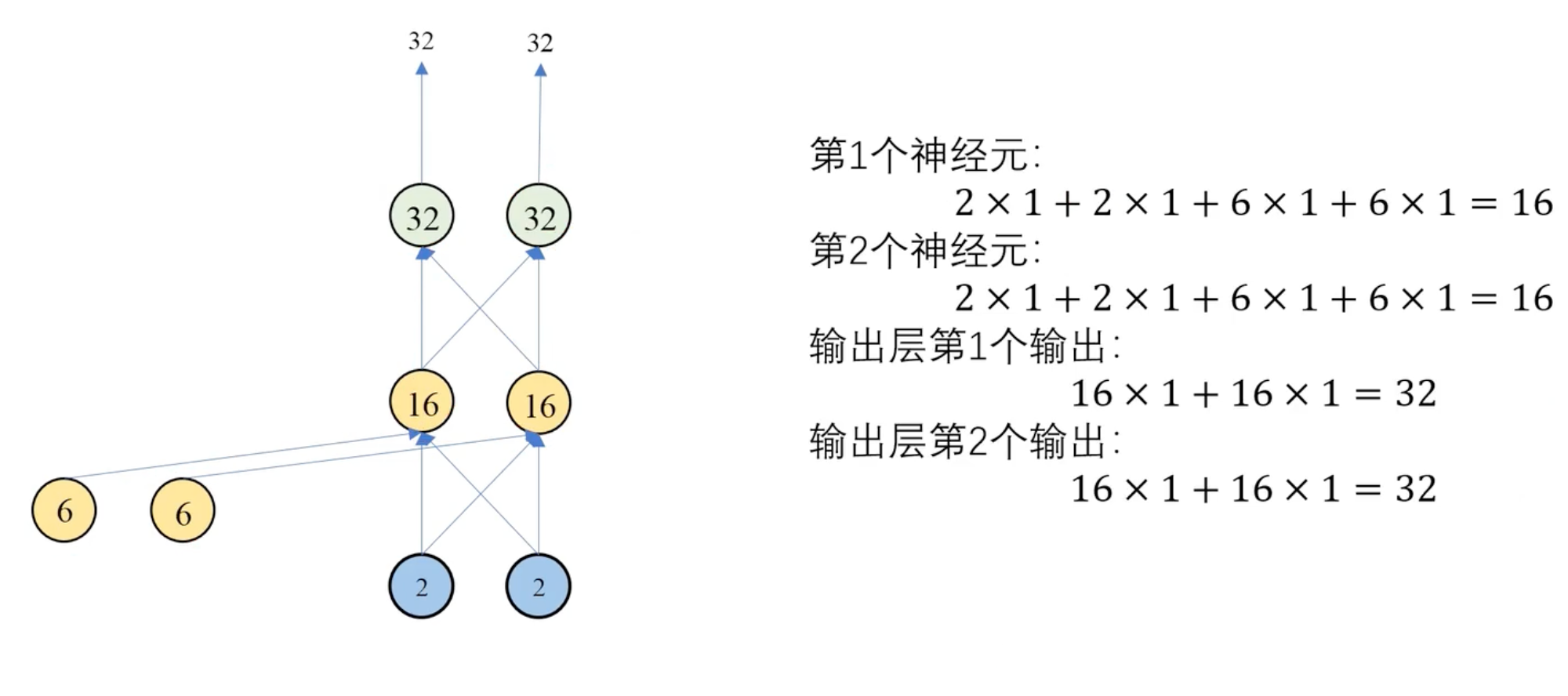
反向传播
时间反向传播算法(BPTT):需要求解所有时间步的梯度之后,利用多变量链式求导法则求导求解梯度。
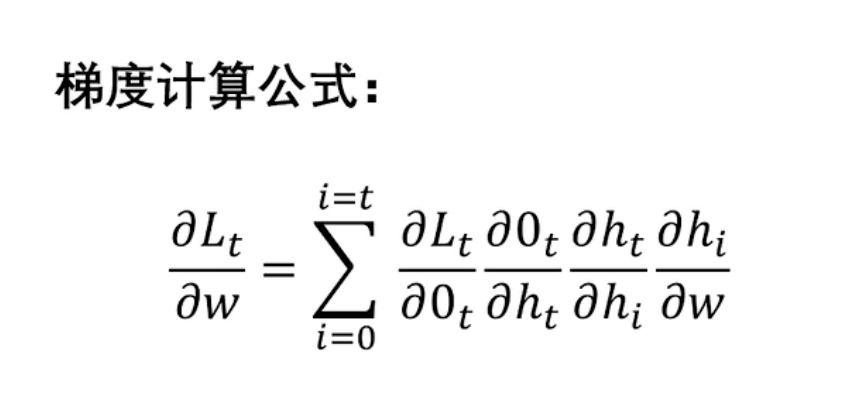

在RNN中,梯度消失通常是由于网络的时间步数较大,导致梯度在时间上反复相乘并逐渐减小。当RNN尝试学习长期依赖关系时,梯度消失会导致网络难以有效地传播远距离的依赖信息,从而影响网络的性能。
优化 → 长短时记忆网络(LSTM):通过引入门控机制,能够更好地控制梯度的流动,从而缓解了梯度消失的问题,使得网络能够更好地学习长期依赖关系。能学习到更长久时间步的信息。
LSTM模型
LSTM与RNN对比
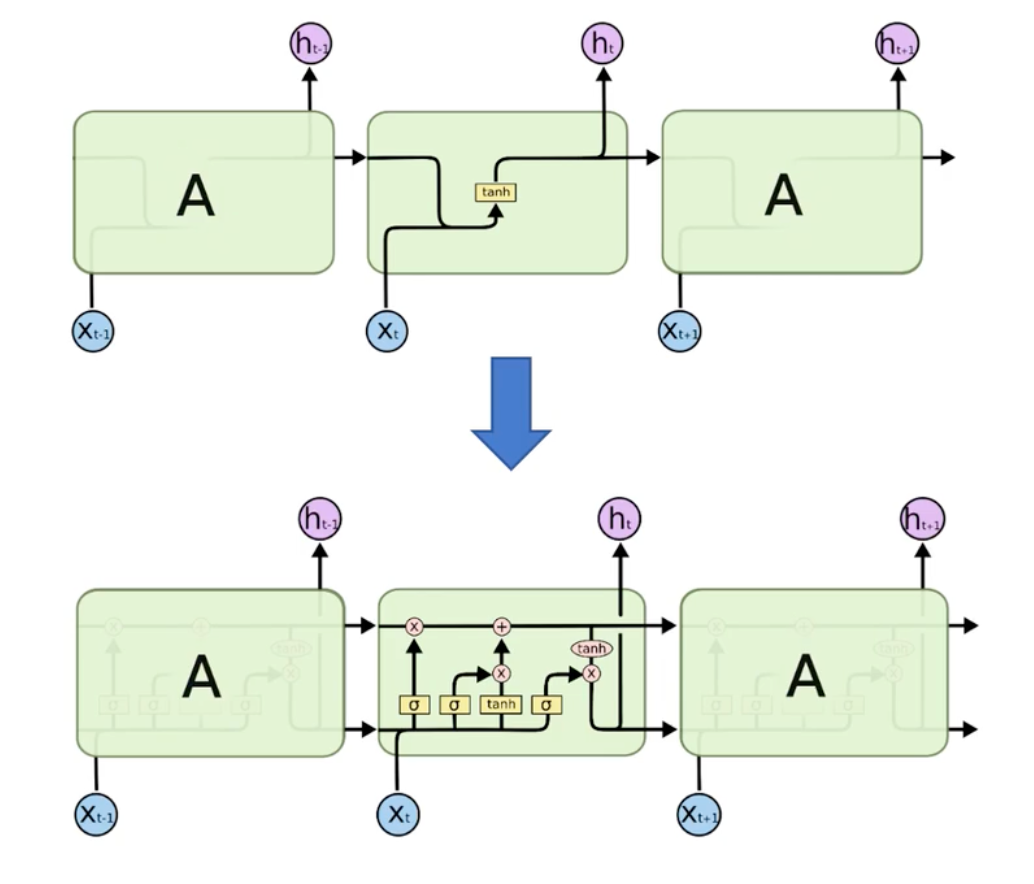
LSTM基本结构
- x:输入(短期记忆)
- y:输出
- c:细胞状态(长期记忆)
- s:隐藏层

LSTM门结构
遗忘门
决定从细胞状态中丢弃什么信息。遗忘们门会读取上一个输出和当前输入,做一个sigmoid的非线性映射,然后输出一个值域为0~1的向量,这个向量和细胞状态相乘,保留有用的信息。
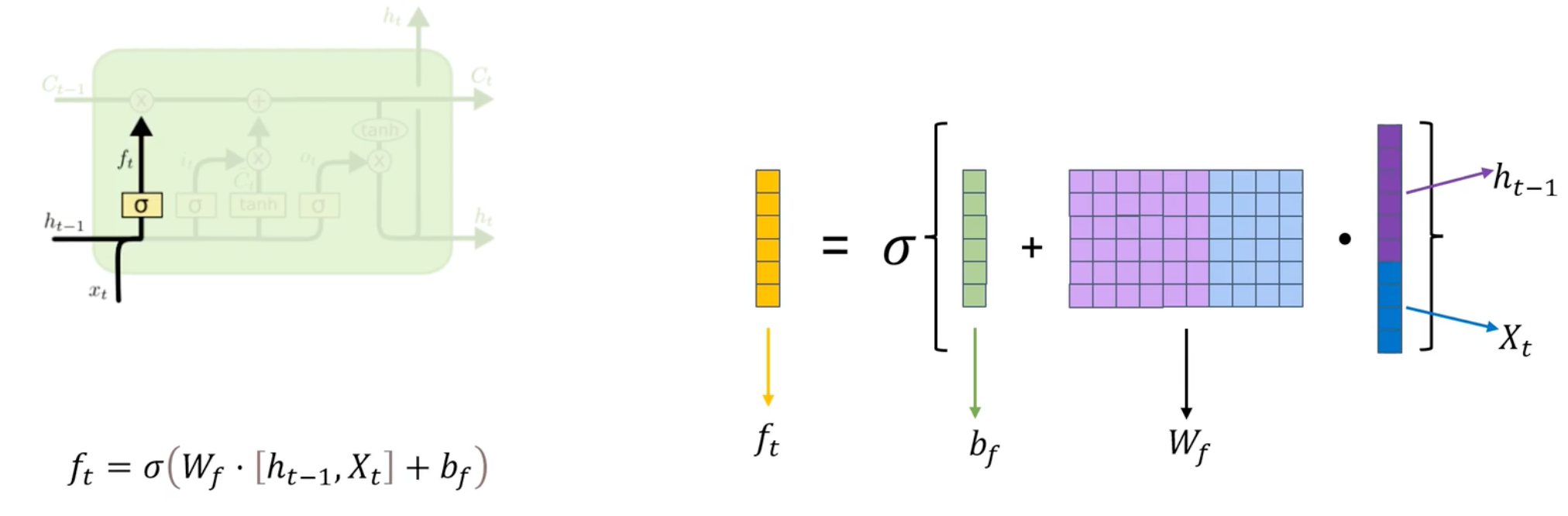
输入门
输入门决定了要从新的候选值中添加哪些信息到细胞状态中。它通过考虑当前输入和前一个时间步的隐藏状态来输出一个介于0和1之间的值,表示要保留多少新信息。可以学习新的信息并更新细胞状态。
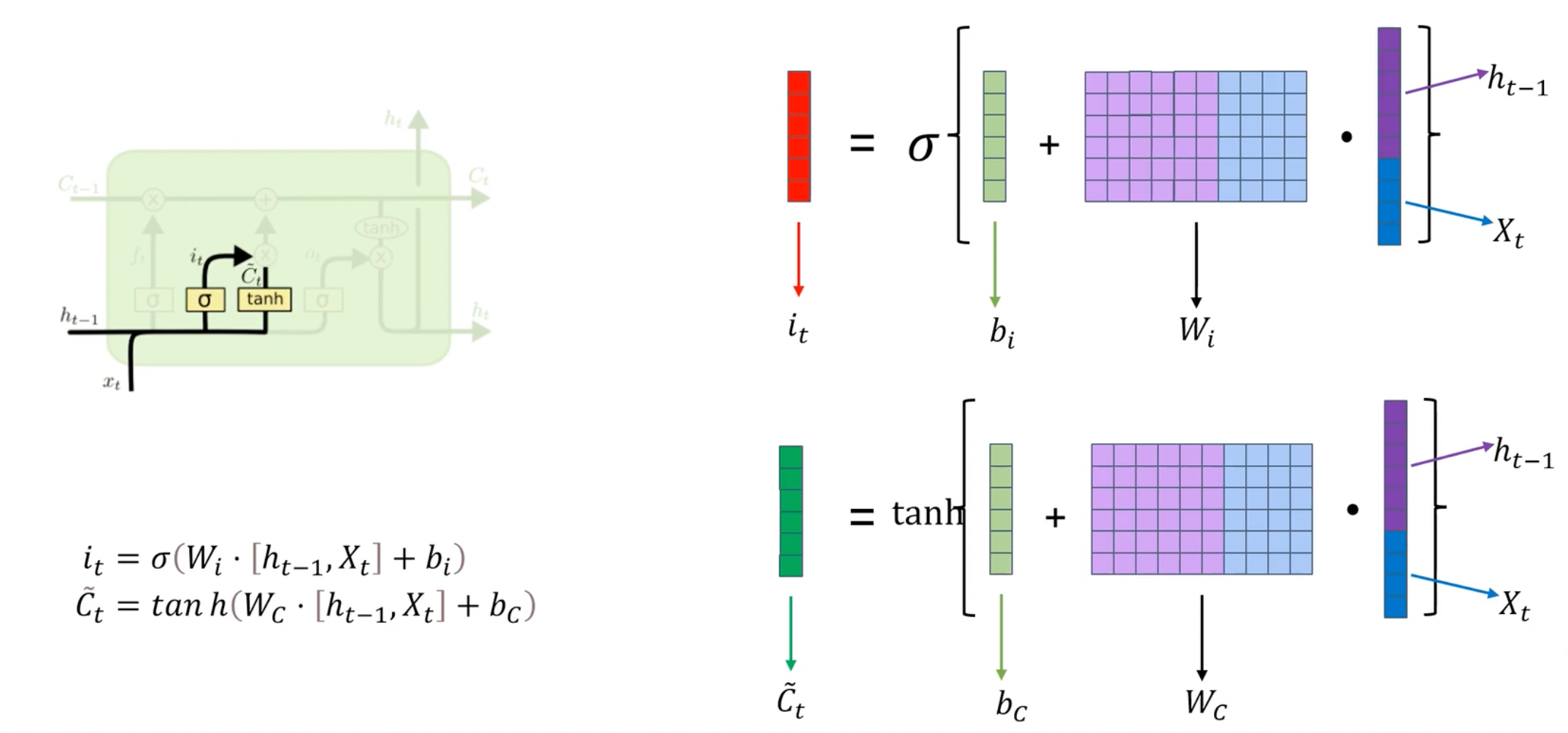
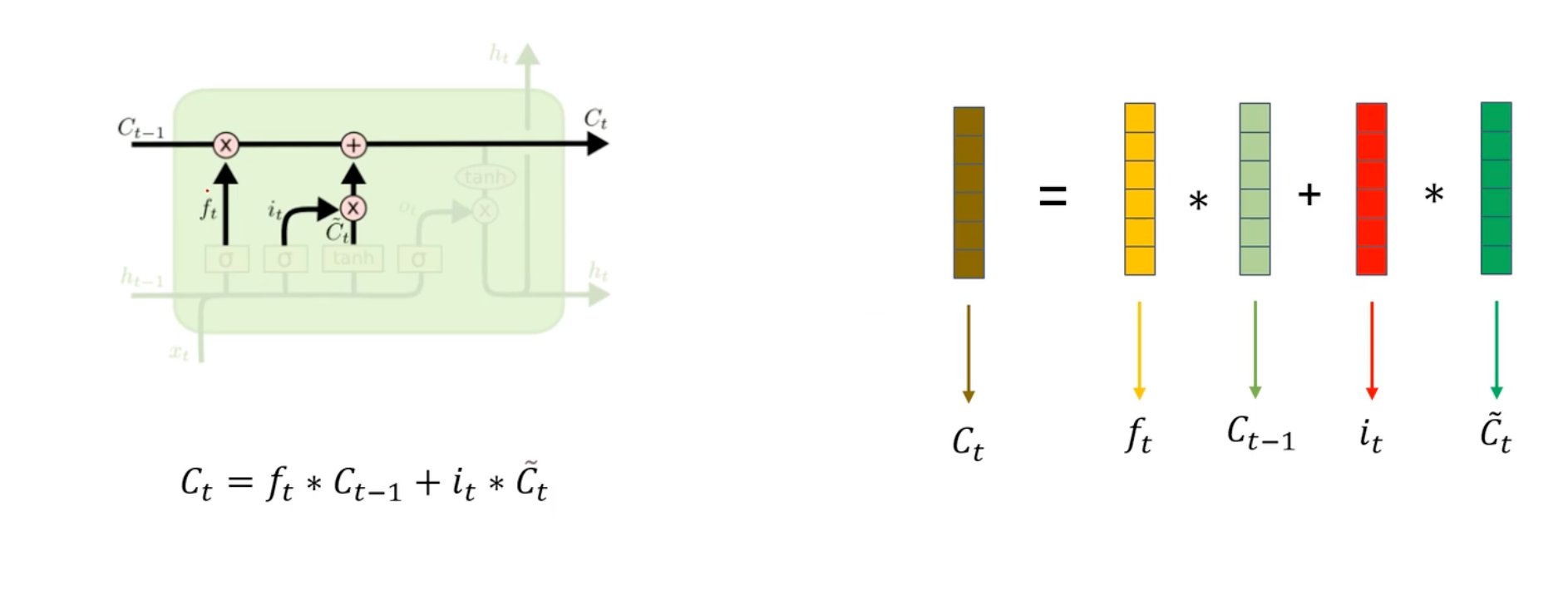
更新细胞状态
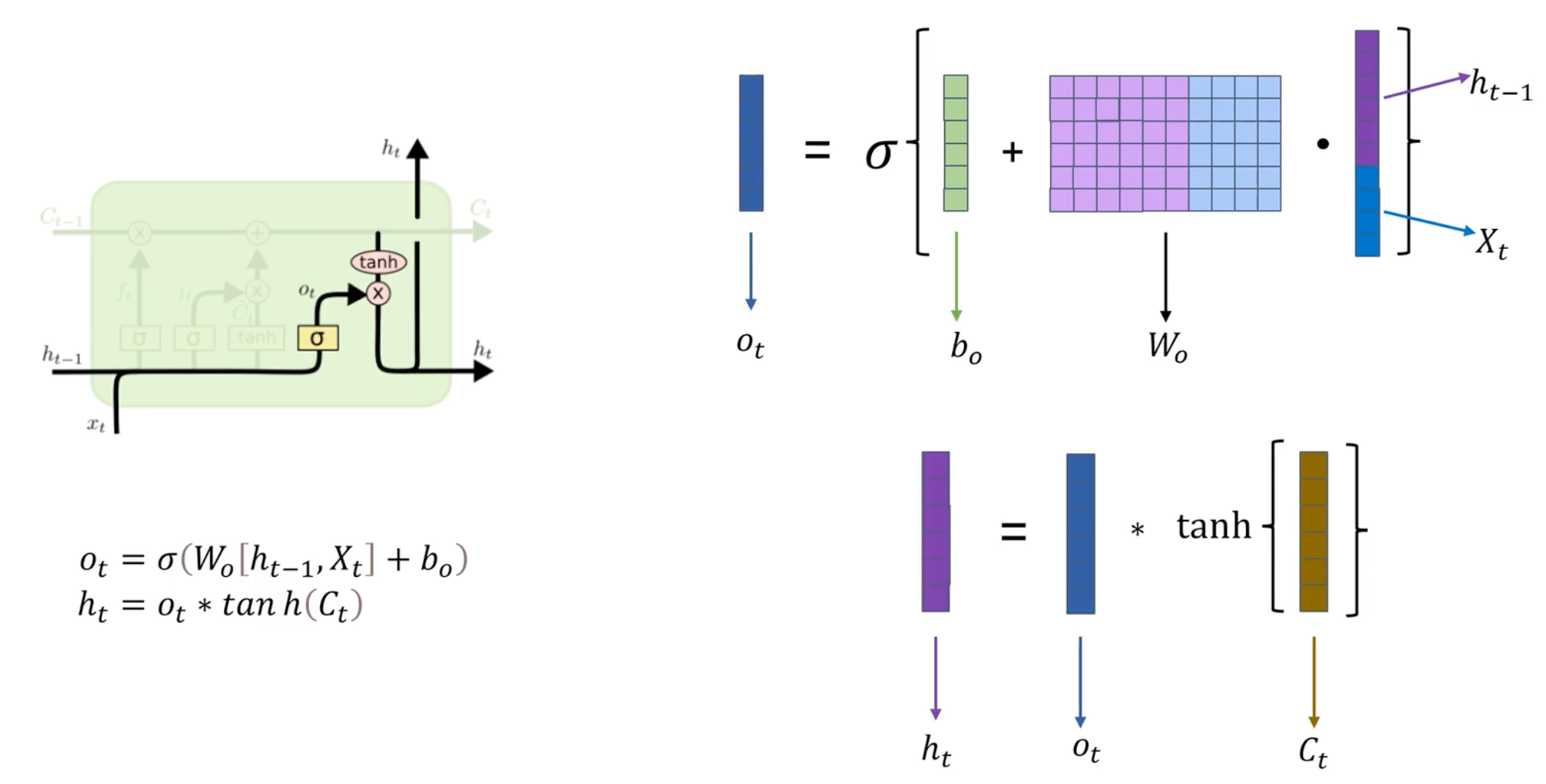
输出门
输出门决定了基于当前输入和隐藏状态应该输出什么。它通过综合考虑当前输入和前一个时间步的隐藏状态来输出一个介于0和1之间的向量。
LSTM如何缓解梯度消失
- 遗忘门通过 sigmoid 函数来控制需要遗忘的记忆,输出值在 0 到 1 之间。当遗忘门的输出值接近 0 时,网络可以选择性地忘记一部分记忆,从而限制梯度的传播。
- 输入门通过 sigmoid 函数来控制新信息的输入量,以及一个 tanh 函数来确定要更新的新信息。网络可以控制新信息的量,避免梯度在传播过程中变得过大。
- 输出门通过一个 sigmoid 函数来控制输出的记忆量,以及一个 tanh 函数来确定要输出的记忆。通过输出门的控制,网络可以选择性地输出信息。