Redis:缓存原理与高并发实战
Redis基础
初识Redis
认识NoSQL
SQL:结构化查询语言 => 关系型数据库
NoSQL:非关系型数据库
SQL与NoSQL的差异:
- 数据结构
- SQL结构化:表的信息依赖于表的结构
- NoSQL非结构化:存储的信息为KV形式
- 数据关联
- SQL关联:可以建立并维护表与表之间的关系(外键)
- NoSQL无关联:需要自行维护数据关联
- 查询方式
- SQL:使用SQL语句查询
- NoSQL:没有统一标准(Redis、MongoDB)
- 事物特性
- SQL:满足ACID
- NoSQL:基本可用BASE
- 存储方式
- SQL:磁盘
- NoSQL:内存(速度快)
- 扩展性
- SQL:垂直(本机)
- NoSQL:水平(支持分布式)
Redis特点
- KV结构
- 单线程,命令执行具备原子性
- 低延迟、性能快(基于内存、IO多路复用、C语言编写)
- 支持数据持久化
- 支持主从集群(扩展速度)、分片集群(扩展存储量)
- 支持多语言客户端
Redis安装
Redis官方只提供了Linux版本
Redis常见命令
Redis通用命令
KEYS:查看符合模板的所有key
不建议在生产环境(或集群的主节点)上使用。Redis单线程,会导致线程阻塞。
KEYS *name*DEL:删除key
DEL username
DEL username passwordEXISTS:判断key存在
EXISTS usernameEXPIRE:给key设置有效期,单位是秒(到期自动删除)
TTL:查看有效期(-2表示不存在、-1表示永不过期)
EXPIRE name 20
TTL nameRedis数据结构
- String
- Hash(类似JSON)
- List(列表)
- Set(无重复元素的集合)
- SortedSet(有序集合)
- GEO(经纬度坐标)
- BitMap
- HyperLog
String
字符串,最简单的数据类型。上限是512M。
String的类型
- string:字符串
- int:整型,可以自增自减
- float:浮点类型,可以自增自减
常见命令
- SET:添加、修改KV
- GET:通过K查询V
- MSET:批量添加
- MGET:批量查询
- INCR:整型i++(
INCR age:age++) - INCRBY:整型i+=n(
INCRBY age 2:age += 2) - INCRBYFLOAT:浮点i+=n(
INCRBYFLOAT level 2:level += 2) - SETNX:新增KV(若存在K则不添加)
- SETEX:添加KV,并指定有效期
key的结构:层级存储。用于key名称的设置,避免了key重复的问题
项目名:业务名:类型:id hpan:user:username:1 hpan:admin:username:1
Hash
无序字典,类似JSON。
相比于序列化JSON,以字符串形式保存。Hash结构可以更方便地修改。
常见命令
- HSET key field value:添加、修改key的field值(
HSET user:1 username wmh) - HGET key field:查询key的field值(
HSET user:1 username) - HMSET、HMGET:批量
- HGETALL:查询所有的field和value
- HKEYS、HVALS:查询所有的field或value
- HINCRBY:整型value+=n(
HINCRBY user:4 age 2:user[4].age+=2) - HSETNX:新增field-value(若存在K则不添加)
List
双向链表,类似于LinkedList。可以正向、反向查找。
- LPUSH/RPUSH key value:左/右侧插入元素
- LPOP/RPOP key:左/右侧弹出元素
- LRANGE key i j:从i到j遍历元素
- BLPOP、BRPOP:阻塞式获取(有元素就取、没有元素就等)
- 模拟栈:入口出口在同一边
- 模拟队列:入口出口不在同一边
- 模拟阻塞队列:入口出口不在同一边,出队使用BLPOP、BRPOP
Set
无序、元素不可重复、查找速度快、支持交集、并集、差集等。
单个Set:
- SADD key item...:添加item
- SREM key item...:移除item
- SCARD key:查询元素个数
- SISMEMBER key item:判断item是否存在
- SMEMBERS:获取所有元素
Set之间:
- SINTER k1 k2:交集
- SDIFF k1 k2:差集
- SUNION k1 k2:并集
SortedSet
每个元素都带一个score属性,根据score排序。可排序、元素不重复、查询速度快。
- ZADD key score item...:添加item
- ZREM key item...:移除item
- ZSCORE key item:查询item的score
- ZRANK key item:获取item的排名
- ZCARD key:查询元素个数
- ZCOUNT key min max:获取分数在min到max的元素个数
- ZRANGE key i j:获取排名为i到j的元素
- ZRANGEBYSCORE key min max:获取分数为min到max的元素
- ZINCRBY key n item:item.score+=n
- ZDIFF、ZINTER、ZUNION:差集交集并集
排名默认为升序,降序排名需要加上REV:ZRANK → ZREVRANK
Redis的Java客户端
客户端介绍
- Jedis:方法命名和Redis命令相似。线程不安全,多线程需要连接池。
- letture:基于Netty,支持同步、异步和响应式编程方式,线程安全。支持哨兵模式、集群模式和管道模式。
- Redisson:实现了分布式、可伸缩的Java数据结构。和使用原生集合一样使用Redis集合。
SpringDataRedis:整合了Jedis、letture
Jedis
redis/jedis: Redis Java client (github.com)
Jedis使用:
1、引入依赖
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.0.0</version>
</dependency>2、建立连接
Jedis jedis = new Jedis("localhost", 6379);
jedis.auth("123.com");
jedis.set("name", "wmhs");
jedis.close();多线程 → 使用Jedis连接池
SpringDataRedis
简介
- 整合Lettuce和jedis
- 提供了RedisTemplate统一API来操作Redis
- 支持Redis的发布订阅模型、哨兵、集群
- 支持基于Lettuce的响应式编程
- 支持基于JDK、JSON、宇符串、Spring对象的数据序列化及反序列化
- 支持基于Redis的DKCollection实现
SpringDataRedis中提供了RedisTemplate工具类,其中封装了各种对Redis的操作。
不同数据类型的操作API封装到了不同的类型中
自定义RedisSerializer
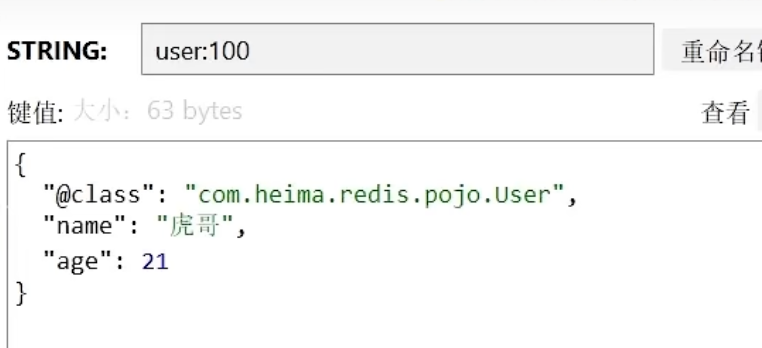
RedisTemplate可以接收Object作为值写入Redis。
But,采用JDK序列化Object为字节形式。占用内存大、可读性差。
So,可以自行编写RedisSerializer实现(使用jackson)。
But,写入的对象有@class属性,造成了额外开销。
StringRedisTemplate
Spring默认提供了一个StringRedisTemplate类,KV的序列化方式默认就是String方式。
如何存对象? → 自行序列化和反序列化
常见的JSON序列化库:
- gson(google 的)
- fastjson alibaba(阿里,快但是有Bug)
- jackson
- kryo
使用步骤:
1、导入pom.xml配置
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>2、配置application.yml
spring:
data:
redis:
port: 6379
host: 127.0.0.1
password: 123456
database: 0
timeout: 10000
lettuce:
pool:
enabled: true
max-active: 100
max-wait: 10000
max-idle: 10
min-idle: 13、编写测试类
不连接数据库启动SpringBoot项目
java@SpringBootApplication(exclude= {DataSourceAutoConfiguration.class})
@Test
void StringRedisTemplateTest() {
ValueOperations<String, String> ops = stringRedisTemplate.opsForValue();
// name
ops.set("name", "wmh");
System.out.println("name: " + ops.get("name"));
// yx
ops.set("yx", gson.toJson(new User("yx", 18)));
String yx = ops.get("yx");
System.out.println("yx: " + gson.fromJson(yx, User.class));
} ## 基于Token单点登录
## 基于Token单点登录
获取验证码
流程图
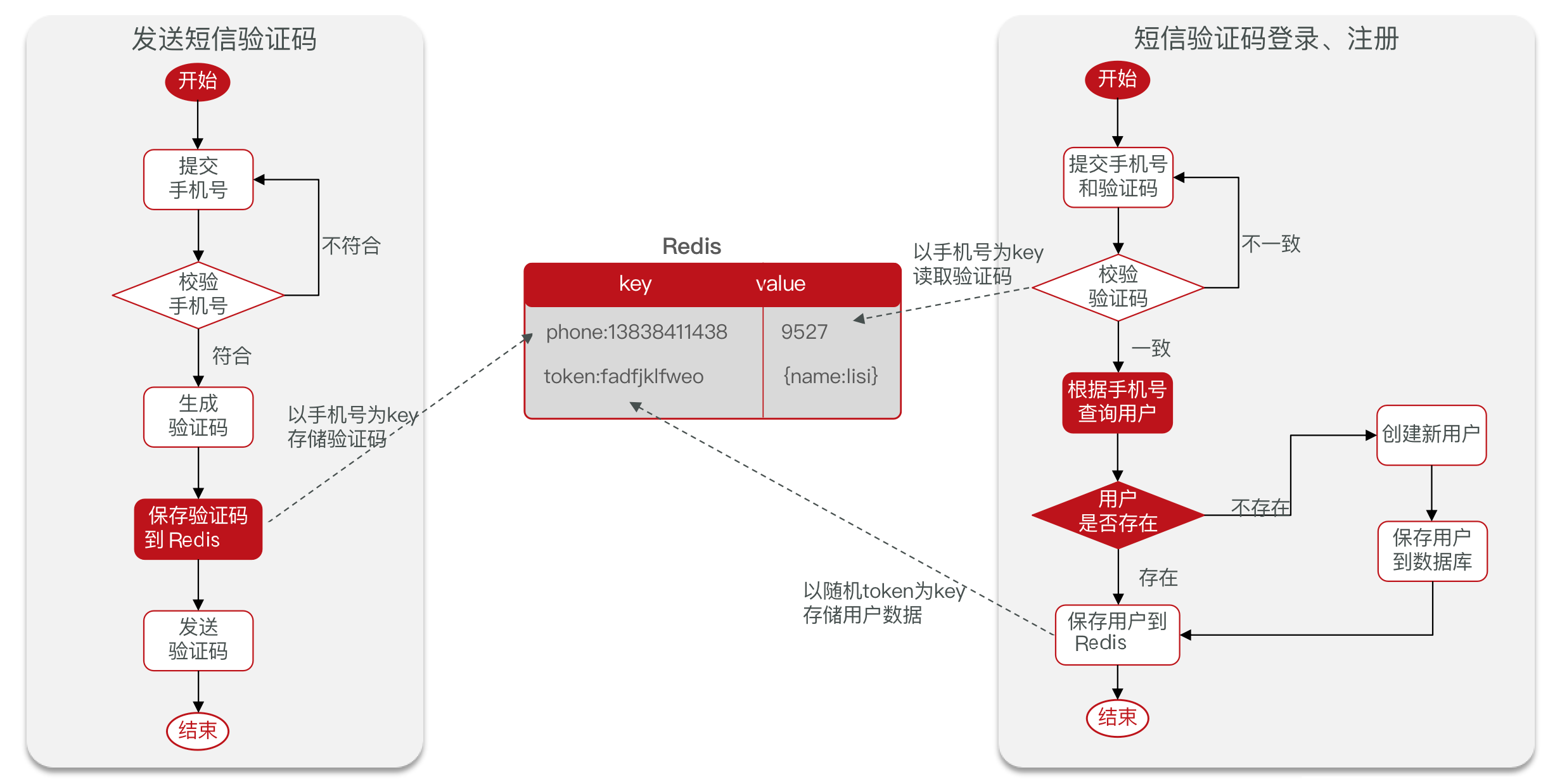
graph LR
1([begin])
2([end])
a[提交手机号]
b{手机号合法校验}
e[保存到Redis]
f[发送验证码]
1 --> a
a --> b
b -->|"合法"| e --> f --> 2
b -->|"不合法"| 1业务实现
使用 Hutools工具类 生成随机验证码
String code = RandomUtil.randomNumbers(6);将验证码保存到Redis
redisTemplate.opsForValue().set(
REDIS_CODE_PRE + phone, code, 2, TimeUnit.MINUTES
);登录
流程图
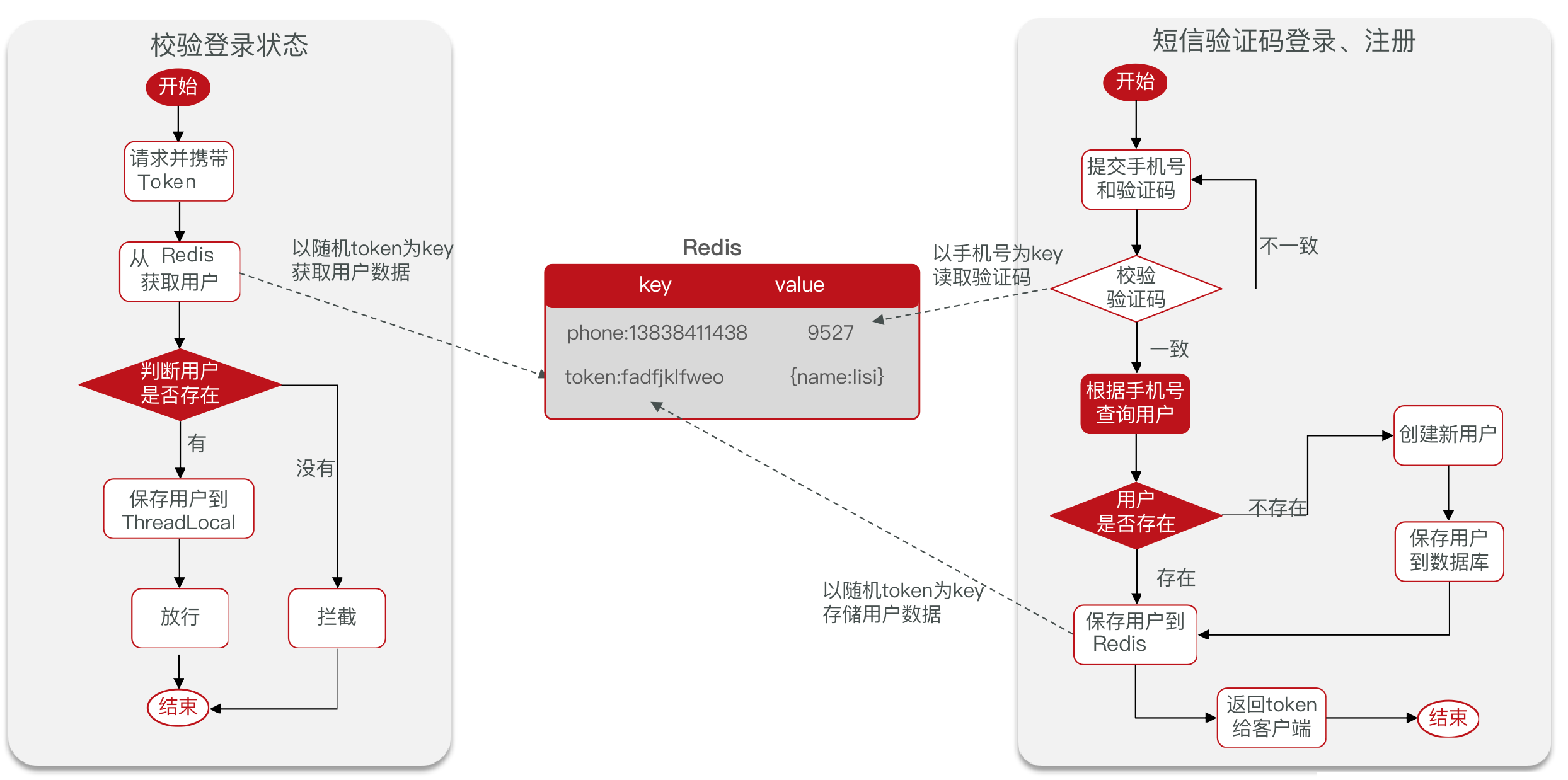
登录拦截和Token刷新
流程图
使用拦截器实现登录拦截和Token刷新
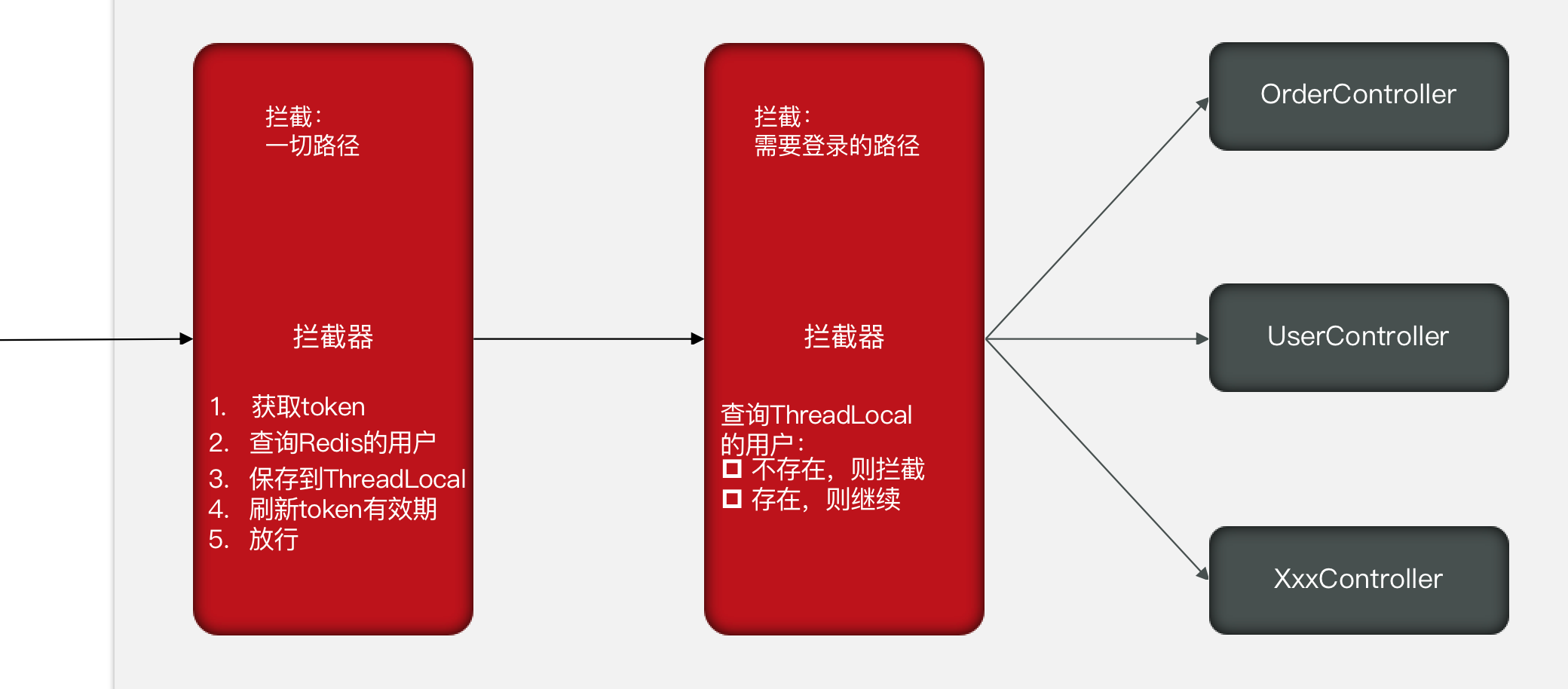
业务实现
拦截器配置类
@Configuration
public class MvcConfig implements WebMvcConfigurer {
@Autowired
private StringRedisTemplate template;
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new TokenInterceptor(template)).addPathPatterns(
"/**"
).order(0);
registry.addInterceptor(new LoginInterceptor()).addPathPatterns(
"/user"
).order(2);
}
}Token刷新拦截器
拦截所有请求
用于刷新Token有效期,并将用户信息保存到ThreadLocal。之后使用ThreadLocal获取用户信息。
graph LR
1([请求])
2([Controller])
a[提交Token]
b[在Redis中查询用户]
1 --> a --> b
b -->|不存在| 2
b -->|存在| 查询用户信息 --> 保存到ThreadLocal --> Token续期 --> 2在请求头上获取Token
String token = request.getHeader("authorization"));使用ThreadLocal保存用户信息
public class UserHolder {
private static final ThreadLocal<UserDTO> tl = new ThreadLocal<UserDTO>();
public static void saveUser(UserDTO user) {
tl.set(user);
}
public static UserDTO getUser() {
return tl.get();
}
public static void removeUser() {
tl.remove();
}
}登录拦截器
拦截需要登录才能访问的接口(/user 个人信息)
用于判断是否登录,通过ThreadLocal判空操作获取登录信息。
graph LR
1([请求])
2([Controller])
3(["❎ 401"])
a[从ThreadLoacl中获取用户信息]
1 -->a -->|存在| 2
a -->|不存在| 3@Data
public class LoginInterceptor implements HandlerInterceptor {
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) {
if (UserHolder.getUser() == null) {
response.setStatus(401);
return false;
}
return true;
}
}缓存实现及其问题
认识缓存
缓存就是数据交换的缓冲区,是存贮数据的临时地方,一般读写性能较高。
缓存的作用:
- 降低后端负载
- 提高读写效率,降低响应时间
缓存的成本:
- 数据一致性成本
- 代码维护成本
- 运维成本
添加缓存
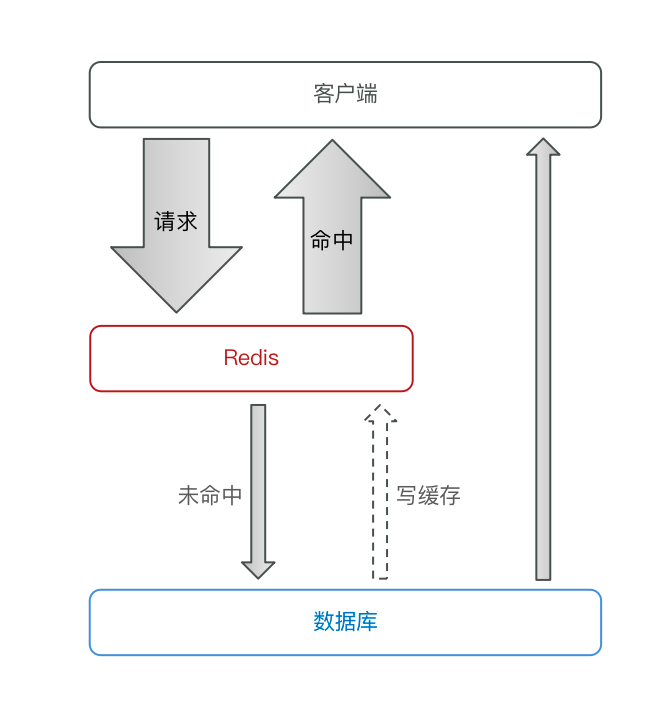
缓存作用模型
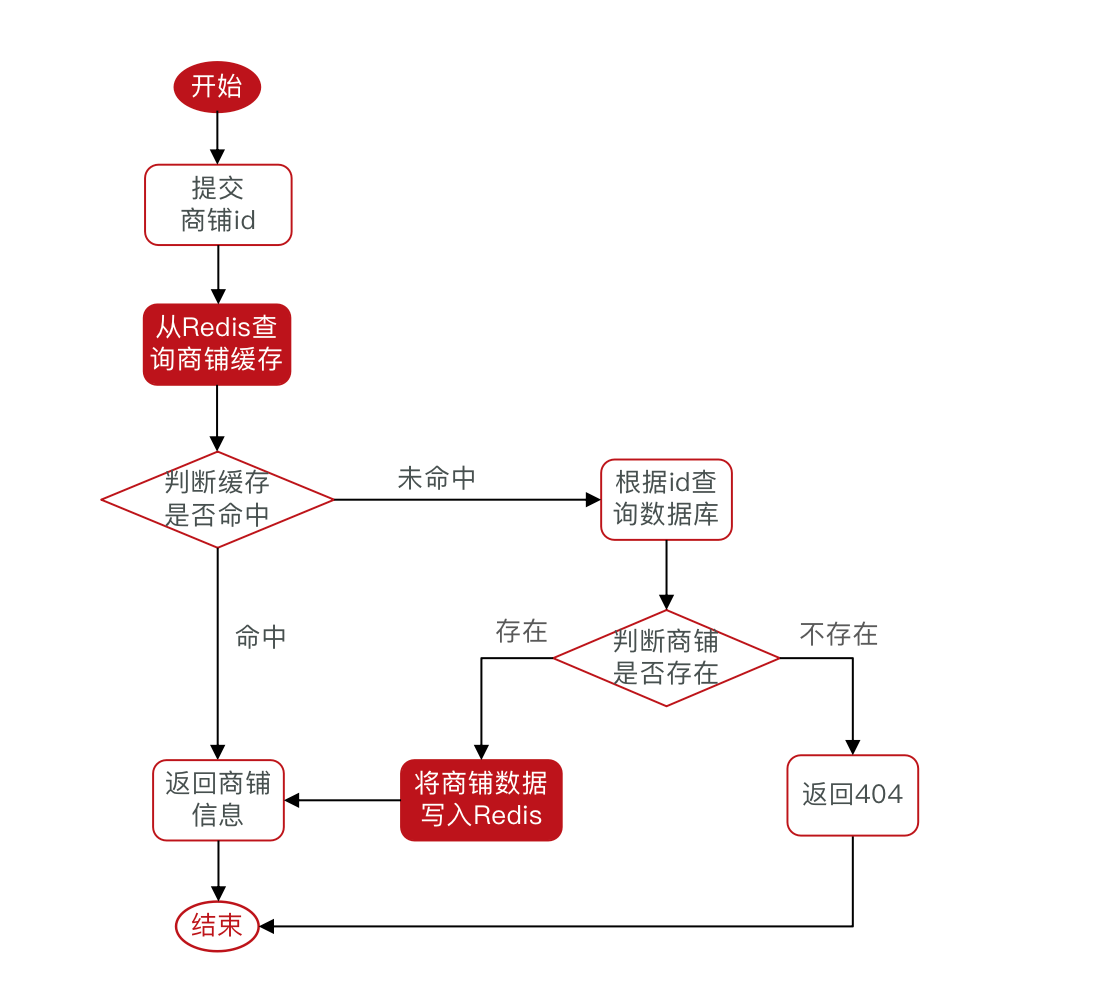
查询商铺缓存的流程
添加缓存业务代码
@Override
public List<UserDTO> getUserlist() {
Gson gson = new Gson();
// 1. 查询redis缓存
String cache = redisTemplate.opsForValue().get(CACHE_LIST_PRE);
// 2.1. 存在缓存
if (StrUtil.isNotBlank(cache)) {
// 3. 反序列化
return gson.fromJson(cache, new TypeToken<List<UserDTO>>() {}.getType());
}
// 2.2. 不存在缓存
// 3. 查询数据库
List<User> userList = list();
// 4. 信息脱敏
ArrayList<UserDTO> userDTOList = new ArrayList<>();
for (User user : userList) {
UserDTO dto = new UserDTO();
BeanUtil.copyProperties(user, dto);
dto.setPhone(DesensitizedUtil.mobilePhone(dto.getPhone()));
userDTOList.add(dto);
}
// 5. 保存到Redis
redisTemplate.opsForValue()
.set(CACHE_LIST_PRE, gson.toJson(userDTOList), 2, TimeUnit.MINUTES);
return userDTOList;
}缓存更新
缓存更新策略
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 利用Redis的内存淘汰机制,内存不足时自动淘汰部分数据。 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询时更新缓存。 | 编写业务逻辑,在修改数据库的同时,更新缓存。 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
- 低一致性需求:使用内存淘汰机制
- 高一致性需求:主动更新 + 超时剔除
主动更新策略
- 读操作:
- 缓存命中则直接返回
- 缓存未命中则查询数据库,并写入缓存,设定超时时间
- 写操作:
- 先操作数据库,然后再删除缓存
- 要确保数据库与缓存操作的原子性(事物/分布式事物)
缓存穿透
什么是缓存穿透
缓存穿透是指客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
缓存空对象
优点:实现简单,维护方便
缺点:额外的内存消耗、可能造成短期的不一致

业务实现
// 缓存空对象
@Override
public UserDTO getInfoById(Long id) {
// 缓存查询
String userString = redisTemplate.opsForValue()
.get(CACHE_USER_PRE + id);
if (StrUtil.isNotBlank(userString)) {
// 有缓存 => 真实数据
return gson.fromJson(userString, UserDTO.class);
}
if (userString != null) {
// 有缓存 => 空对象
throw new BusinessException(404, "用户不存在");
}
// 数据库查询
User user = getById(id);
if (user == null) {
// 缓存空对象
redisTemplate.opsForValue()
.set(CACHE_USER_PRE + id, "", 2, TimeUnit.MINUTES);
throw new BusinessException(404, "用户不存在");
}
// 信息脱敏
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 缓存真实数据
redisTemplate.opsForValue()
.set(CACHE_USER_PRE + id, gson.toJson(userDTO), 2, TimeUnit.MINUTES);
return userDTO;
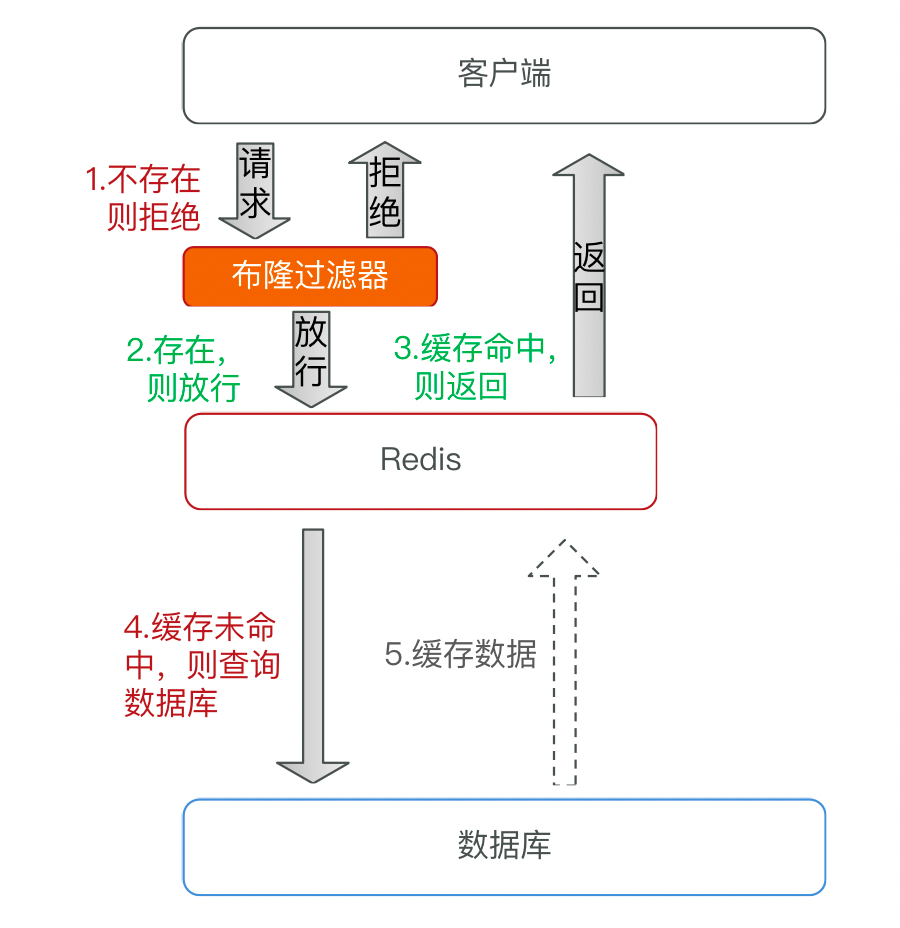
}布隆过滤器
优点:内存占用较少,没有多余key
缺点:实现复杂、存在误判可能
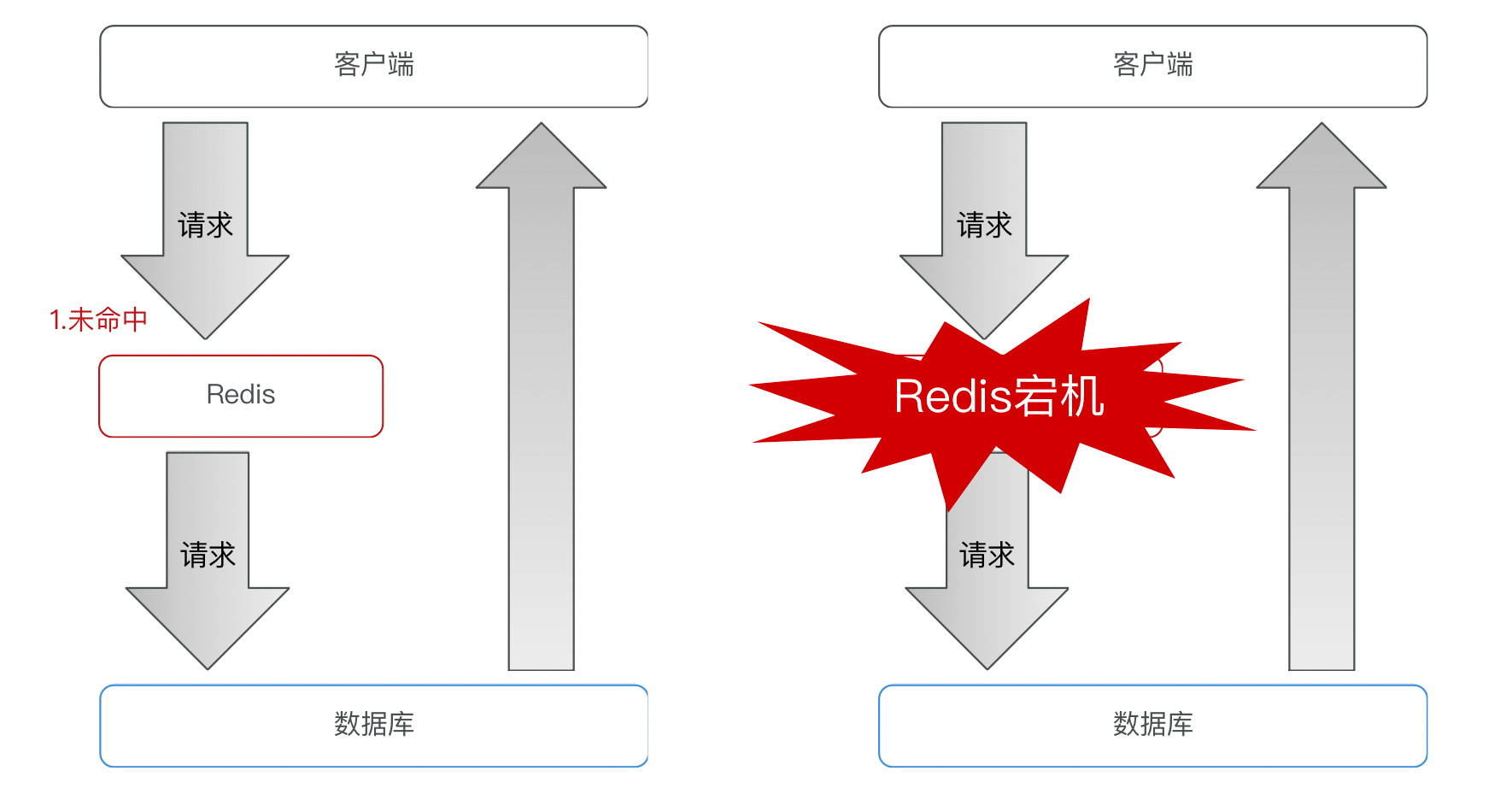
缓存雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
- 给不同的Key的TTL添加随机值
- 利用Redis集群提高服务的可用性
- 给缓存业务添加降级限流策略
- 给业务添加多级缓存
缓存击穿/热点Key
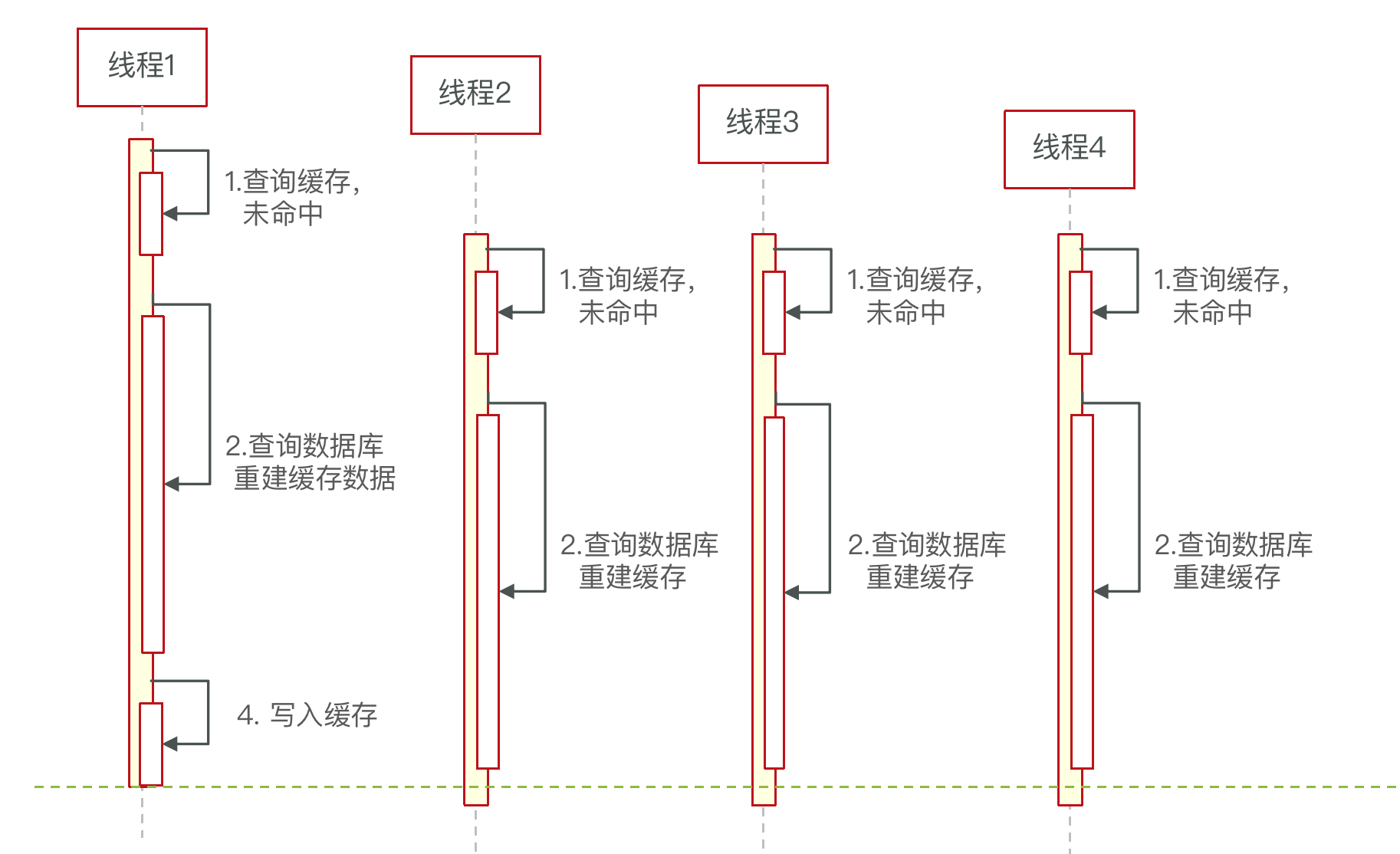
什么是缓存击穿
缓存击穿问题也叫热点Key问题:一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
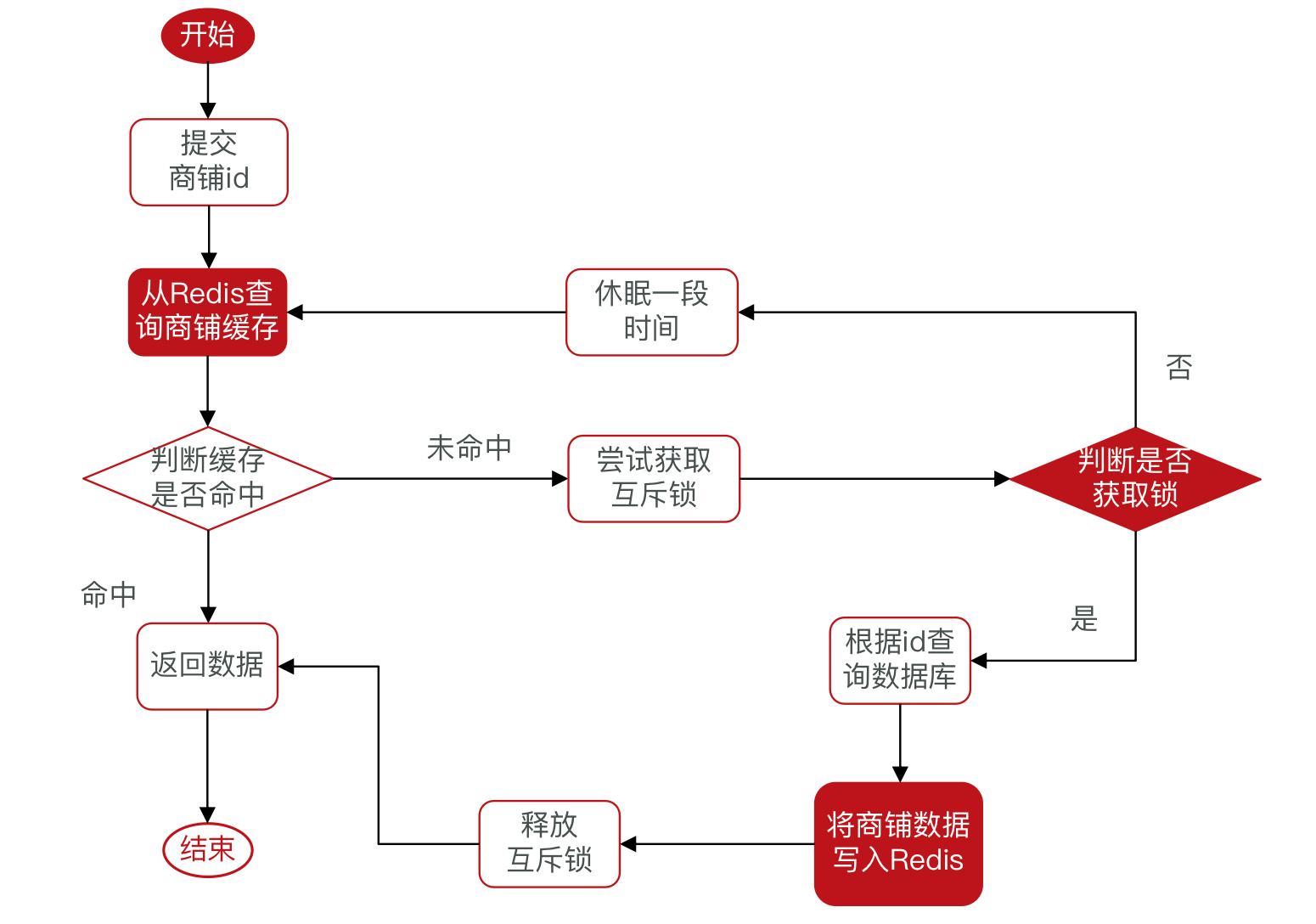
互斥锁
优点:没有额外的内存消耗、保证一致性、实现简单
缺点:线程需要等待,性能受影响、可能有死锁风险

互斥锁流程图
互斥锁业务代码
// 热点key-互斥锁
@Override
public List<UserDTO> getUserlist() throws InterruptedException {
// 1. 查询redis缓存
String cache = redisTemplate.opsForValue().get(CACHE_LIST_PRE);
// 2.1. 存在缓存
if (StrUtil.isNotBlank(cache)) {
// 3. 反序列化
return gson.fromJson(cache, new TypeToken<List<UserDTO>>() {}.getType());
}
// ⭐️ 获取互斥锁
String lock = REDIS_LOCK_PRE + "userlist";
Boolean flag = redisTemplate.opsForValue()
.setIfAbsent(lock, "1", 30, TimeUnit.SECONDS);
if (BooleanUtil.isFalse(flag)) {
// ⭐️ 获取锁失败了 => 休眠 + 递归
Thread.sleep(200);
return getUserlist();
}
ArrayList<UserDTO> userDTOList = new ArrayList<>();
try {
// 2.2. 不存在缓存
// 3. 查询数据库
List<User> userList = list();
log.info("查询数据库");
// 4. 信息脱敏
for (User user : userList) {
UserDTO dto = new UserDTO();
BeanUtil.copyProperties(user, dto);
dto.setPhone(DesensitizedUtil.mobilePhone(dto.getPhone()));
userDTOList.add(dto);
}
// 5. 保存到Redis
redisTemplate.opsForValue()
.set(CACHE_LIST_PRE, gson.toJson(userDTOList), 10, TimeUnit.SECONDS);
} catch (Exception ignored) {
} finally {
// ⭐️ 释放锁
redisTemplate.delete(lock);
}
return userDTOList;
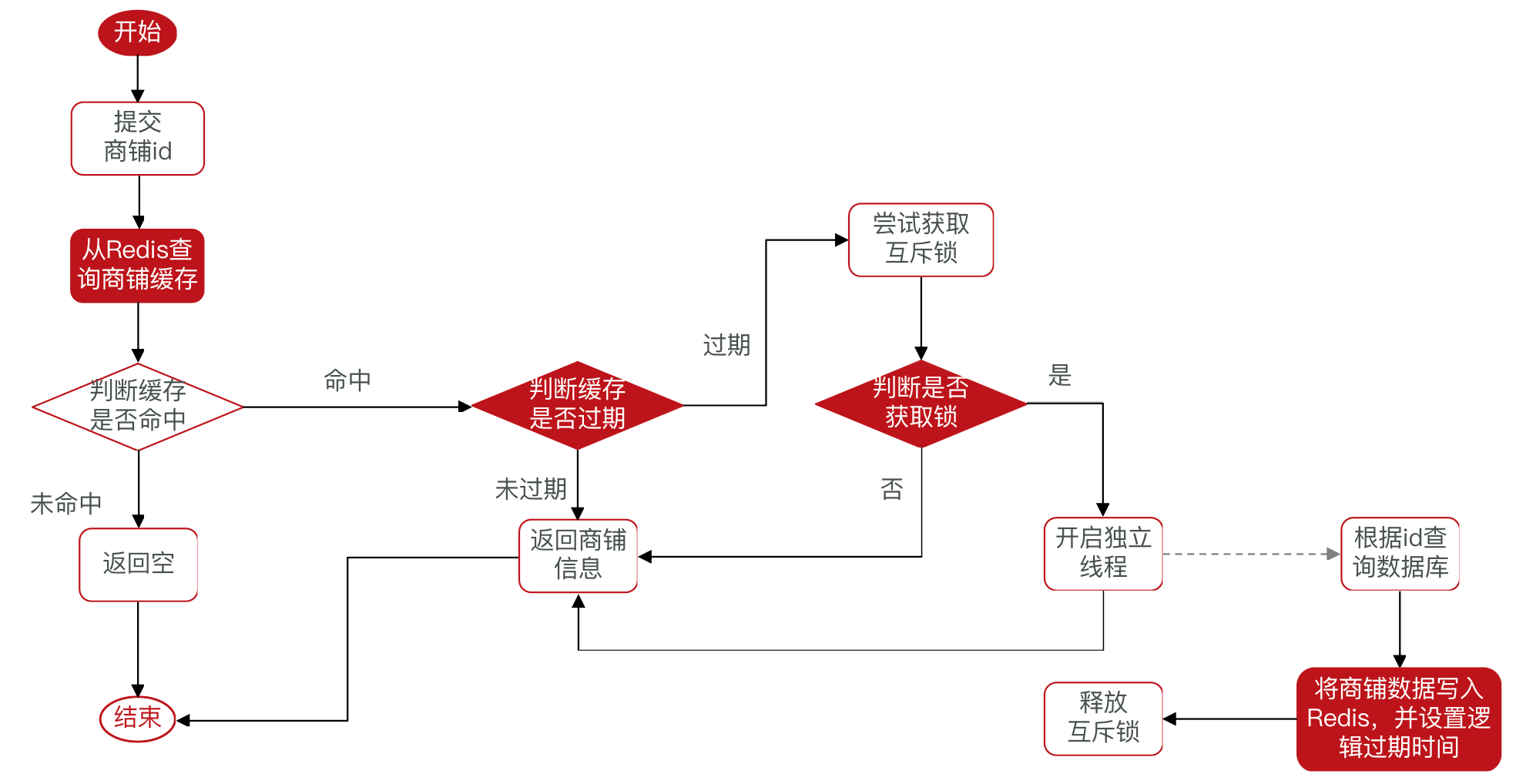
}逻辑过期
优点:线程无需等待,性能较好
缺点:不保证一致性、有额外内存消耗、实现复杂
逻辑过期流程图
逻辑过期业务代码
1、LogicalExpiration逻辑过期实体类,使用泛型使其通用化
@Data
@AllArgsConstructor
@NoArgsConstructor
public class LogicalExpiration<T> {
private T value;
private Date date;
}2、核心业务代码
public UserDTO getUserById(Long id) {
// 1. 查询缓存
String userString = redisTemplate.opsForValue().get(CACHE_USER_PRE + id);
if (StrUtil.isBlank(userString)) {
// 没有缓存 -> 查询数据
User user = getById(id);
// 没有数据 -> 报错
if (user == null) {
throw new BusinessException(500, "用户不存在");
}
// 数据脱敏
UserDTO userDTO = BeanUtil.copyProperties(user, UserDTO.class);
// 新建缓存
Date date = new Date();
date.setTime(System.currentTimeMillis() + 2 * 60 * 1000);
redisTemplate.opsForValue().set(CACHE_USER_PRE + id, gson.toJson(
new LogicalExpiration<>(userDTO, date)
));
// 返回数据
return userDTO;
}
// 存在缓存 => 反序列化拿到对象
LogicalExpiration<UserDTO> logicalExpiration = gson.fromJson(
userString, new TypeToken<LogicalExpiration<UserDTO>>() {}.getType());
// 判断缓存是否过期
if (logicalExpiration.getDate().before(new Date())) {
// 已经过期 => 新建线程进行更新缓存
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.execute(() -> {
UserDTO userDTO = BeanUtil.copyProperties(getById(id), UserDTO.class);
Date date = new Date();
// 设置TTL为2min
date.setTime(System.currentTimeMillis() + 2 * 60 * 1000);
redisTemplate.opsForValue().set(CACHE_USER_PRE + id, gson.toJson(
new LogicalExpiration<>(userDTO, date)
));
});
}
// 返回数据
return logicalExpiration.getValue();
}购物秒杀及分布式锁
全局唯一ID
Redis自增ID策略
ID构造是:时间戳 + 计数器

每天一个key,方便统计订单量
业务实现
获取指定时间的秒数
LocalDateTime timeBegin = LocalDateTime.of(2024, 1, 1, 0, 0, 0);
long second = timeBegin.toEpochSecond(ZoneOffset.UTC);获取当前时间的秒数
long now = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC);全局唯一ID业务代码
public Long getID(String key) {
// 获取时间戳
long now = LocalDateTime.now().toEpochSecond(ZoneOffset.UTC);
long timestamp = now - TIMESTAMP_BEGIN;
// 利用redis实现自增长
String date = new SimpleDateFormat("yyyyMMdd").format(new Date());
Long inc = redisTemplate.opsForValue().increment("ID:" + key + ":" + date);
// 拼接并返回
return timestamp << 32 | inc;
}实现秒杀下单
秒杀下单逻辑流程
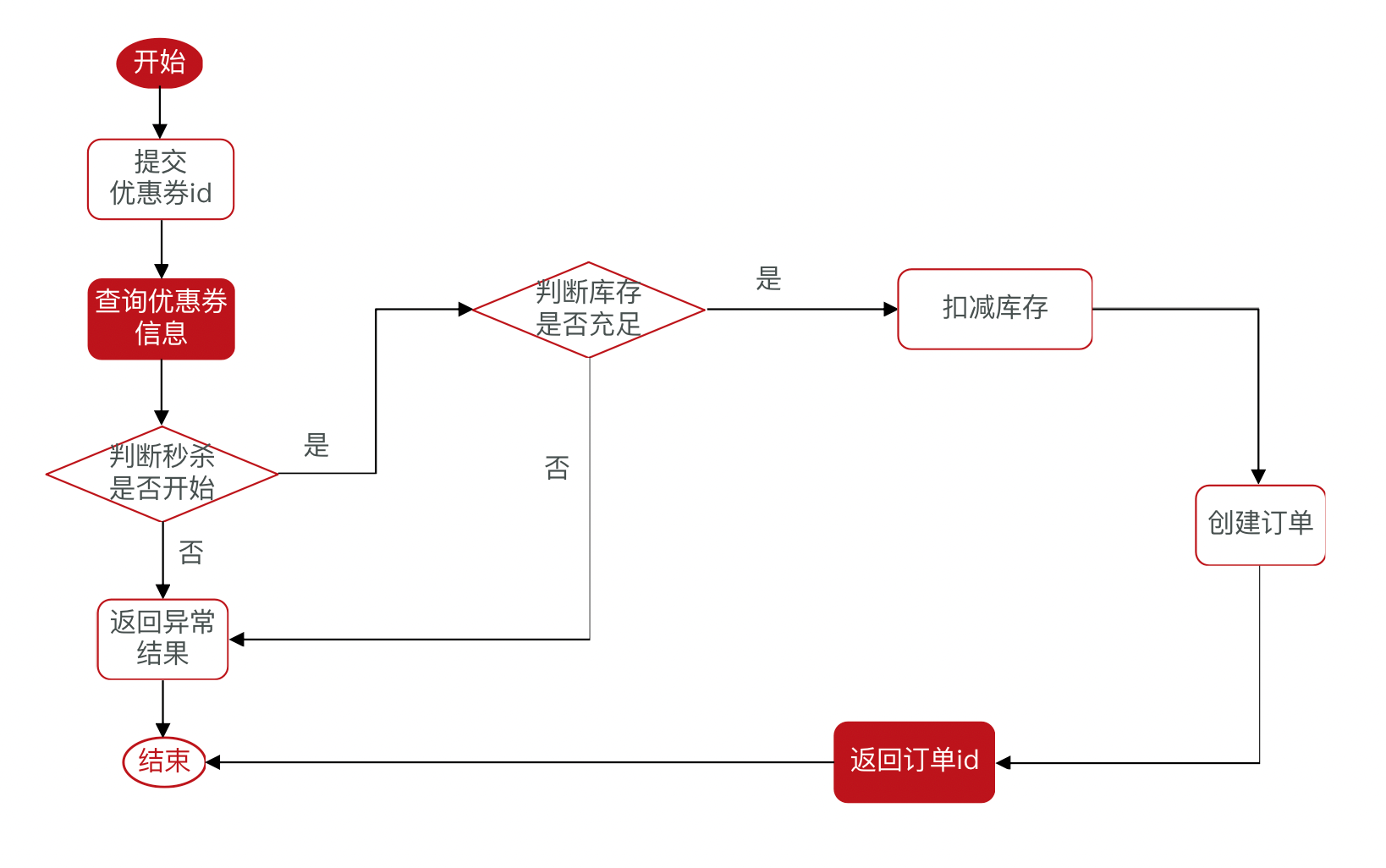
业务实现
graph LR
begin(begin)
a{判断库存}
b{判断存在}
e(end)
begin --> 提交商品id --> b -->|存在| a
b -->|不存在| 返回异常
a -->|充足| 扣减库存 --> 创建订单 --> 返回订单id --> e
a -->|不足| 返回异常 --> e@Transactional
public String getProduct(Long id) {
// 判断商品是否存在
Product pro = getById(id);
if (pro == null) {
throw new BusinessException(400, "商品不存在");
}
// 判断库存
int num = pro.getNum();
if (num <= 0) {
throw new BusinessException(400, "库存不足");
}
// 库存 - 1
pro.setNum(num - 1);
update(pro, new QueryWrapper<>());
// 下订单
Ordertable order = new Ordertable();
order.setOrderID(idUtil.getID("order").toString());
order.setUserID(123);
ordertableService.save(order);
return order.getOrderID();
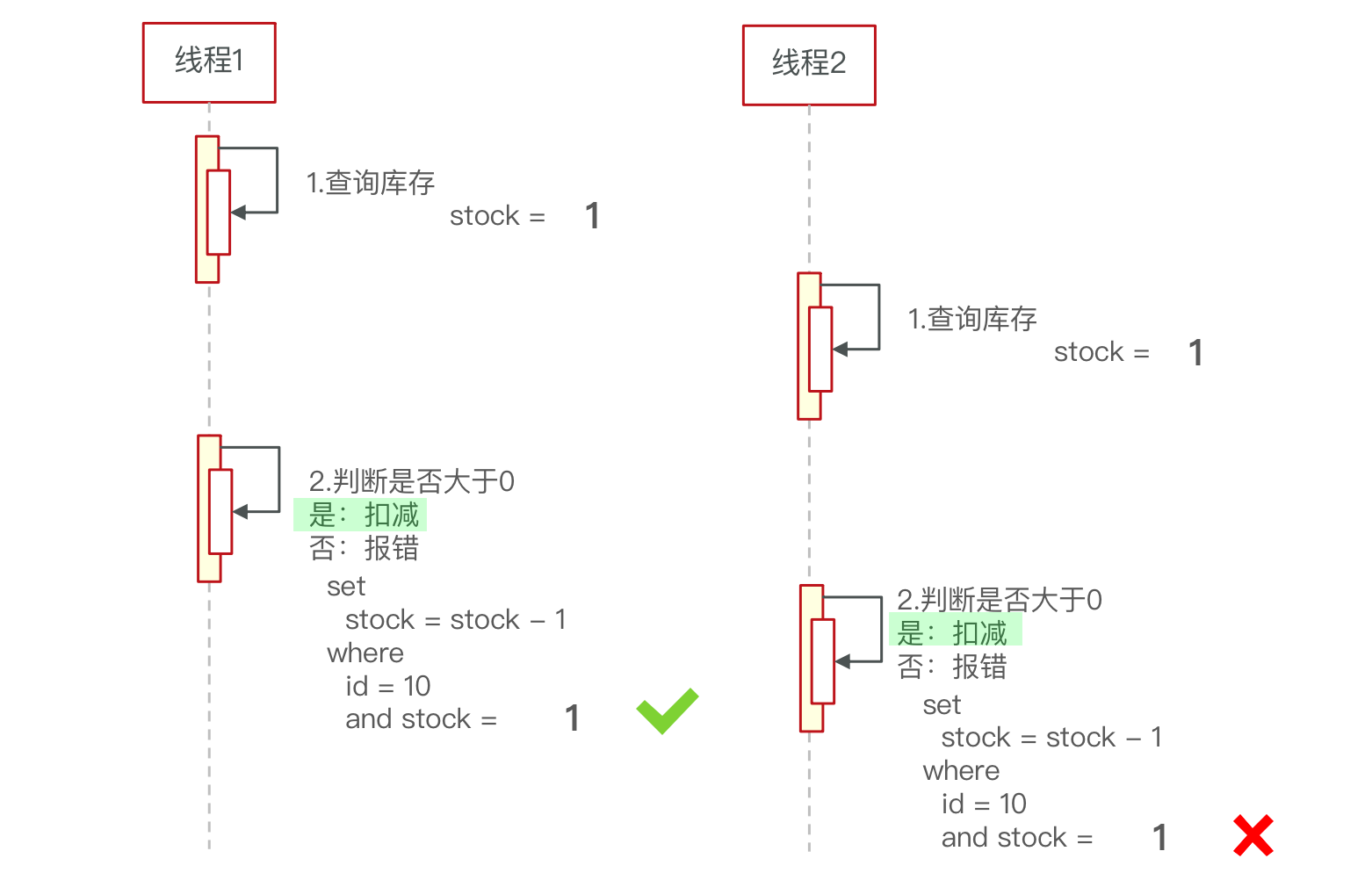
}“超卖”问题
问题复现
在多线程并发会产生问题
使用5000个线程进行测试
20个库存卖了210个订单
原因分析
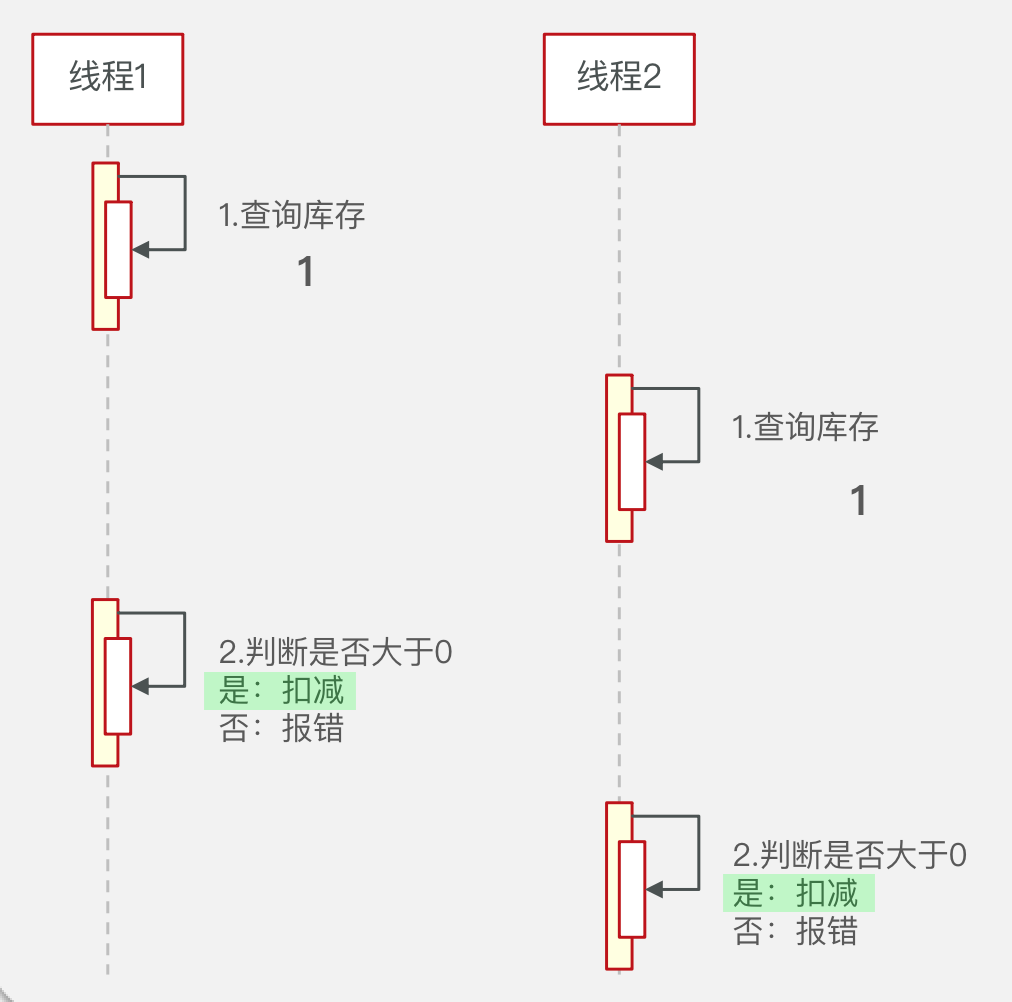
锁的类型
超卖问题是典型的多线程安全问题,针对这一问题的常见解决方案就是加锁
悲观锁:认为线程安全问题一定会发生,因此在操作数据之前先获取锁,确保线程串行执行。
- 例如Synchronized、Lock都属于悲观锁
乐观锁:认为线程安全问题不一定会发生,因此不加锁,只是在更新数据时去判断有没有其它线程对数据做了修改。
- 如果没有修改则认为是安全的,自己才更新数据。
- 如果已经被其它线程修改说明发生了安全问题,此时可以重试或异常。
乐观锁
乐观锁的关键是判断之前查询得到的数据是否有被修改过。(CAS法)
代码实现
graph LR
begin(begin)
a{判断库存}
b{判断存在}
c{"⭐️判断库存<br/>是否被修改"}
e(end)
begin --> 提交商品id --> b -->|存在| a
a -->|充足| c -->|没被修改| 扣减库存 --> 创建订单 --> 返回订单id --> e
b -->|不存在| 返回异常
a -->|不足| 返回异常
c -->|被修改| 返回异常
返回异常 --> e@Transactional
public String getProduct(Long id) {
// 判断商品是否存在
Product pro = getById(id);
if (pro == null) {
throw new BusinessException(400, "商品不存在");
}
// 判断库存
int num = pro.getNum();
if (num <= 0) {
throw new BusinessException(400, "库存不足");
}
// 下订单
Ordertable order = new Ordertable();
order.setOrderID(idUtil.getID("order").toString());
order.setUserID(111);
// 库存 - 1
pro.setNum(num - 1);
boolean success = update(pro, new QueryWrapper<Product>()
.eq("num", num));
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(order);
return order.getOrderID();
}经过多线程测试,成功解决超卖问题。

“一人一单”问题
问题分析
新要求:一个用户只能下一单
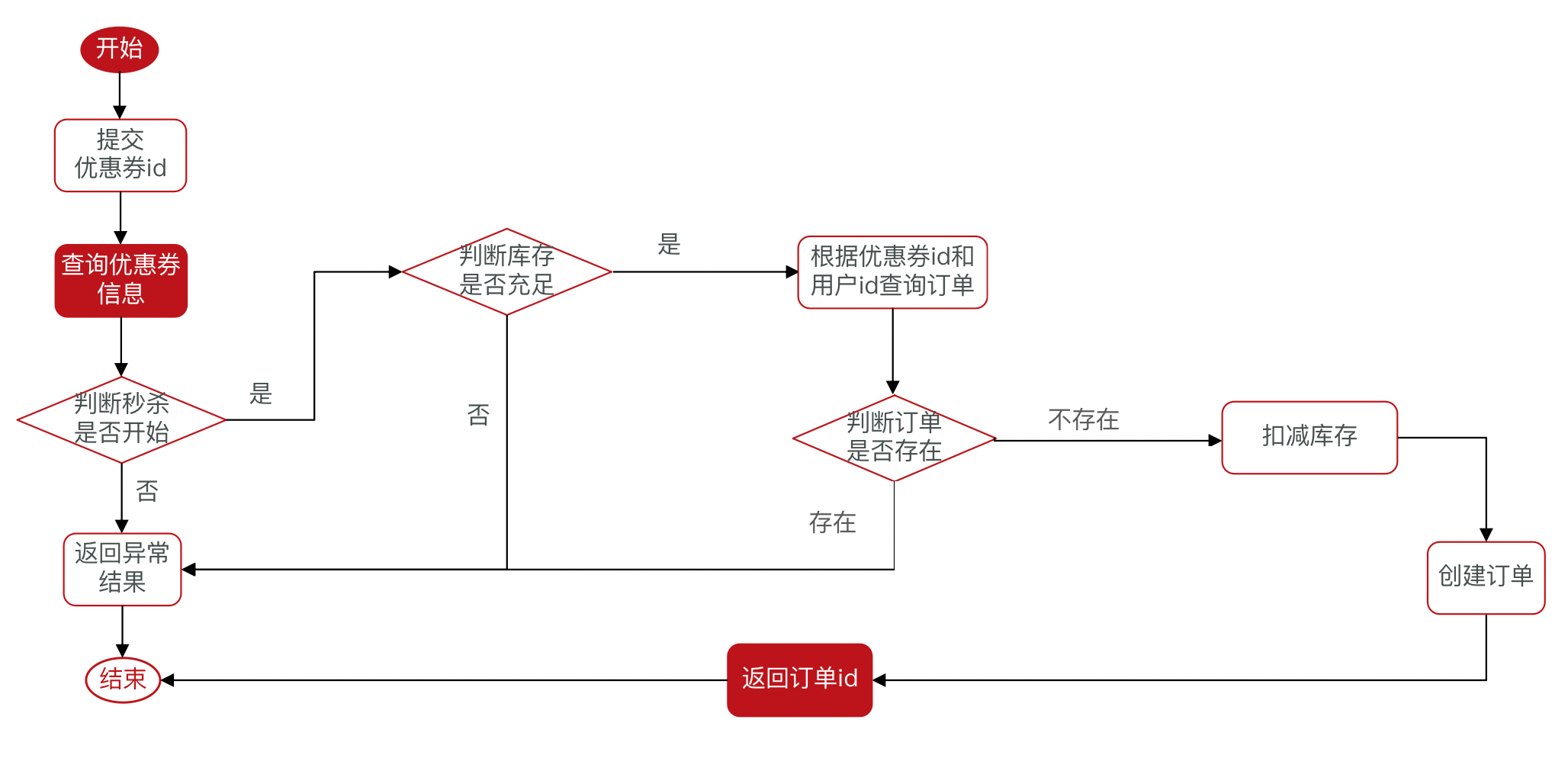
解决并发问题:使用 synchronized 锁机制。
业务实现
graph LR
begin(begin)
a{判断库存}
b{判断存在}
c{"判断库存<br/>是否被修改"}
d{"⭐️判断是否<br/>为重复订单"}
e(end)
begin --> 提交商品id --> b -->|存在| a
a -->|充足| c -->|没被修改| 扣减库存 --> d -->|"非重复订单"| 创建订单 --> 返回订单id --> e
d -->|重复订单| 返回异常
b -->|不存在| 返回异常
a -->|不足| 返回异常
c -->|被修改| 返回异常
返回异常 --> e@Transactional
public String getProductOnlyOne(Long id) {
// 判断商品是否存在
Product pro = getById(id);
if (pro == null) {
throw new BusinessException(400, "商品不存在");
}
// 判断库存
int num = pro.getNum();
if (num <= 0) {
throw new BusinessException(400, "库存不足");
}
synchronized (UserHolder.getUser().getPhone()) {
// ⭐️ 判断是否有重复订单
long cnt = ordertableService.count(new QueryWrapper<Ordertable>().eq("userID", UserHolder.getUser().getPhone()).eq("productID", id));
if (cnt != 0) {
// ⭐️ 存在重复订单
throw new BusinessException(400, "不允许重复下单");
}
// 下单
Ordertable newOrder = new Ordertable();
newOrder.setOrderID(idUtil.getID("order").toString());
newOrder.setUserID(UserHolder.getUser().getPhone());
newOrder.setProductID(Math.toIntExact(id));
// 库存 - 1
pro.setNum(num - 1);
boolean success = update(pro, new QueryWrapper<Product>().eq("num", num));
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(newOrder);
return newOrder.getOrderID();
}
}分布式锁
单机锁的问题
通过加锁可以解决在单机情况下的一人一单安全问题,但是在集群模式下就不行了。
每个锁监视器只对当前JVM有效,集群模式依旧会产生并发安全问题。

什么是分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
使用一个独立于JVM的锁监视器(分布式锁),让所有集群的JVM共享一个锁监视器,使得只有一个线程运行。
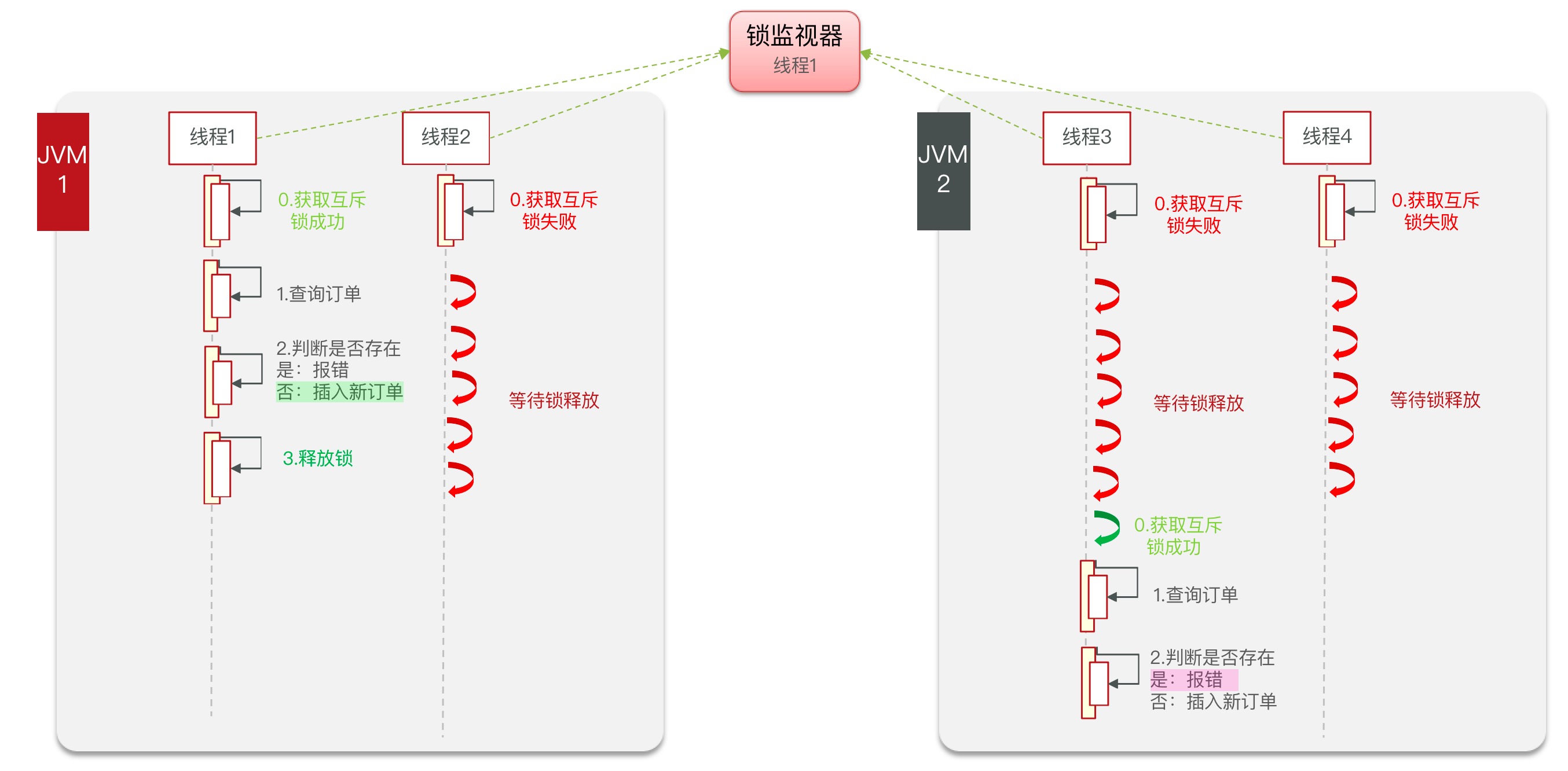
分布式锁的实现方式
分布式锁的核心是实现多进程之间互斥操作。
| MySQL | Redis | Zookeeper | |
|---|---|---|---|
| 互斥 | 利用mysql本身的互斥锁机制 | 利用setnx互斥命令 | 利用节点的唯一性和有序性实现互斥 |
| 高可用 | 好 | 好 | 好 |
| 高性能 | 一般 | 好 | 一般 |
| 安全性 | 断开连接,自动释放锁 | 利用锁超时时间,到期释放 | 临时节点,断开连接自动释放 |
Redis分布式锁(1.0)
使用setnx互斥命令
## 添加锁,NX是互斥、EX是设置超时时间
SET lock thread1 NX EX 10
## 释放锁
DEL keyRedis实现分布式锁流程图
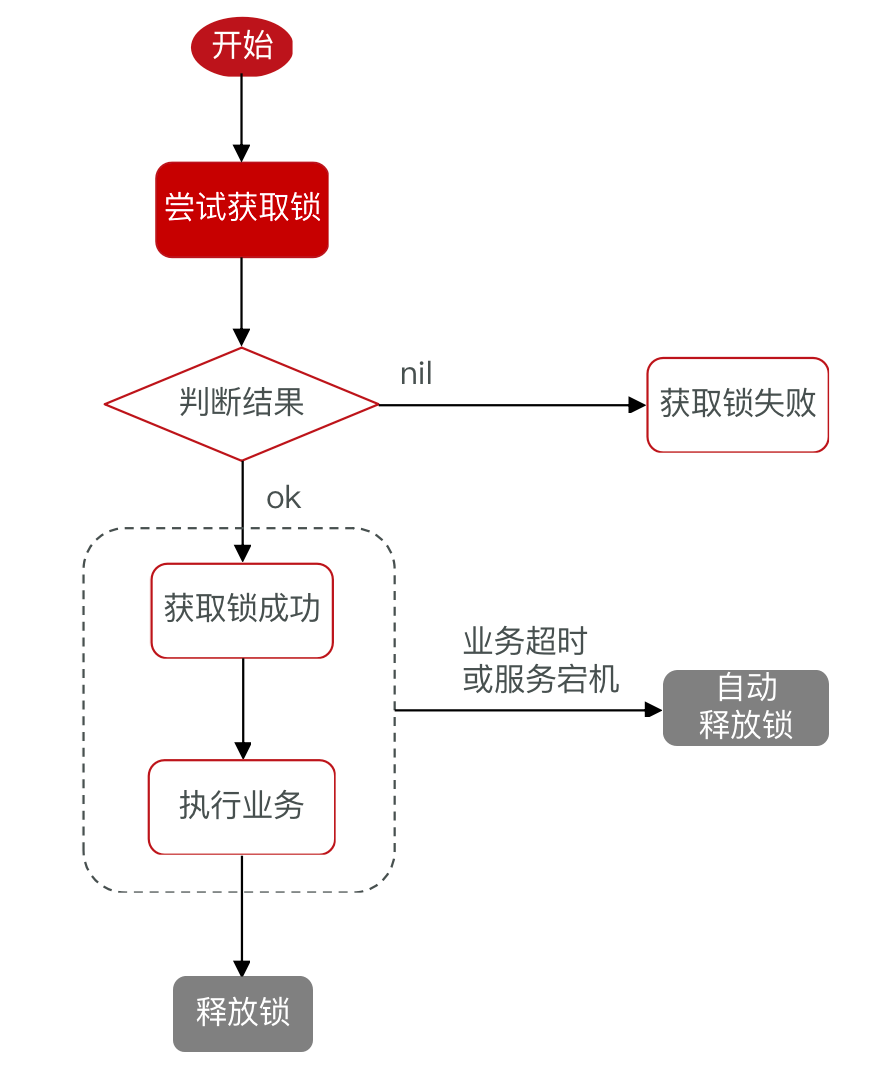
业务实现:
@Component
public class RedisLock {
@Autowired
private StringRedisTemplate redisTemplate;
private static final UUID uuid;
static {
uuid = UUID.randomUUID(true);
}
// 获取锁
public boolean trylock(String key, Thread thread) {
String value = uuid.toString() + thread.getId();
Boolean success = redisTemplate
.opsForValue().setIfAbsent(key, value, 10, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
// 删除锁
public void unlock(String key) {
redisTemplate.delete(key);
}
}@Transactional
@Override
public String getProductOnlyOneByRedis(Long id) {
// 判断商品是否存在
Product pro = getById(id);
if (pro == null) {
throw new BusinessException(400, "商品不存在");
}
// 判断库存
int num = pro.getNum();
if (num <= 0) {
throw new BusinessException(400, "库存不足");
}
String lock_key = REDIS_LOCK_PRE + UserHolder.getUser().getPhone();
try {
// 获取分布式锁(给用户上锁)
boolean lock = redisLock.trylock(lock_key, Thread.currentThread());
if (!lock) {
throw new BusinessException(400, "下单失败");
}
// 判断是否有重复订单
long cnt = ordertableService.count(
new QueryWrapper<Ordertable>()
.eq("userID", UserHolder.getUser().getPhone())
.eq("productID", id));
if (cnt != 0) {
// 存在重复订单
throw new BusinessException(400, "不允许重复下单");
}
// 下单
Ordertable newOrder = new Ordertable();
newOrder.setOrderID(idUtil.getID("order").toString());
newOrder.setUserID(UserHolder.getUser().getPhone());
newOrder.setProductID(Math.toIntExact(id));
// 库存 - 1
pro.setNum(num - 1);
boolean success = update(pro, new QueryWrapper<Product>().eq("num", num));
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(newOrder);
return newOrder.getOrderID();
} finally {
// 释放锁
redisLock.unlock(lock_key);
}
}Redis的Lua脚本
使用Lua脚本:在一个脚本中编写多条Redis命令,确保多条命令执行时的原子性。
-- 执行 set name jack
redis.call('set', 'name', 'jack')-- 先执行 set name jack
redis.call('set', 'name', 'jack')
-- 再执行 get name
local name = redis.call('get', 'name')
-- 返回
return name需要用Redis命令来调用脚本:
## 调用脚本 0: 脚本需要的key类型的参数个数
EVAL "return redis.call('set', 'name', 'jack')" 0脚本中的key、value可以作为参数传递。
key类型参数会放入KEYS数组,其它参数会放入ARGV数组,在脚本中可以从KEYS和ARGV数组获取这些参数。
EVAL "return redis.call('set', KEYS[1], ARGV[1])" 1 name Rose
Redis分布式锁(2.0)
Redis分布式锁(1.0)存在的问题:线程阻塞会导致锁过期,其他线程抢占锁后,之前线程会释放掉不属于自己的锁。
解决办法:释放锁时检查释放是自己的锁。
新问题:检查自己的锁时,锁过期,被其他线程抢占锁,前一个线程再次释放掉其他线程的锁。
新解决办法:释放锁时检查释放是自己的锁(且需要保证原子性)
使用lua脚本操作redis,保证操作的原子性。
基于Redis的分布式锁实现思路:
- 利用set nx ex获取锁,并设置过期时间,保存线程标示
- 释放锁时先判断线程标示是否与自己一致,一致则删除锁
lua脚本逻辑:
- 获取锁中的线程标示
- 判断是否与指定的标示(当前线程标示)一致
- 如果一致则释放锁(删除)
- 如果不一致则什么都不做
-- 这里的 KEYS[1] 就是锁的key,这里的ARGV[1] 就是当前线程标示
-- 获取锁中的标示,判断是否与当前线程标示一致
if (redis.call('GET', KEYS[1]) == ARGV[1]) then
-- 一致,则删除锁
return redis.call('DEL', KEYS[1])
end
-- 不一致,则直接返回
return 0使用java调用lua脚本

业务代码:
@Component
public class RedisLock {
@Autowired
private StringRedisTemplate redisTemplate;
private static final UUID uuid = UUID.randomUUID(true);
private static final DefaultRedisScript<Long> UNLOCK_SCRIPT;
static {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setLocation(new ClassPathResource("lua/unlock.lua"));
UNLOCK_SCRIPT = redisScript;
}
// 获取锁
public boolean trylock(String key, Thread thread) {
Boolean success = redisTemplate.opsForValue().setIfAbsent(
key, uuid.toString() + thread.getId(), 10, TimeUnit.SECONDS);
return Boolean.TRUE.equals(success);
}
// 删除锁
public void unlock(String key) {
redisTemplate.execute(UNLOCK_SCRIPT, Collections.singletonList(key),
uuid.toString() + Thread.currentThread().getId());
}
}Redis分布式锁(2.0)存在的问题:
- 不可重入:同一个线程无法多次获取同一把锁
- 不可重试:获取锁只尝试一次就返回 false,没有重试机制
- 超时释放:锁超时释放虽然可以避免死锁,但如果是业务执行耗时较长,也会导致锁释放,存在安全隐患
- 主从一致性:如果 Redis 提供了主从集群,主从同步存在延迟,当主宕机时,如果从并同步主中的锁数据,则会出现锁实现
⭐️ Redisson
Redisson功能介绍
Redisson是一个分布式操作 Redis 的 Java 客户端(分布式 Redis 数据网格),可以像在使用本地的集合一样操作 Redis。Redisson还提供了许多分布式服务,其中就包含了各种分布式锁的实现。
redisson/redisson: Redisson (github.com)
Redisson使用入门
1、引入依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.19.1</version>
</dependency>2、配置Redisson
@Configuration
@ConfigurationProperties(prefix = "spring.data.redis")
@Data
public class RedissonConfig {
private String host;
private String port;
private String password;
@Bean
public RedissonClient redissonClient() {
// 1. 创建配置
Config config = new Config();
String redisAddress = String.format("redis://%s:%s", host, port);
// 使用单个Redis
config.useSingleServer()
.setAddress(redisAddress).setPassword(password).setDatabase(0);
// 2. 创建实例
RedissonClient redisson = Redisson.create(config);
return redisson;
}
}可重入锁业务实现
解决同一个线程无法多次获取同一把锁的问题。
@Override
public String getProductOnlyOneByRedisson(Long id) {
// 判断商品是否存在
Product pro = getById(id);
if (pro == null) {
throw new BusinessException(400, "商品不存在");
}
// 判断库存
int num = pro.getNum();
if (num <= 0) {
throw new BusinessException(400, "库存不足");
}
String lock_key = REDIS_LOCK_PRE + UserHolder.getUser().getPhone();
RLock lock = redissonClient.getLock(lock_key);
try {
// ⭐️ 使用Redisson自带的可重入锁(给用户上锁)
if (!lock.tryLock()) {
throw new BusinessException(400, "下单失败");
}
// 判断是否有重复订单
long cnt = ordertableService.count(
new QueryWrapper<Ordertable>()
.eq("userID", UserHolder.getUser().getPhone())
.eq("productID", id));
if (cnt != 0) {
// 存在重复订单
throw new BusinessException(400, "不允许重复下单");
}
// 下单
Ordertable newOrder = new Ordertable();
newOrder.setOrderID(idUtil.getID("order").toString());
newOrder.setUserID(UserHolder.getUser().getPhone());
newOrder.setProductID(Math.toIntExact(id));
// 库存 - 1
pro.setNum(num - 1);
boolean success = update(pro, new QueryWrapper<Product>()
.eq("num", num));
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(newOrder);
return newOrder.getOrderID();
} finally {
// ⭐️ 释放锁
lock.unlock();
}
}可重入锁原理
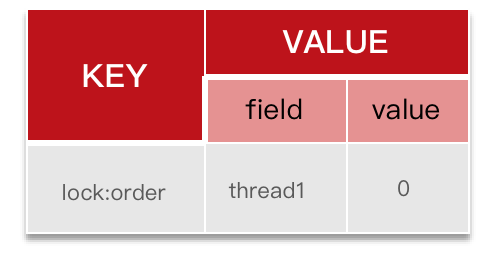

锁重试和看门狗机制
Redisson分布式锁原理:
- 可重入:利用hash结构记录线程id和重入次数
- 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
- 锁过期问题:watchDog看门狗机制,每隔一段时间(releaseTime / 3),重置超时时间
锁重试和看门狗机制流程图
看门狗原理:
- 监听当前线程,默认过期时间是 30 秒,每 10 秒续期一次(补到 30 秒)
- 如果线程挂掉(注意 debug 模式也会被它当成服务器宕机),则不会续期
@Test
void testWatchDog() {
RLock lock = redissonClient.getLock("lock");
try {
// 只有一个线程能获取到锁(超时时间设置为-1)
if (lock.tryLock(0, -1, TimeUnit.MILLISECONDS)) {
// todo 实际要执行的代码
Thread.sleep(300000);
System.out.println("getLock: " + Thread.currentThread().getId());
}
} catch (InterruptedException e) {
System.out.println(e.getMessage());
} finally {
// 只能释放自己的锁
if (lock.isHeldByCurrentThread()) {
System.out.println("unLock: " + Thread.currentThread().getId());
lock.unlock();
}
}
}分布式锁主从一致性
联锁机制:获取所有的节点都获取到锁才算成功。

业务实现:

Redis优化秒杀
优化秒杀思路
优化流程:使用异步操作提高吞吐量。
- 先利用Redis完成库存余量、一人一单判断,完成抢单业务
- 再将下单业务放入阻塞队列,利用独立线程异步下单
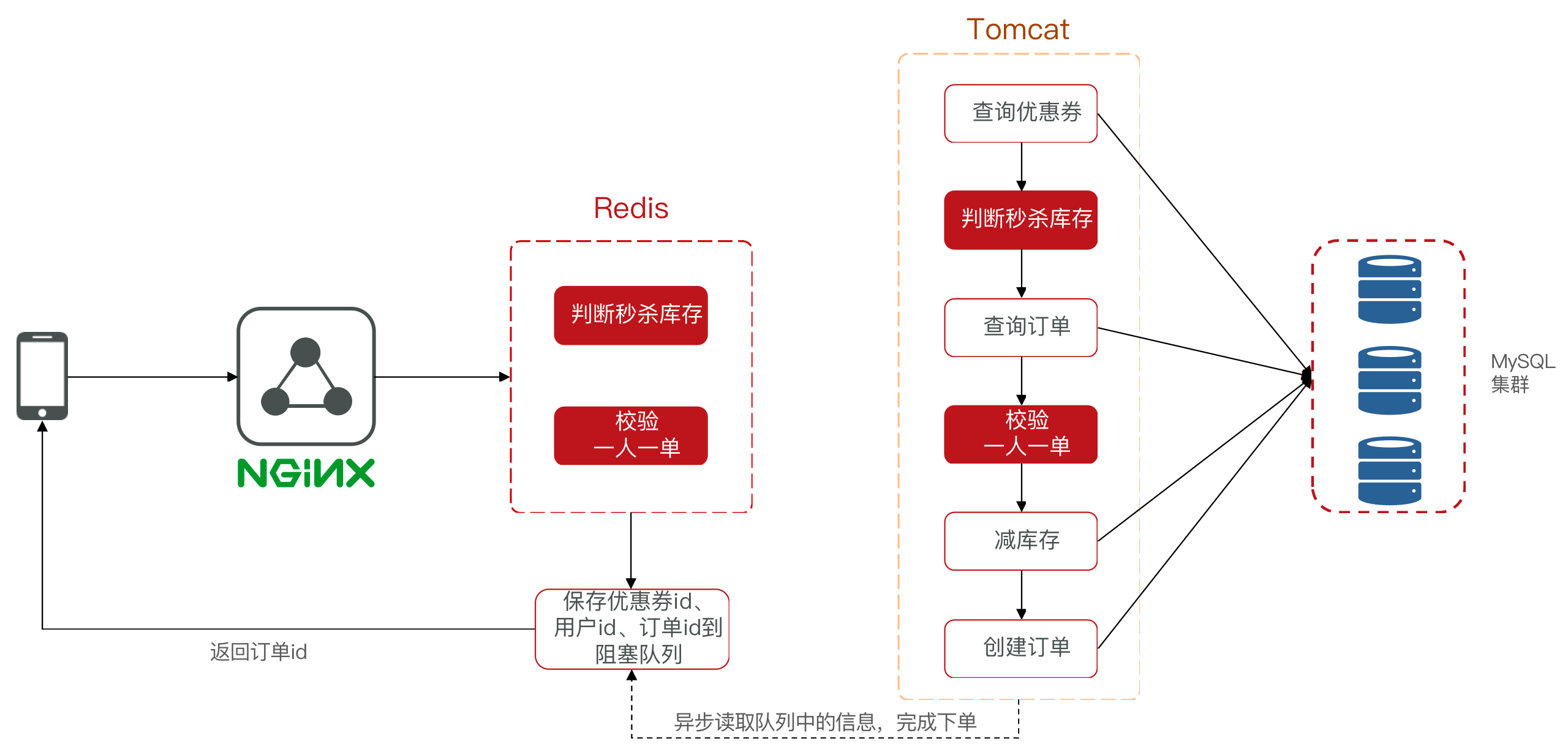
使用Redis存储秒杀库存数量和“一人一单”的订单信息,使用Lua脚本实现原子操作。
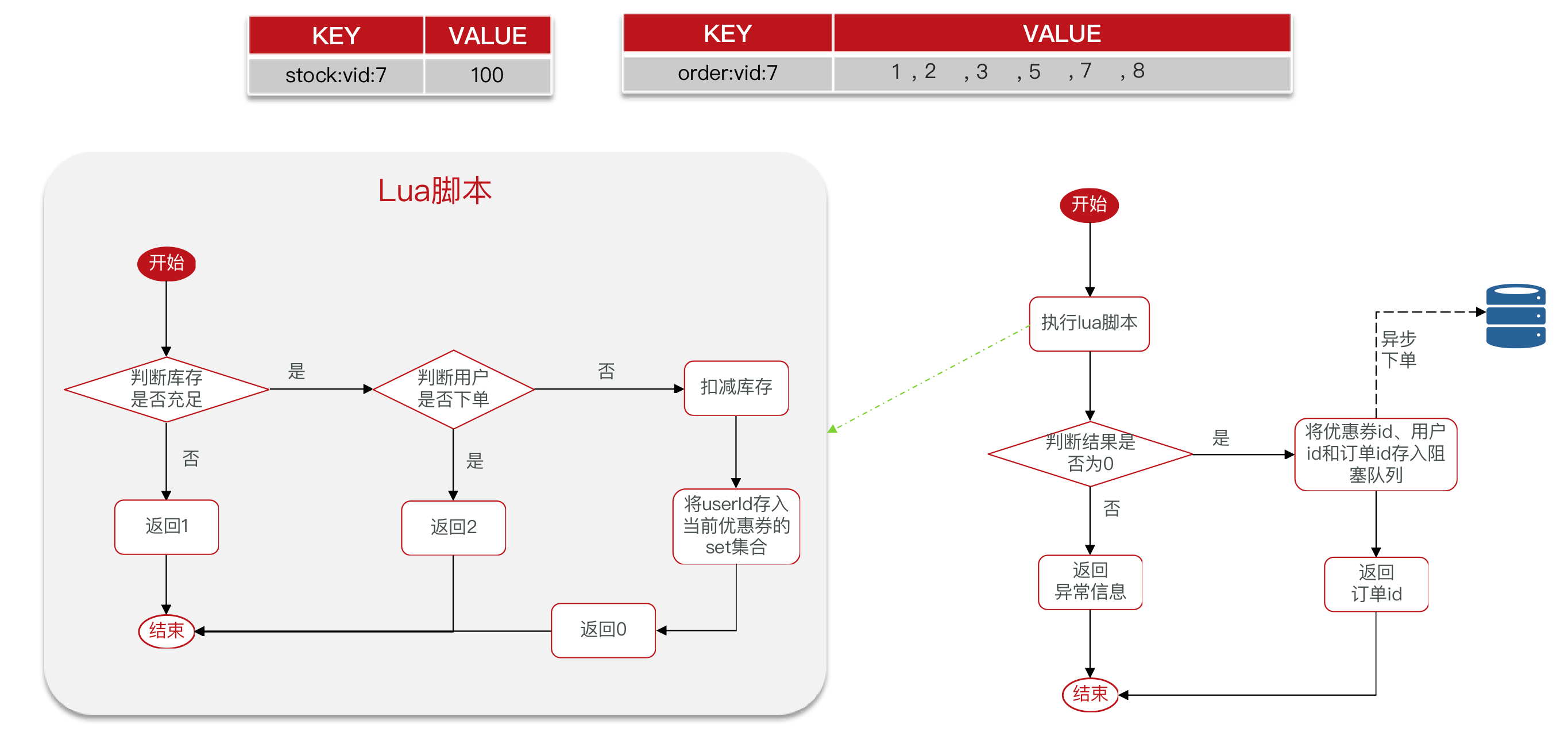
使用Lua脚本实现秒杀
使用lua脚本实现原子性
-- 参数
local productID = ARGV[1]
local userID = ARGV[2]
-- 数据
local productKey = 'product:num:' .. productID
local orderKey = "product:order" .. productID
-- 业务
-- 库存判断
if tonumber(redis.call('get', productKey)) <= 0 then
return 1
end
-- 是否下单过
if redis.call('sismember', orderKey, userID) == 1 then
return 2
end
redis.call('incrby', productKey, -1)
redis.call('sadd', orderKey, userID)
return 0执行lua脚本完成下单
@Override
public String getProductOnlyOneByRedis2(Long id) {
DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>();
redisScript.setLocation(new ClassPathResource("lua/shop.lua"));
Long success = redisTemplate
.execute(redisScript, Collections.emptyList(), id,
UserHolder.getUser().getPhone());
if (success == null || success != 0) {
throw new BusinessException(400, "下单失败");
}
Long orderID = idUtil.getID("order");
// todo 保存到阻塞队列
return orderID.toString();
}模拟创建订单
@Test
void addProduct() {
Product pro = new Product();
pro.setProductName("yixuan");
pro.setNum(10);
boolean success = productService.save(pro);
String key = "RedisSessionDemo:productNum:" + pro.getId();
String value = pro.getNum().toString();
if (success) {
stringRedisTemplate.opsForValue().set(key, value);
}
Assertions.assertNotNull(stringRedisTemplate.opsForValue().get(key));
}基于阻塞队列实现异步下单
private static final DefaultRedisScript<Long> redisScript;
static {
redisScript = new DefaultRedisScript<>();
redisScript.setLocation(new ClassPathResource("lua/shop.lua"));
redisScript.setResultType(Long.class);
}
private BlockingQueue<Ordertable> orderTasks =
new ArrayBlockingQueue<>(1024 * 1024);
private static final ExecutorService SHOP_ORDER_EXECUTOR =
Executors.newSingleThreadExecutor();
@PostConstruct
private void init() {
SHOP_ORDER_EXECUTOR.submit(new OrderHandler());
}
private class OrderHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 获取队列
Ordertable order = orderTasks.take();
// 库存 - 1
boolean success = update().setSql("num = num - 1")
.eq("id", order.getProductID())
.gt("num", 0)
.update();
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(order);
} catch (Exception e) {
log.error("", e);
}
}
}
}
@Override
public String getProductOnlyOneByRedis2(Long id) {
// 执行lua脚本
String userPhone = UserHolder.getUser().getPhone();
Long success = redisTemplate.execute(
redisScript,Collections.emptyList(), id.toString(), userPhone);
if (success == null || success != 0) {
throw new BusinessException(400, "下单失败");
}
// 创建订单
Long orderID = idUtil.getID("order");
Ordertable order = new Ordertable();
order.setOrderID(orderID.toString());
order.setProductID(Math.toIntExact(id));
order.setUserID(userPhone);
// 保存到阻塞队列
orderTasks.add(order);
return orderID.toString();
}Redis消息队列
什么是消息队列
消息队列(Message Queue):存放消息的队列。
最简单的消息队列模型包括3个角色:
- 消息队列:存储和管理消息,也被称为消息代理(Message Broker)
- 生产者:发送消息到消息队列
- 消费者:从消息队列获取消息并处理消息
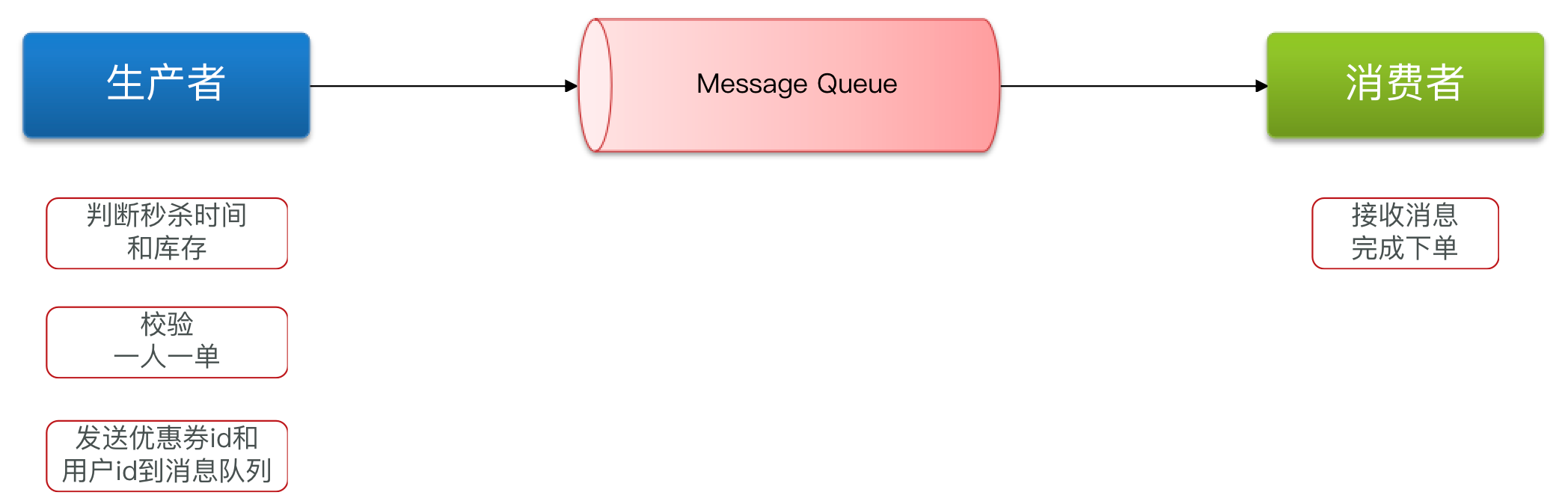
使用List模拟MQ
Redis的list数据结构是一个双向链表,很容易模拟出队列效果。
队列是入口和出口不在一边,因此我们可以利用:LPUSH 结合 RPOP、或者 RPUSH 结合 LPOP来实现。
当队列中没有消息时RPOP或LPOP操作会返回null,并不像JVM的阻塞队列那样会阻塞并等待消息。因此应该使用BRPOP或者BLPOP来实现阻塞效果。

优点:
- 利用Redis存储,不受限于JVM内存上限
- 基于Redis的持久化机制,数据安全性有保证
- 可以满足消息有序性
缺点:
- 无法避免消息丢失
- 只支持单消费者
基于PubSub的MQ
PubSub(发布订阅)是Redis2.0版本引入的消息传递模型。顾名思义,消费者可以订阅一个或多个channel,生产者向对应channel发送消息后,所有订阅者都能收到相关消息。
## 订阅一个或多个频道
SUBSCRIBE channel [channel]
## 向一个频道发送消息
PUBLISH channel msg
## 订阅与pattern格式匹配的所有频道
PSUBSCRIBE pattern[pattern]
优点:
- 采用发布订阅模型,支持多生产、多消费
缺点:
- 不支持数据持久化
- 无法避免消息丢失
- 消息堆积有上限,超出时数据丢失
基于Stream的MQ
Stream 是 Redis 5.0 引入的一种新数据类型,可以实现一个功能非常完善的消息队列。
发送消息的命令:XADD

读取消息:XREAD

① 读取第一个消息
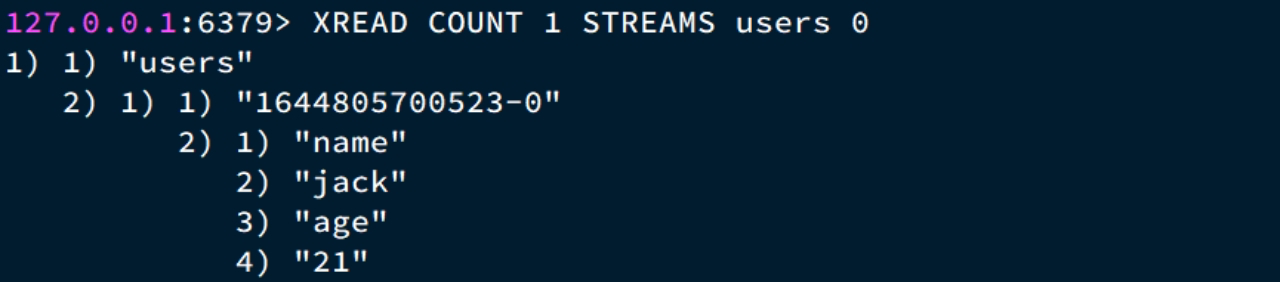
② 阻塞方式读取消息

当我们指定起始ID为$时,代表读取最新的消息,如果我们处理一条消息的过程中,又有超过1条以上的消息到达队列,则下次获取时也只能获取到最新的一条,会出现漏读消息的问题。
STREAM类型消息队列的XREAD命令特点:
- 消息可回溯
- 一个消息可以被多个消费者读取
- 可以阻塞读取
- 有消息漏读的风险
基于Stream消费者组的MQ
消费者组(Consumer Group):将多个消费者划分到一个组中,监听同一个队列。
特点:消息分流、消息标示、消息确认。
创建消费者组:
XGROUP CREATE key groupName ID [MKSTREAM]
## 1. key:队列名称
## 2. groupName:消费者组名称
## 3. ID:起始ID标示,$代表队列中最后一个消息,0则代表队列中第一个消息
## 4. MKSTREAM:队列不存在时自动创建队列其它常见命令:
## 删除指定的消费者组
XGROUP DESTORY key groupName
## 给指定的消费者组添加消费者
XGROUP CREATECONSUMER key groupname consumername
## 删除消费者组中的指定消费者
XGROUP DELCONSUMER key groupname consumername从消费者组读取消息:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
## 1. group:消费组名称
## 2. consumer:消费者名称,如果消费者不存在,会自动创建一个消费者
## 3. count:本次查询的最大数量
## 4. BLOCK milliseconds:当没有消息时最长等待时间
## 5. NOACK:无需手动ACK,获取到消息后自动确认
## 6. STREAMS key:指定队列名称
## 7. ID:获取消息的起始ID:
## 7.1. ">":从下一个未消费的消息开始
## 7.2. 其它:根据指定id从pending-list中获取已消费但未确认的消息,例如0,是从pending-list中的第一个消息开始消费者监听消息的基本思路
while (true) {
//尝试监听队列,使用阻塞模式,最长等待2000毫秒
Object msg = redis.call(
"XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS s1 >");
if (msg == null) {
//null说明设有消息,继续下一次
continue;
}
try {
//处理消息,完成后一定要ACK
handleMessage(msg);
} catch (Exception e) {
while (true) {
Object msg2 = redis.call(
"XREADGROUP GROUP g1 c1 COUNT 1 STREAMS s1 0");
if (msg2 == null) {
//null说明没有异常消息,所有消息都已确以,结束循环
break;
}
try {
//说明有异常消息,再次处理
handleMessage(msg2);
} catch (Exception e) {
//再次出现异常,记录日志,继续循环
continue;
}
}
}
}STREAM类型消息队列的XREADGROUP命令特点:
- 消息可回溯
- 可以多消费者争抢消息,加快消费速度
- 可以阻塞读取
- 没有消息漏读的风险
- 有消息确认机制,保证消息至少被消费一次
三种MQ实现方式对比
| List | PubSub | Stream | |
|---|---|---|---|
| 消息持久化 | 支持 | 不支持 | 支持 |
| 阻塞读取 | 支持 | 支持 | 支持 |
| 消息堆积处理 | 受限于内存空间,可以利用多消费者加快处理 | 受限于消费者缓冲区 | 受限于队列长度,可以利用消费者组提高消费速度,减少堆积 |
| 消息确认机制 | 不支持 | 不支持 | 支持 |
| 消息回溯 | 不支持 | 不支持 | 支持 |
使用基于Stream的MQ优化秒杀
修改Lua脚本创建stream消息队列
-- 参数
local productID = ARGV[1]
local userID = ARGV[2]
local orderID = ARGV[3]
-- 数据
local productKey = 'RedisSessionDemo:productNum:' .. productID
local orderKey = "RedisSessionDemo:productOrder:" .. productID
-- 业务
-- 库存判断
if tonumber(redis.call('get', productKey)) <= 0 then
return 1
end
-- 是否下单过
if redis.call('sismember', orderKey, userID) == 1 then
return 2
end
redis.call('incrby', productKey, -1)
redis.call('sadd', orderKey, userID)
-- 下单
redis.call('xadd', 'stream.orders', '*',
'orderID', orderID, 'userID', userID, 'productID', productID)
return 0执行Lua脚本下单
private static final DefaultRedisScript<Long> StreamScript;
static {
StreamScript = new DefaultRedisScript<>();
StreamScript.setLocation(new ClassPathResource("lua/shop-stream.lua"));
StreamScript.setResultType(Long.class);
}
@Override
public String getProductOnlyOneByStream(Long id) {
String userPhone = UserHolder.getUser().getPhone();
Long orderID = idUtil.getID("order");
Long success = redisTemplate.execute(
StreamScript, Collections.emptyList(), id, userPhone, orderID);
if (success == null || success != 0) {
throw new BusinessException(400, "下单失败");
}
return orderID.toString();
}使用多线程读取MQ的信息
private static final ExecutorService SHOP_ORDER_EXECUTOR = Executors.newSingleThreadExecutor();
@PostConstruct
private void init() {
SHOP_ORDER_EXECUTOR.submit(new StreamHandler());
}
private class StreamHandler implements Runnable {
@Override
public void run() {
while (true) {
try {
// 获取stream
// XREADGROUP GROUP g1 c1 COUNT 1 BLOCK 2000 STREAMS stream.order >
List<MapRecord<String, Object, Object>> list =
redisTemplate.opsForStream().read(Consumer.from("g1", "c1"), StreamReadOptions.empty().count(1).block(Duration.ofSeconds(2)),StreamOffset.create("stream.order", ReadOffset.lastConsumed())
);
if (list == null || list.isEmpty()) {
// 没有消息
continue;
}
// 解析消息
Map<Object, Object> values = list.get(0).getValue();
Ordertable order = BeanUtil.fillBeanWithMap(
values, new Ordertable(), true);
// 库存 - 1
boolean success = update().setSql("num = num - 1")
.eq("id", order.getProductID())
.gt("num", 0)
.update();
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(order);
// ACK 确认
redisTemplate.opsForStream().acknowledge(
"stream.order","g1", list.get(0).getId());
} catch (Exception e) {
while (true) {
try {
// 读取 pending-list
List<MapRecord<String, Object, Object>> pendingList = redisTemplate.opsForStream()
.read(
Consumer.from("g1", "c1"),
StreamReadOptions.empty().count(1),
StreamOffset.create(
"stream.order", ReadOffset.from("0"))
);
if (pendingList == null) {
// pendingList 为空 -> 结束循环
break;
}
// 解析消息
Map<Object, Object> values =
pendingList.get(0).getValue();
Ordertable order = BeanUtil.fillBeanWithMap(
values, new Ordertable(), true);
// 库存 - 1
boolean success = update().setSql("num = num - 1")
.eq("id", order.getProductID())
.gt("num", 0)
.update();
if (!success) {
throw new BusinessException(400, "下单失败");
}
// 保存订单
ordertableService.save(order);
// ACK 确认
redisTemplate.opsForStream()
.acknowledge("stream.order","g1",
pendingList.get(0).getId());
} catch (Exception excp) {
log.error("", excp);
}
}
}
}
}好友关注
关注与取关
数据库设计
创建数据库表,保存关注信息
create table follow
(
id int auto_increment
primary key,
userID int null comment '用户id',
followID int null comment '博主id',
idDeleted int default 0 null,
createdTime timestamp default CURRENT_TIMESTAMP null,
constraint id
unique (id)
);查询关注状态
public Boolean getFollow(Long followId) {
String phone = UserHolder.getUser().getPhone();
User user = userMapper.selectOne(new QueryWrapper<User>().eq("phone", phone));
Integer userID = user.getId();
return followMapper.exists(
new QueryWrapper<Follow>().eq("followID", followId).eq("userID", userID)
);
}关注与取关
public Boolean setFollow(Long id) {
String phone = UserHolder.getUser().getPhone();
User user = userMapper
.selectOne(new QueryWrapper<User>().eq("phone", phone));
Integer userID = user.getId();
boolean isFollowed = followMapper.exists(
new QueryWrapper<Follow>()
.eq("followID", id).eq("userID", userID)
);
if (isFollowed) {
// 取关
followMapper.delete(new QueryWrapper<Follow>()
.eq("followID", id).eq("userID", userID));
return false;
}
// 关注
Follow f = new Follow();
f.setUserID(userID);
f.setFollowID(Math.toIntExact(id));
followMapper.insert(f);
return true;
}共同关注
优化关注
关注过程中,在redis维护一个set集合存放关注列表。通过set取交集的方式查询共同关注。
public Boolean setFollow(Long id) {
String phone = UserHolder.getUser().getPhone();
User user = userMapper.selectOne(new QueryWrapper<User>().eq("phone", phone));
Integer userID = user.getId();
boolean isFollowed = followMapper.exists(
new QueryWrapper<Follow>().eq("followID", id).eq("userID", userID)
);
if (isFollowed) {
// 取关
followMapper.delete(new QueryWrapper<Follow>().eq("followID", id).eq("userID", userID));
redisTemplate.opsForSet().remove("RedisSessionDemo:follow:" + userID, String.valueOf(id));
return false;
}
// 关注
Follow f = new Follow();
f.setUserID(userID);
f.setFollowID(Math.toIntExact(id));
followMapper.insert(f);
redisTemplate.opsForSet().add("RedisSessionDemo:follow:" + userID, String.valueOf(id));
return true;
}共同关注
public List<UserDTO> getCommonFollow(Long followID) {
String phone = UserHolder.getUser().getPhone();
User user = userMapper.selectOne(new QueryWrapper<User>().eq("phone", phone));
Integer userID = user.getId();
Set<String> commonIds = redisTemplate.opsForSet().intersect("RedisSessionDemo:follow:" + userID, "RedisSessionDemo:follow:" + followID);
if (commonIds == null) {
return null;
}
List<User> commonUser = userMapper.selectBatchIds(commonIds);
ArrayList<UserDTO> results = new ArrayList<>();
commonUser.forEach(u -> results.add(BeanUtil.copyProperties(u, UserDTO.class)));
return results;
}关注推送
Feed流
关注推送也叫做Feed流,直译为投喂。为用户持续的提供“沉浸式”的体验,通过无限下拉刷新获取新的信息。
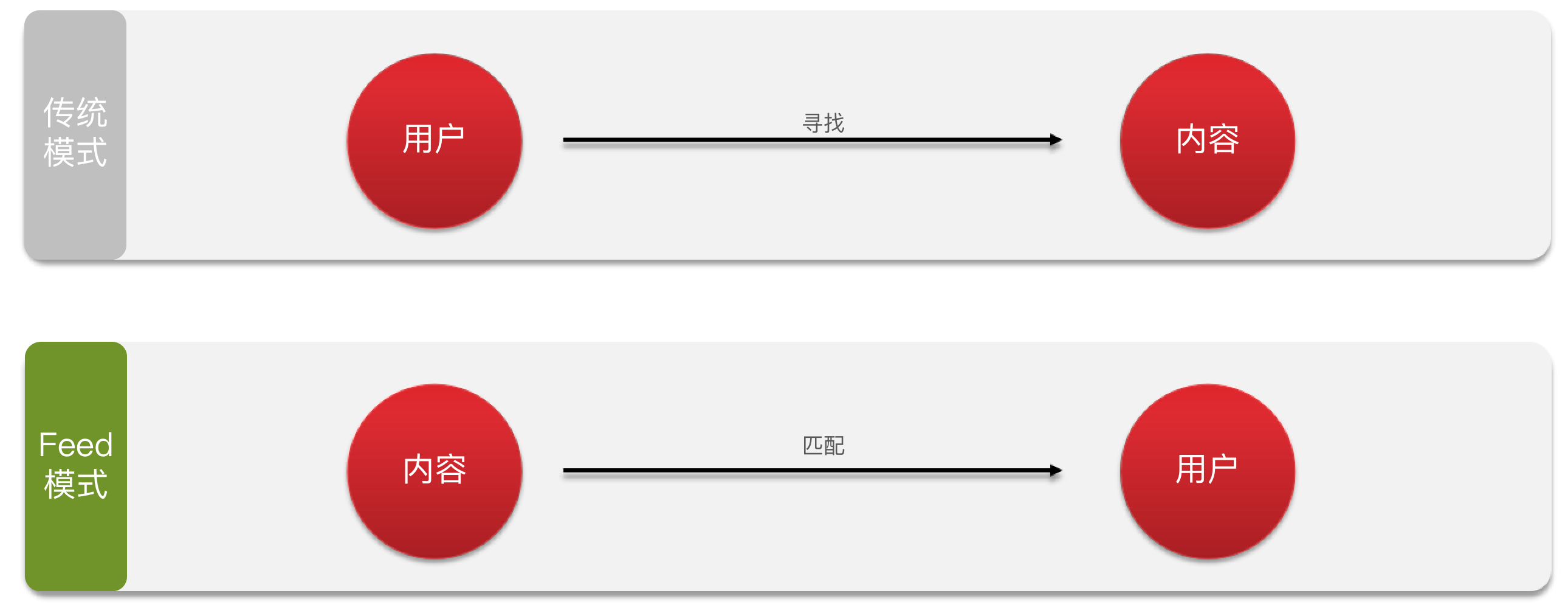
Feed流实现方案
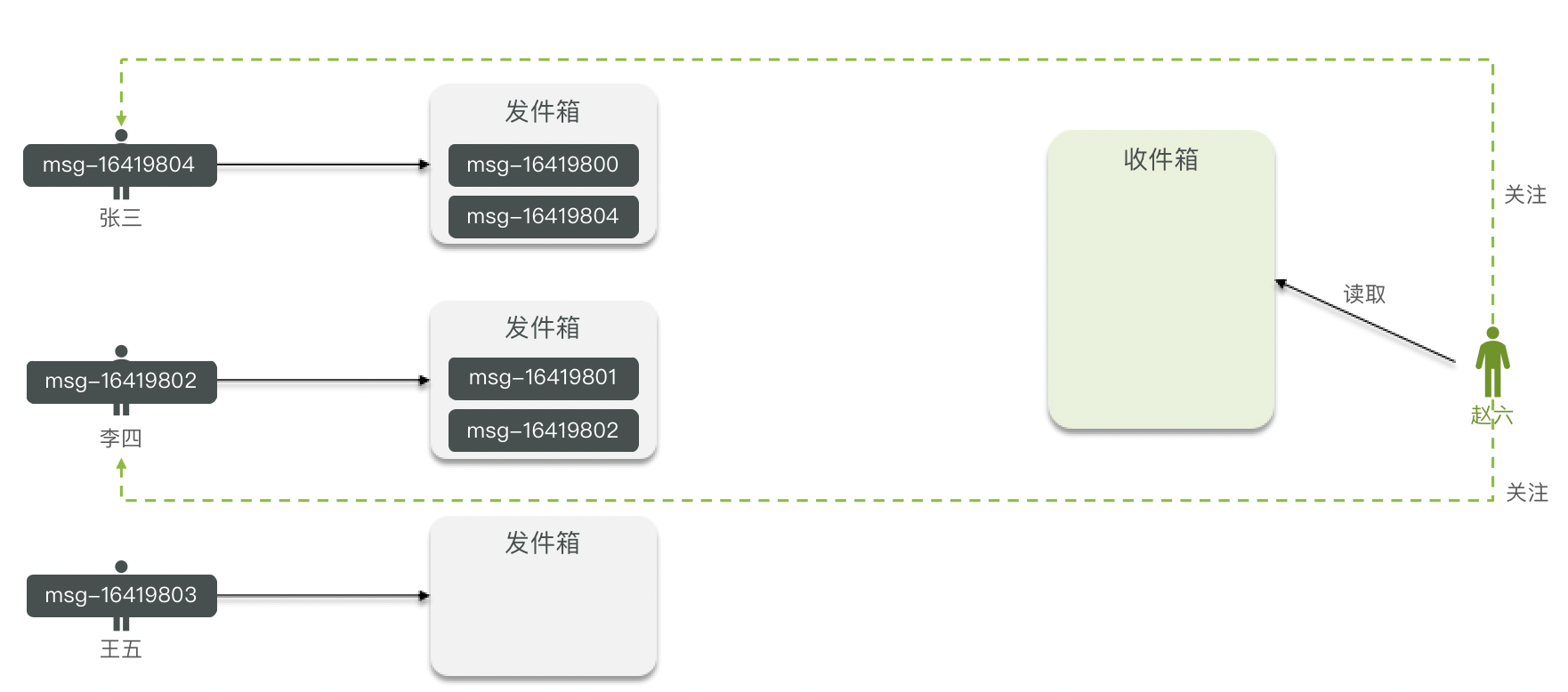
拉模式
拉模式:也叫做读扩散。
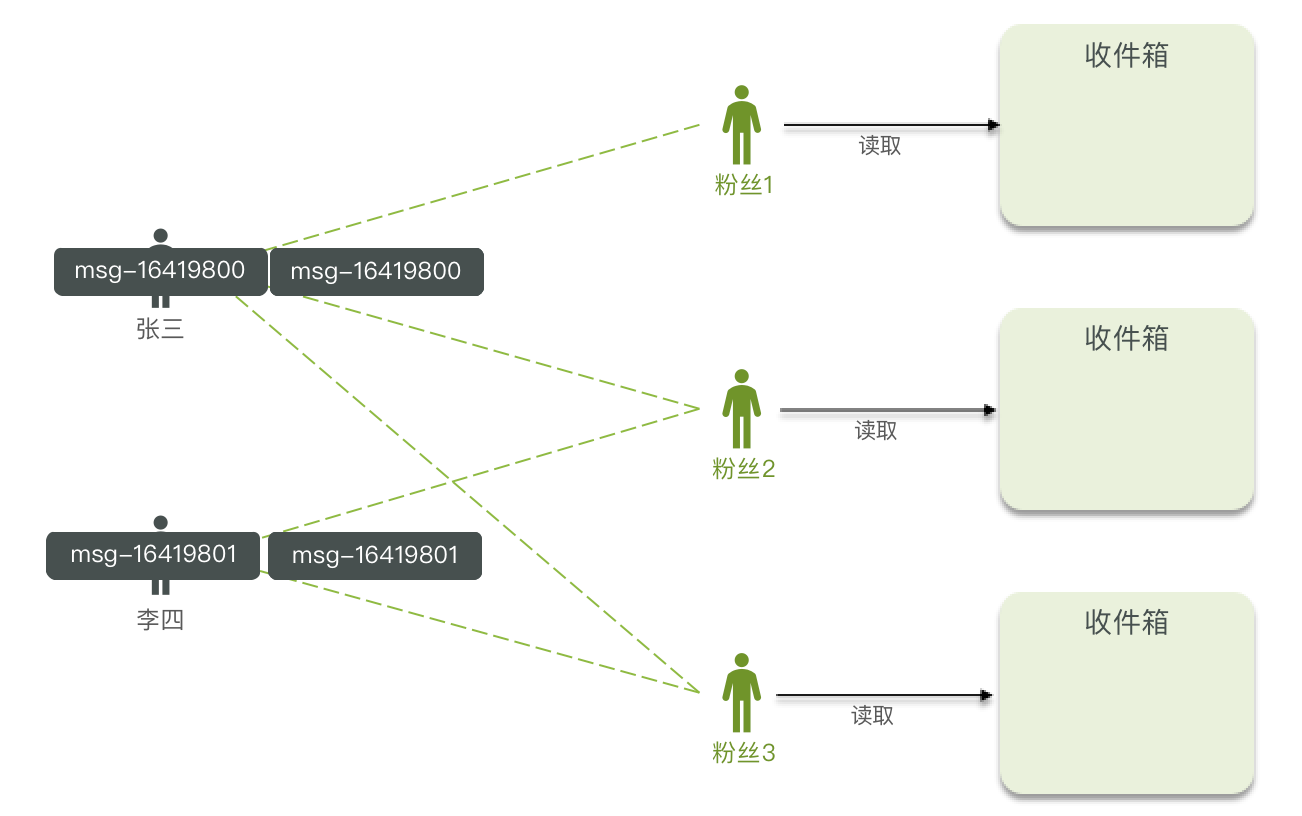
推模式
推模式:也叫做写扩散。
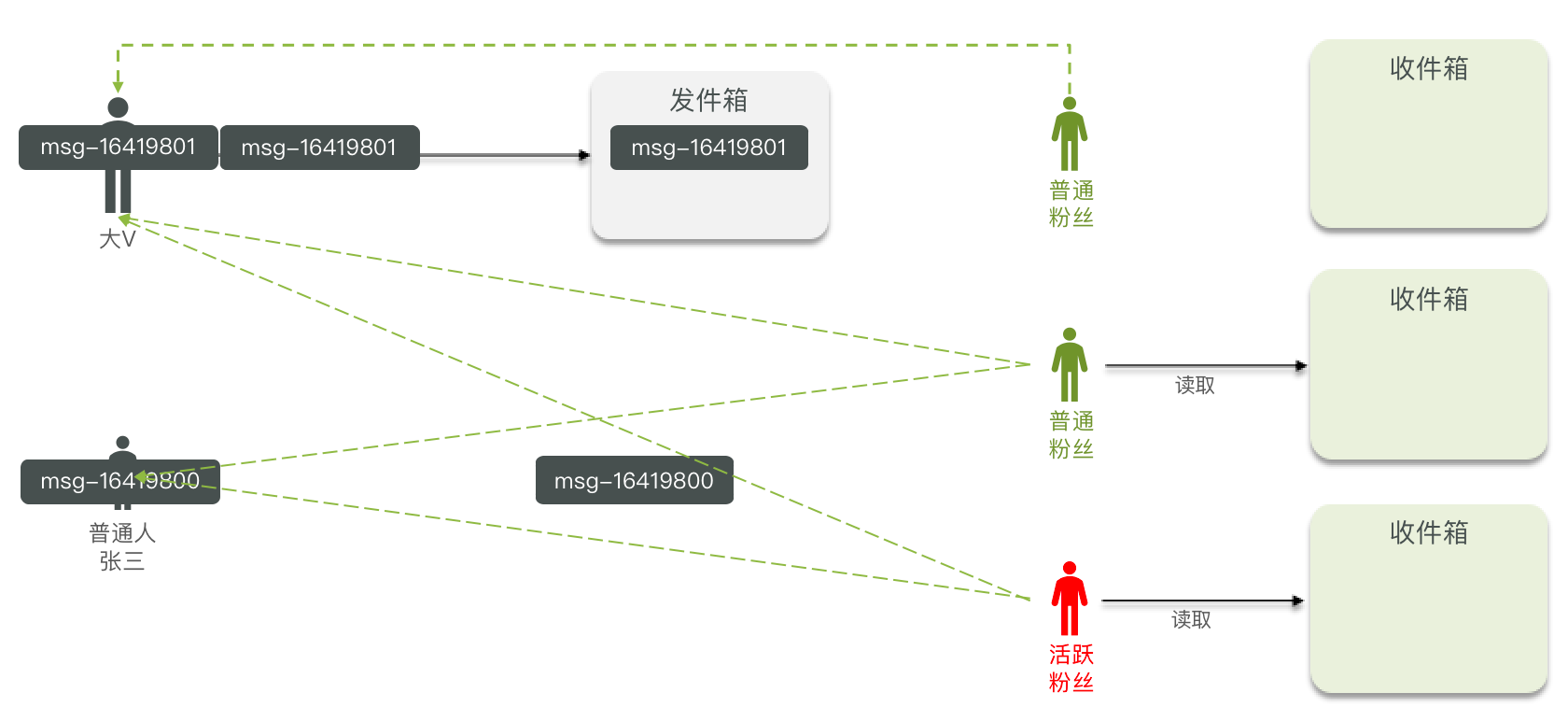
推拉结合模式
推拉结合模式:也叫做读写混合,兼具推和拉两种模式的优点。
实现方式对比
| 拉模式 | 推模式 | 推拉结合 | |
|---|---|---|---|
| 写比例 | 低 | 高 | 中 |
| 读比例 | 高 | 低 | 中 |
| 用户读取延迟 | 高 | 低 | 低 |
| 实现难度 | 复杂 | 简单 | 很复杂 |
| 使用场景 | 很少使用 | 用户量少、没有大V | 过千万的用户量,有大V |
签到点赞和UV统计
点赞
点赞功能分析
需求:
- 同一个用户只能点赞一次,再次点击则取消点赞
- 如果当前用户已经点赞,则点赞按钮高亮显示(前端判断字段isLike属性)
实现步骤:
- 利用Redis的set集合判断是否点赞过,将用户id保存到set中
- 判断当前登录用户是否点赞过,赋值给isLike字段
- 通过Redis的set集合中Scard命令获取成员个数,即点赞次数
业务实现
LikedDTO
@Data
@AllArgsConstructor
@NoArgsConstructor
public class LikedDTO {
/**
* 点赞数量
*/
long likedSum;
/**
* 用户是否点过赞
*/
Boolean isLiked;
}点赞操作
// 点赞操作
@Override
public String doLike() {
String key = "RedisSessionDemo:liked";
String phone = UserHolder.getUser().getPhone();
// 查询是否点赞过
Boolean isLiked = redisTemplate.opsForSet().isMember(key, phone);
if (BooleanUtil.isTrue(isLiked)) {
// 点赞过 -> 取消点赞
redisTemplate.opsForSet().remove(key, phone);
return "取消点赞成功";
}
// 没点赞过 -> 点赞
redisTemplate.opsForSet().add(key, phone);
return "点赞成功";
}获取点赞数据
// 获取点赞数据
@Override
public LikedDTO getLiked() {
String key = "RedisSessionDemo:liked";
Long likedNum = redisTemplate.opsForSet().size(key);
if (likedNum == null) {
likedNum = 0L;
}
UserDTO user = UserHolder.getUser();
Boolean isLiked = false;
if (user != null) {
isLiked = redisTemplate.opsForSet().isMember(key, user.getPhone());
}
return new LikedDTO(likedNum, isLiked);
}点赞排行
功能分析
点赞排行:类似朋友圈的点赞列表,按照点赞的先后顺序展示头像等信息。
使用 sorted set 结构,将点赞的时间戳作为分数值记录。
功能实现
修改点赞函数
// 获取点赞数据
@Override
public LikedDTO getLiked2() {
String key = "RedisSessionDemo:liked";
Long likedNum = redisTemplate.opsForZSet().size(key);
if (likedNum == null) {
likedNum = 0L;
}
UserDTO user = UserHolder.getUser();
boolean isLiked = false;
if (user != null) {
Double score = redisTemplate.opsForZSet().score(key, user.getPhone());
isLiked = (score != null && score > 0);
}
return new LikedDTO(likedNum, isLiked);
}
// 点赞操作
@Override
public String doLike2() {
String key = "RedisSessionDemo:liked";
String phone = UserHolder.getUser().getPhone();
// 查询是否点赞过
Double isLiked = redisTemplate.opsForZSet().score(key, phone);
if (isLiked != null && isLiked > 0) {
// 点赞过 -> 取消点赞
redisTemplate.opsForZSet().remove(key, phone);
return "取消点赞成功";
}
// 没点赞过 -> 点赞
redisTemplate.opsForZSet().add(key, phone, System.currentTimeMillis());
return "点赞成功";
}获取点赞列表
// 获取点赞列表
@Override
public List<String> getLikedList() {
String key = "RedisSessionDemo:liked";
// 获取所有元素
Set<String> set = redisTemplate.opsForZSet().range(key, 0, -1);
if (set != null) {
return new ArrayList<>(set);
}
return Collections.emptyList();
}用户签到
BitMap用法
我们按月来统计用户签到信息,签到记录为1,未签到则记录为0。

把每一个bit位对应当月的每一天,形成了映射关系。用0和1标示业务状态,这种思路就称为位图(BitMap)。
Redis中是利用string类型数据结构实现BitMap,因此最大上限是512M,转换为bit则是
BitMap的操作命令有:
- SETBIT:向指定位置(offset)存入一个0或1
- GETBIT :获取指定位置(offset)的bit值
- BITCOUNT :统计BitMap中值为1的bit位的数量
- BITFIELD :操作(查询、修改、自增)BitMap中bit数组中的指定位置(offset)的值
- BITFIELD_RO :获取BitMap中bit数组,并以十进制形式返回
- BITOP :将多个BitMap的结果做位运算(与 、或、异或)
- BITPOS :查找bit数组中指定范围内第一个0或1出现的位置
实现签到功能
因为BitMap底层是基于String数据结构,因此其操作也都封装在字符串相关操作中了。

public Boolean sign() {
String phone = UserHolder.getUser().getPhone();
Date date = new Date();
String yearAndMonth = new SimpleDateFormat("yyyy:MM").format(date);
String key = "RedisSessionDemo:user:sign:" + phone + ":" + yearAndMonth;
int day = Integer.parseInt(new SimpleDateFormat("DD").format(date));
// 实现签到
redisTemplate.opsForValue().setBit(key, day, true);
return true;
}签到统计
连续签到:从最后一次签到开始向前统计,直到遇到第一次未签到为止的签到次数

封装SignData类
@Data
@AllArgsConstructor
@NoArgsConstructor
public class SignData {
// 月签到次数
Integer MonthTimes;
// 月连续签到次数
Integer ContinuousTimes;
}业务实现
@Override
public SignData signdata() {
// 获取 bitmap
String phone = UserHolder.getUser().getPhone();
Date date = new Date();
String yearAndMonth = new SimpleDateFormat("yyyy:MM").format(date);
String key = "RedisSessionDemo:user:sign:" + phone + ":" + yearAndMonth;
int day = Integer.parseInt(new SimpleDateFormat("DD").format(date));
List<Long> list = redisTemplate.opsForValue().bitField(key, BitFieldSubCommands.create().get(BitFieldSubCommands.BitFieldType.unsigned(day + 1)).valueAt(0));
if (list == null || list.isEmpty()) {
return new SignData(0, 0);
}
Long sign = list.get(0);
if (sign == null) {
return new SignData(0, 0);
}
// 统计计算
int MonthTimes = 0;
int ContinuousTimes = 0;
boolean isContinuous = true;
while (sign != 0) {
// 连续签到
if (isContinuous) {
if ((sign & 1) == 1) {
ContinuousTimes++;
} else {
isContinuous = false;
}
}
// 月签到次数
if ((sign & 1) == 1) {
MonthTimes++;
}
sign = sign >> 1;
}
return new SignData(MonthTimes, ContinuousTimes);
}
UV统计
HyperLogLog
- UV:全称Unique Visitor,也叫独立访客量,是指通过互联网访问、浏览这个网页的自然人。1天内同一个用户多次访问该网站,只记录1次。
- PV:全称Page View,也叫页面访问量或点击量,用户每访问网站的一个页面,记录1次PV,用户多次打开页面,则记录多次PV。往往用来衡量网站的流量。
UV统计在服务端做会比较麻烦,因为要判断该用户是否已经统计过了,需要将统计过的用户信息保存。但是如果每个访问的用户都保存到Redis中,数据量会非常恐怖。
Hyperloglog(HLL)是从Loglog算法派生的概率算法,用于确定非常大的集合的基数,而不需要存储其所有值。相关算法
Redis中的HLL是基于string结构实现的,单个HLL的内存永远小于16kb,内存占用低的令人发指!
作为代价,其测量结果是概率性的,有小于0.81%的误差。不过对于UV统计来说,这完全可以忽略。
- 作用:做海量数据的统计工作
- 优点:内存占用极低、性能非常好
- 缺点:有一定的误差
业务实现
@Test
void hyperlogTest() {
for (int i = 0; i < 100; i++) {
stringRedisTemplate.opsForHyperLogLog().add("hyperlogTest", "user-" + i);
}
Long size = stringRedisTemplate.opsForHyperLogLog().size("hyperlogTest");
System.out.println(size);
}
位置相关操作
GEO数据结构
GEO就是Geolocation的简写形式,代表地理坐标。
常见的命令有:
- GEOADD:添加一个地理空间信息,包含:经度(longitude)、纬度(latitude)、值(member)
- GEODIST:计算指定的两个点之间的距离并返回
- GEOHASH:将指定member的坐标转为hash字符串形式并返回
- GEOPOS:返回指定member的坐标
- GEOSEARCH:在指定范围内搜索member,并按照与指定点之间的距离排序后返回。范围可以是圆形或矩形。
- GEOSEARCHSTORE:与GEOSEARCH功能一致,不过可以把结果存储到一个指定的key。
与北京站之间的距离
向redis中添加北京站坐标
@Test
void test1() {
// 北京站: 116.42803 39.903738
double x = 116.42803;
double y = 39.903738;
String key = "RedisSessionDemo:geo";
Long isSuccess = stringRedisTemplate.opsForGeo()
.add(key, new Point(x, y), "beijingStation");
System.out.println(isSuccess);
}计算与北京站之间的距离
public Double getDistance(Double x, Double y) {
String key = "RedisSessionDemo:geo";
stringRedisTemplate.opsForGeo().add(key, new Point(x, y), "temp");
Distance distance = stringRedisTemplate.opsForGeo()
.distance(key, "temp", "beijingStation");
stringRedisTemplate.opsForGeo().remove(key, "temp");
if (distance == null) {
return -1.0;
}
return distance.getValue();
}查看附近的火车站
预先添加北京三个火车站坐标
@Test
void test3() {
String key = "RedisSessionDemo:geo";
// 北京站: 116.42803 39.903738
stringRedisTemplate.opsForGeo()
.add(key, new Point(116.42803, 39.903738), "北京站");
// 北京南站: 116.378248 39.865275
stringRedisTemplate.opsForGeo()
.add(key, new Point(116.378248, 39.865275), "北京南站");
// 北京西站: 116.322287 39.893729
stringRedisTemplate.opsForGeo()
.add(key, new Point(116.322287, 39.893729), "北京西站");
}查询附近的火车站
@Data
@AllArgsConstructor
@NoArgsConstructor
public class GEODTO {
String name;
double distance;
}@Override
public List<GEODTO> nearbyStation(Double x, Double y) {
String key = "RedisSessionDemo:geo";
stringRedisTemplate.opsForGeo().add(key, new Point(x, y), "temp");
GeoResults<RedisGeoCommands.GeoLocation<String>> geoResults = stringRedisTemplate.opsForGeo().search(key, GeoReference.fromCoordinate(x, y), new Distance(100 * 1000), RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance());
List<GEODTO> result = new ArrayList<>();
if (geoResults != null) {
geoResults.getContent().stream().skip(1).forEach(item -> {
String name = item.getContent().getName();
double distance = item.getDistance().getValue();
result.add(new GEODTO(name, distance));
});
}
return result;
} ## 分布式缓存
## 分布式缓存
单点 Redis 的问题
- 数据丢失(持久化)
- 并发能力不如集群(主从集群、读写分离)
- Redis宕机导致服务不可用(Redis哨兵)
- 存储能力差(分片集群)
Redis 持久化
RDB 持久化
什么是RDB
RDB (Redis Database Backup file):数据快照
默认保存在运行目录
## 主进程保存快照(阻塞)
save
## 子进程保存快照
bgsaveRedis 停机时会执行一次RDB。

RDB 触发机制
在 redis.conf 中配置
## 900秒内,如果至少有1个key被修改,则执行bgsave
## 如果是 save "" 则表示禁用RDB
save 900 1
save 300 10
save 60 10000
## 是否压缩:建议不开启,压缩也会消耗cpu,磁盘的话不值钱
rdbcompression yes
## RDB文件名称
dbfilename dump.rdb
## 文件保存的路径目录
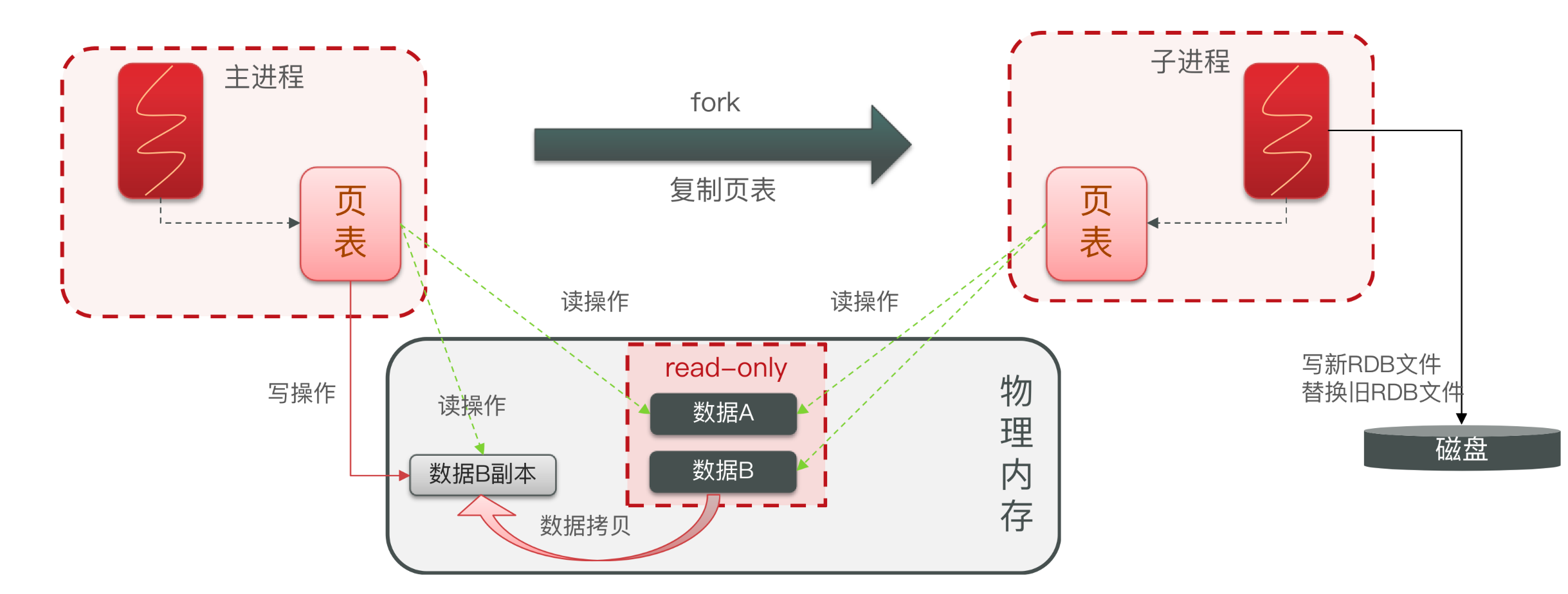
dir ./RDB 原理
- fork主进程得到一个子进程,共享内存空间
- 子进程读取内存数据并写入新的RDB文件
- 用新RDB文件替换旧的RDB文件。
fork采用的是copy-on-write技术:
- 当主进程执行读操作时,访问共享内存;
- 当主进程执行写操作时,则会拷贝一份数据,执行写操作。
AOF 持久化
什么是AOF
AOF (Append Only File):命令日志

AOF 配置
AOF默认是关闭的,需要在 redis.conf 中配置
## 是否开启AOF功能,默认是no
appendonly yes
## AOF文件的名称
appendfilename "appendonly.aof"在 redis.conf 中配置命令记录的频率(刷盘时机)
## 表示每执行一次写命令,立即记录到AOF文件
appendfsync always
## 写命令执行完先放入AOF缓冲区,然后表示每隔1秒将缓冲区数据写到AOF文件,是默认方案
appendfsync everysec
## 写命令执行完先放入AOF缓冲区,由操作系统决定何时将缓冲区内容写回磁盘
appendfsync no| 配置项 | 刷盘时机 | 优点 | 缺点 |
|---|---|---|---|
| Always | 同步刷盘 | 可靠性高,几乎不丢数据 | 性能影响大 |
| everysec | 每秒刷盘 | 性能适中 | 最多丢失1秒数据 |
| no | 操作系统控制 | 性能最好 | 可靠性较差,可能丢失大量数据 |
配置重写AOF文件:执行bgrewriteaof命令,可以让AOF文件执行重写功能

AOF会记录对同一个key的多次写操作,但只有最后一次写操作才有意义
## AOF文件比上次文件 增长超过多少百分比则触发重写
auto-aof-rewrite-percentage 100
## AOF文件体积最小多大以上才触发重写
auto-aof-rewrite-min-size 64mb持久化方式对比
| 持久化方式 | RDB | AOF |
|---|---|---|
| 数据完整性 | 不完整,两次备份之间会丢失 | 相对完整,取决于刷盘策略 |
| 文件大小 | 会有压缩,文件体积小 | 记录命令,文件体积很大 |
| 宕机恢复速度 | 很快 | 慢 |
| 数据恢复优先级 | 低,因为数据完整性不如AOF | 高,因为数据完整性更高 |
| 系统资源占用 | 高,大量CPU和内存消耗 | 低,主要是磁盘IO资源, 但AOF重写时会占用大量CPU和内存资源 |
| 使用场景 | 可以容忍数分钟的数据丢失,追求更快的启动速度 | 对数据安全性要求较高常见 |
Redis 主从集群
搭建主从架构
主从集群:提高并发能力,实现读写分离。
集群结构

共包含三个节点,一个主节点,两个从节点。
这里我们会在同一台虚拟机中开启3个redis实例,模拟主从集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | slave |
| 192.168.150.101 | 7003 | slave |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
1)创建目录
我们创建三个文件夹,名字分别叫7001、7002、7003:
## 进入/tmp目录
cd /tmp
## 创建目录
mkdir 7001 7002 7003如图:
2)恢复原始配置
修改redis-6.2.4/redis.conf文件,将其中的持久化模式改为默认的RDB模式,AOF保持关闭状态。
## 开启RDB
## save ""
save 3600 1
save 300 100
save 60 10000
## 关闭AOF
appendonly no3)拷贝配置文件到每个实例目录
然后将redis-6.2.4/redis.conf文件拷贝到三个目录中(在/tmp目录执行下列命令):
## 方式一:逐个拷贝
cp redis-6.2.4/redis.conf 7001
cp redis-6.2.4/redis.conf 7002
cp redis-6.2.4/redis.conf 7003
## 方式二:管道组合命令,一键拷贝
echo 7001 7002 7003 | xargs -t -n 1 cp redis-6.2.4/redis.conf4)修改每个实例的端口、工作目录
修改每个文件夹内的配置文件,将端口分别修改为7001、7002、7003,将rdb文件保存位置都修改为自己所在目录(在/tmp目录执行下列命令):
sed -i -e 's/6379/7001/g' -e 's/dir .\//dir \/tmp\/7001\//g' 7001/redis.conf
sed -i -e 's/6379/7002/g' -e 's/dir .\//dir \/tmp\/7002\//g' 7002/redis.conf
sed -i -e 's/6379/7003/g' -e 's/dir .\//dir \/tmp\/7003\//g' 7003/redis.conf5)修改每个实例的声明IP
虚拟机本身有多个IP,为了避免将来混乱,我们需要在redis.conf文件中指定每一个实例的绑定ip信息,格式如下:
## redis实例的声明 IP
replica-announce-ip 192.168.150.101每个目录都要改,我们一键完成修改(在/tmp目录执行下列命令):
## 逐一执行
sed -i '1a replica-announce-ip 192.168.150.101' 7001/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7002/redis.conf
sed -i '1a replica-announce-ip 192.168.150.101' 7003/redis.conf
## 或者一键修改
printf '%s\n' 7001 7002 7003 | xargs -I{} -t sed -i '1a replica-announce-ip 192.168.150.101' {}/redis.conf启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
## 第1个
redis-server 7001/redis.conf
## 第2个
redis-server 7002/redis.conf
## 第3个
redis-server 7003/redis.conf启动后:
如果要一键停止,可以运行下面命令:
printf '%s\n' 7001 7002 7003 | xargs -I{} -t redis-cli -p {} shutdown开启主从关系
现在三个实例还没有任何关系,要配置主从可以使用replicaof 或者slaveof(5.0以前)命令。
有临时和永久两种模式:
修改配置文件(永久生效)
- 在redis.conf中添加一行配置:
slaveof <masterip> <masterport>
- 在redis.conf中添加一行配置:
使用redis-cli客户端连接到redis服务,执行slaveof命令(重启后失效):
shslaveof <masterip> <masterport>
注意:在5.0以后新增命令replicaof,与salveof效果一致。
这里我们为了演示方便,使用方式二。
通过redis-cli命令连接7002,执行下面命令:
## 连接 7002
redis-cli -p 7002
## 执行slaveof
slaveof 192.168.150.101 7001通过redis-cli命令连接7003,执行下面命令:
## 连接 7003
redis-cli -p 7003
## 执行slaveof
slaveof 192.168.150.101 7001然后连接 7001节点,查看集群状态:
## 连接 7001
redis-cli -p 7001
## 查看状态
info replication结果:
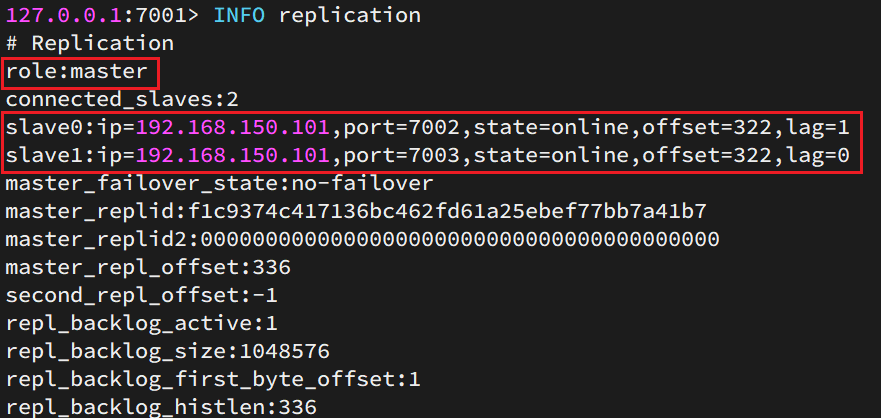
测试
执行下列操作以测试:
利用redis-cli连接7001,执行
set num 123利用redis-cli连接7002,执行
get num,再执行set num 666利用redis-cli连接7003,执行
get num,再执行set num 888
可以发现,只有在7001这个master节点上可以执行写操作,7002和7003这两个slave节点只能执行读操作。
数据主从同步原理
全量同步
主从第一次同步是全量同步
slave 做数据同步,必须向master声明自己的 Replid 和offset,master才可以判断到底需要同步哪些数据
- Replication Id是数据集的身份标识,每个主节点(master)都有一个唯一的标识,而从节点(slave)会继承主节点的标识。通过比较 Replid 可以确定是否同步的是同一个数据集。
- 偏移量(offset)是一个数字,随着数据在备份日志(repl_baklog)中的增加而逐渐增大。从节点在完成数据同步时也会记录当前的偏移量。如果从节点的偏移量小于主节点的偏移量,说明从节点的数据落后于主节点,需要进行数据更新同步。
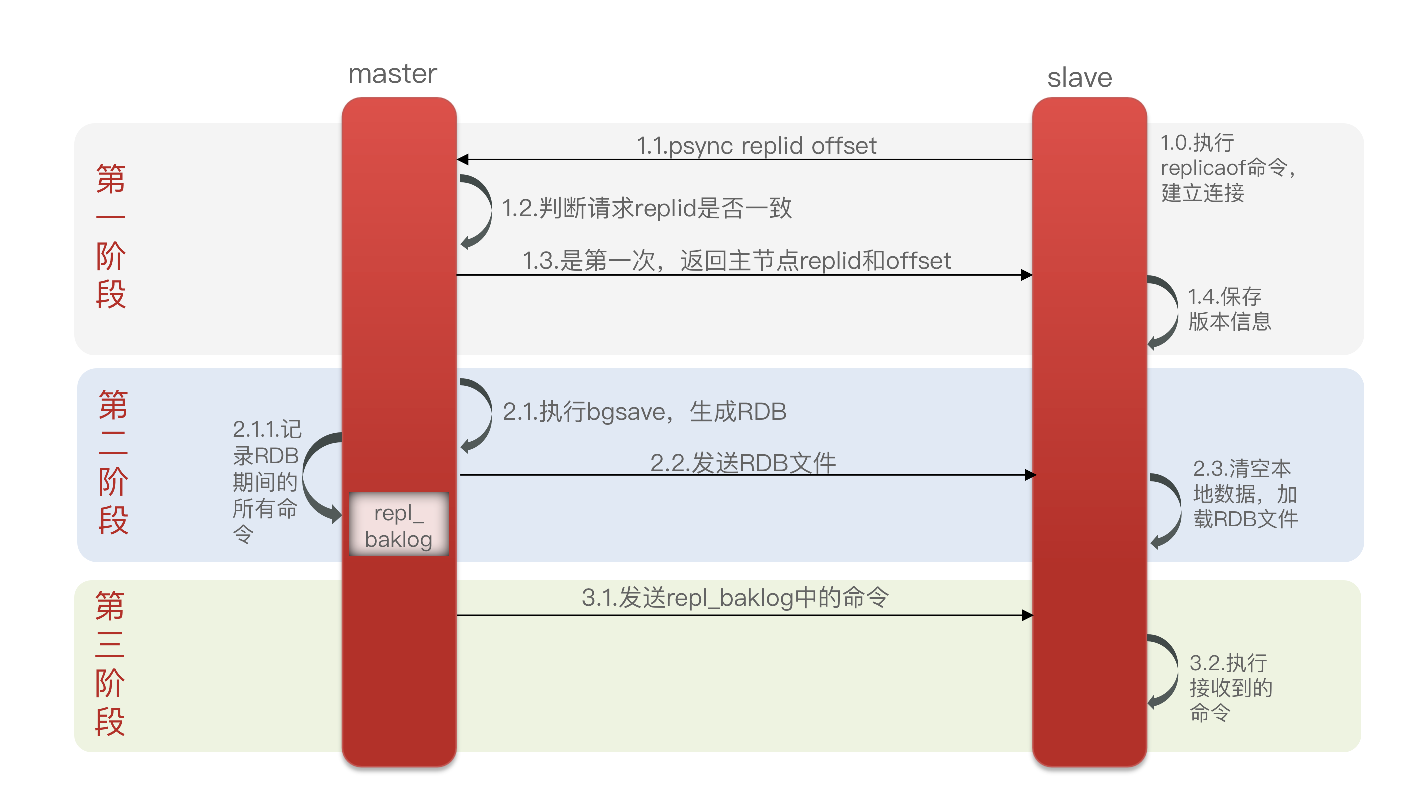
简述全量同步的流程:
- slave节点请求增量同步
- master节点判断replid,发现不一致,拒绝增量同步
- master将完整内存数据生成RDB,发送RDB到slave
- slave清空本地数据,加载master的RDB
- master将RDB期间的命令记录在repl_baklog,并持续将log中的命令发送给slave
- slave执行接收到的命令,保持与master之间的同步
增量同步
如果slave重启后同步,则执行增量同步

repl_baklog大小有上限,写满后会覆盖最早的数据。如果slave断开时间过久,导致尚未备份的数据被覆盖,则无法基于log做增量同步,只能再次全量同步。
主从集群优化
- 在master中配置
repl-diskless-sync yes启用无磁盘复制RDB,避免全量同步时的磁盘IO。 - Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
- 适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
- 限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力

Redis 哨兵机制
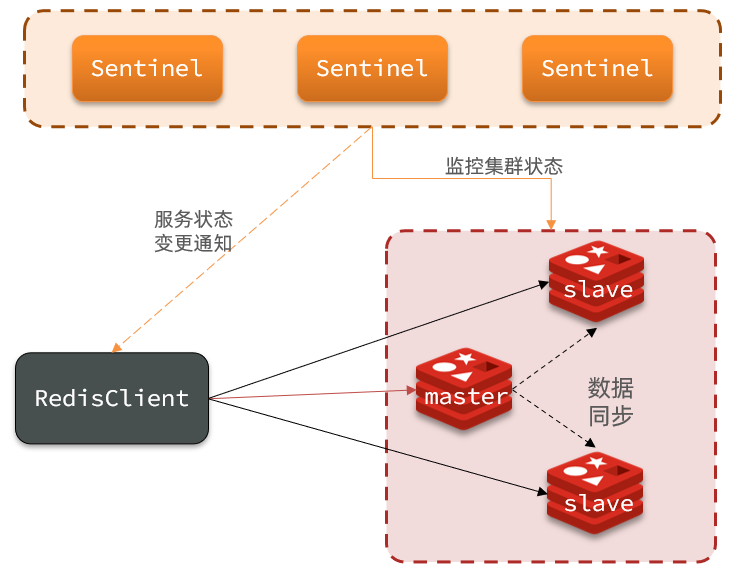
哨兵作用和原理
Redis提供了哨兵(Sentinel)机制来实现主从集群的自动故障恢复。
哨兵的作用
- 监控:Sentinel 会不断检查您的master和slave是否按预期工作
- 自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
- 通知:Sentinel充当Redis客户端的服务发现来源,当集群发生故障转移时,会将最新信息推送给Redis的客户端
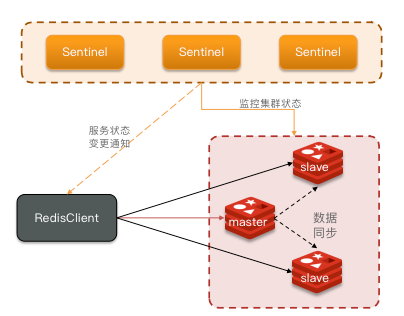
服务状态监控
Sentinel基于心跳机制监测服务状态。
每隔1秒发送一次ping命令,如果超过一定时间没有相向则认为是主观下线
如果大多数sentinel都认为实例主观下线,则判定服务客观下线
quorum值最好超过Sentinel实例数量的一半。
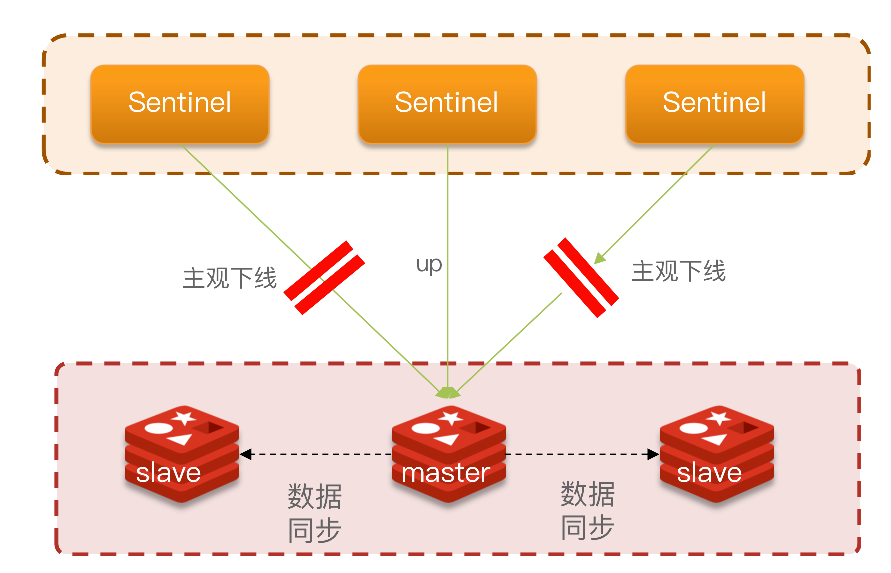
选举新的master
一旦发现master故障,sentinel需要在salve中选择一个作为新的master
- 首先会判断slave节点与master节点断开时间长短,如果超过指定值(down-after-milliseconds * 10)则会排除该slave节点
- 然后判断slave节点的slave-priority值,越小优先级越高,如果是0则永不参与选举
- 如果slave-prority一样,则判断slave节点的offset值,越大说明数据越新,优先级越高
- 最后是判断slave节点的运行id大小 (随机数),越小优先级越高。
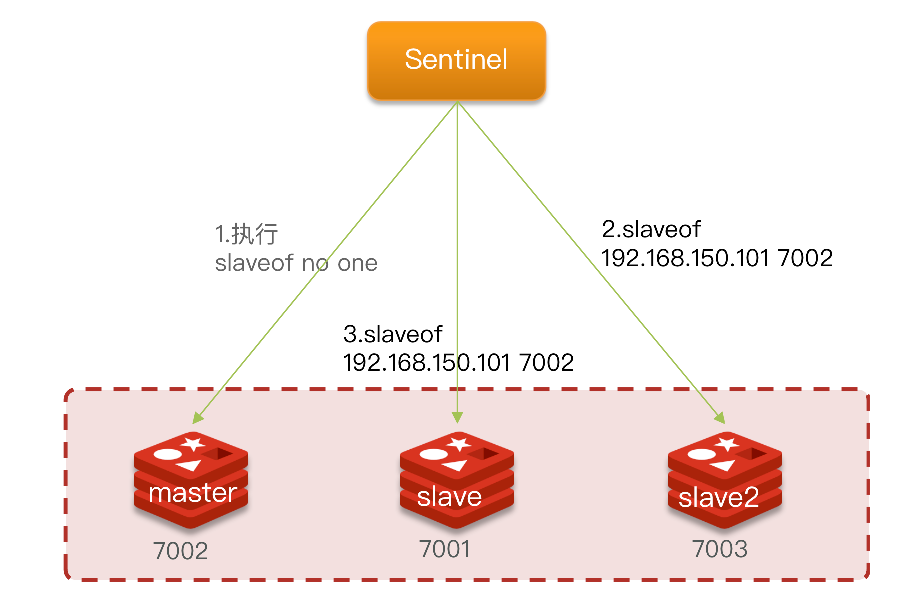
故障转移
- 首先选定一个slave作为新的master,执行slaveof no one
- 然后让所有节点都执行slaveof 新master
- 修改故障节点,执行slaveof 新master
搭建哨兵集群
集群结构
这里我们搭建一个三节点形成的Sentinel集群,来监管之前的Redis主从集群。如图:
三个sentinel实例信息如下:
| 节点 | IP | PORT |
|---|---|---|
| s1 | 192.168.150.101 | 27001 |
| s2 | 192.168.150.101 | 27002 |
| s3 | 192.168.150.101 | 27003 |
准备实例和配置
要在同一台虚拟机开启3个实例,必须准备三份不同的配置文件和目录,配置文件所在目录也就是工作目录。
我们创建三个文件夹,名字分别叫s1、s2、s3:
## 进入/tmp目录
cd /tmp
## 创建目录
mkdir s1 s2 s3如图:
然后我们在s1目录创建一个sentinel.conf文件,添加下面的内容:
port 27001
sentinel announce-ip 192.168.150.101
sentinel monitor mymaster 192.168.150.101 7001 2
sentinel down-after-milliseconds mymaster 5000
sentinel failover-timeout mymaster 60000
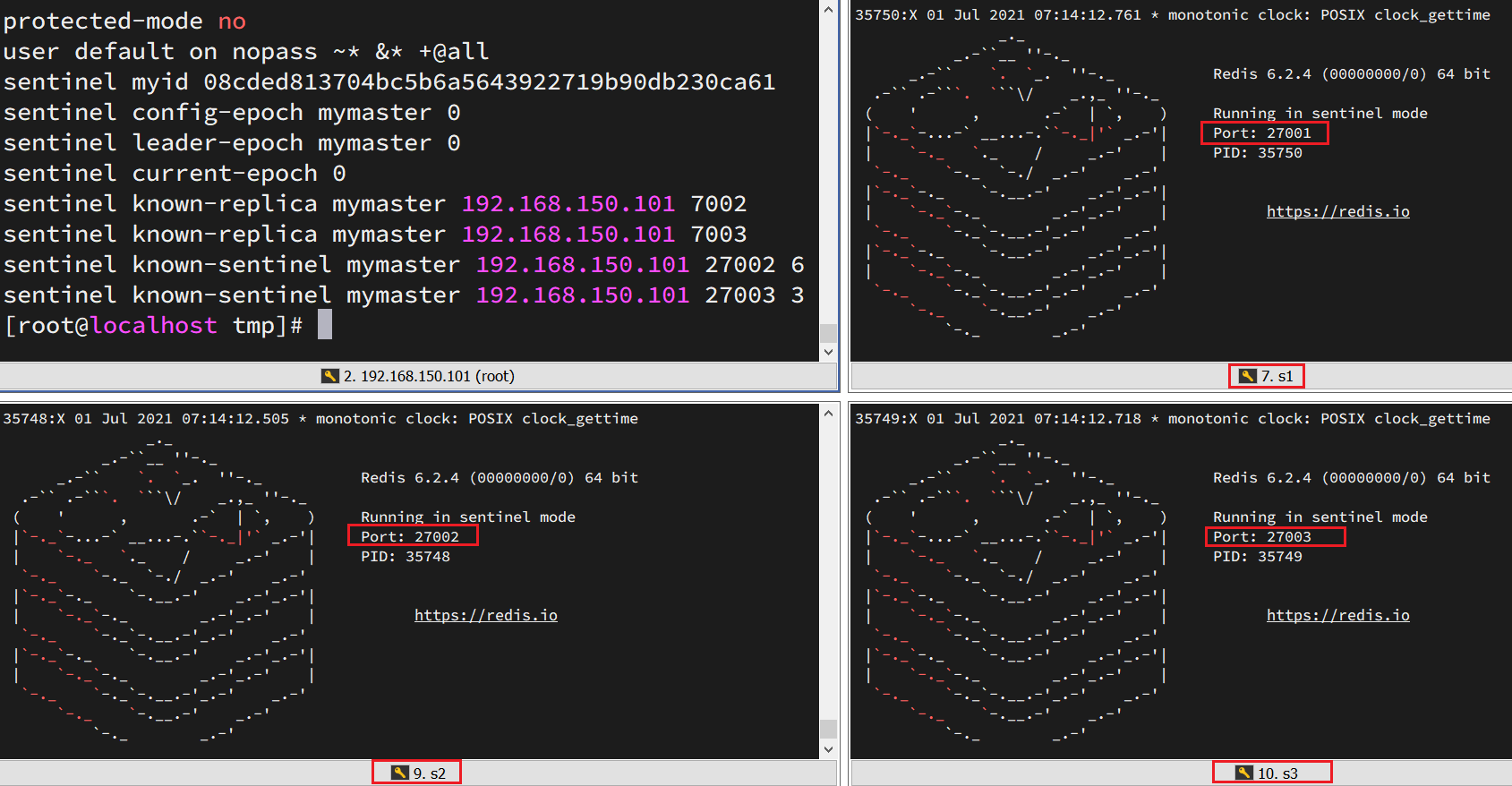
dir "/tmp/s1"解读:
port 27001:是当前sentinel实例的端口sentinel monitor mymaster 192.168.150.101 7001 2:指定主节点信息mymaster:主节点名称,自定义,任意写192.168.150.101 7001:主节点的ip和端口2:选举master时的quorum值
然后将s1/sentinel.conf文件拷贝到s2、s3两个目录中(在/tmp目录执行下列命令):
## 方式一:逐个拷贝
cp s1/sentinel.conf s2
cp s1/sentinel.conf s3
## 方式二:管道组合命令,一键拷贝
echo s2 s3 | xargs -t -n 1 cp s1/sentinel.conf修改s2、s3两个文件夹内的配置文件,将端口分别修改为27002、27003:
sed -i -e 's/27001/27002/g' -e 's/s1/s2/g' s2/sentinel.conf
sed -i -e 's/27001/27003/g' -e 's/s1/s3/g' s3/sentinel.conf启动
为了方便查看日志,我们打开3个ssh窗口,分别启动3个redis实例,启动命令:
## 第1个
redis-sentinel s1/sentinel.conf
## 第2个
redis-sentinel s2/sentinel.conf
## 第3个
redis-sentinel s3/sentinel.conf启动后:
测试
尝试让master节点7001宕机,查看sentinel日志:
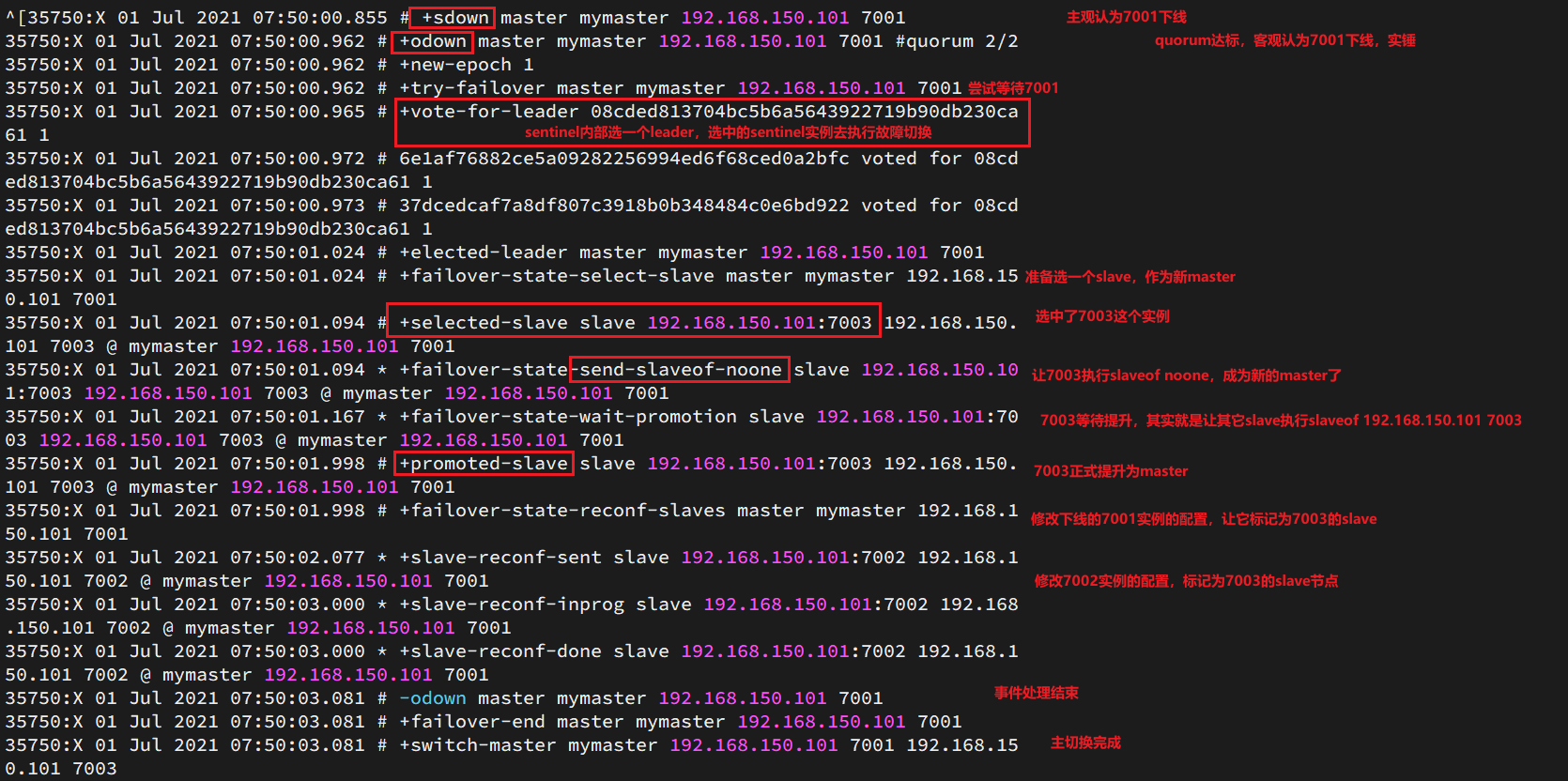
查看7003的日志:
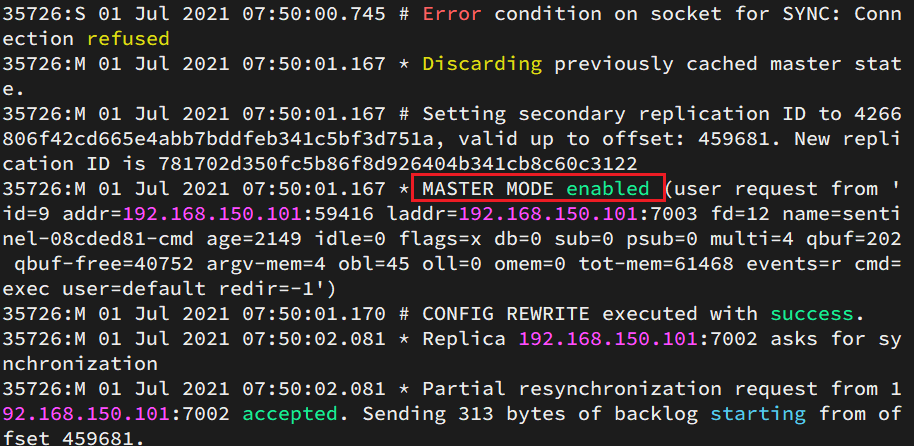
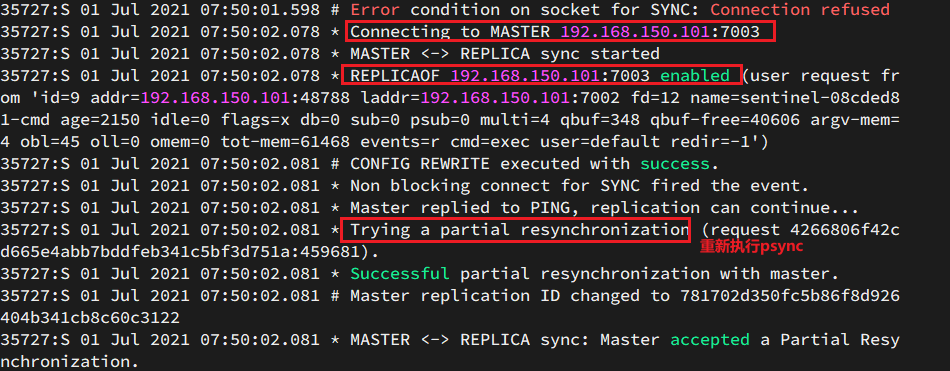
查看7002的日志:
RedisTemplate 哨兵模式
1、在pom文件中引入redis的starter依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>2、在application.yml中指定sentinel
spring:
redis:
sentinel:
master: mymaster ## 指定master名称
nodes: ## 指定redis-sentinel集群信息
- 192.168.150.101:27001
- 192.168.150.101:27002
- 192.168.150.101:270033、配置主从读写分离
@Bean
public LettuceClientConfigurationBuilderCustomizer configurationr(){
return configBuilder -> configBuilder.readFrom(ReadFrom.REPLICA_PREFERRED);
}这里的ReadFrom是配置Redis的读取策略,是一个枚举,包括下面选择:
- MASTER:从主节点读取
- MASTER_PREFERRED:优先从master节点读取,master不可用才读取replica
- REPLICA:从slave(replica)节点读取
- REPLICA _PREFERRED:优先从slave(replica)节点读取,所有的slave都不可用才读取master
Redis 分片集群
搭建分片集群
集群结构
分片集群需要的节点数量较多,这里我们搭建一个最小的分片集群,包含3个master节点,每个master包含一个slave节点,结构如下:
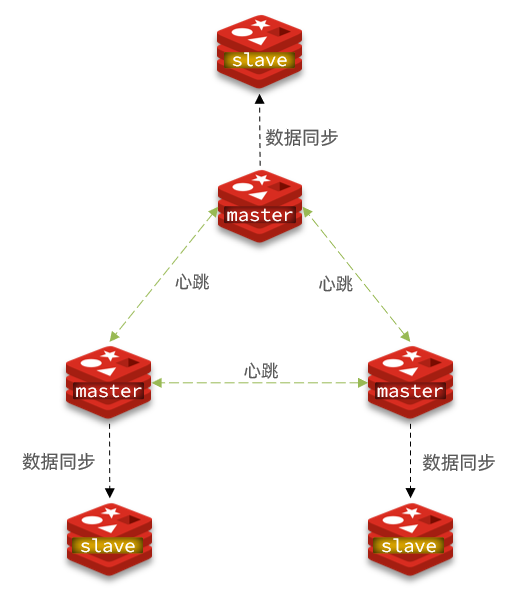
这里我们会在同一台虚拟机中开启6个redis实例,模拟分片集群,信息如下:
| IP | PORT | 角色 |
|---|---|---|
| 192.168.150.101 | 7001 | master |
| 192.168.150.101 | 7002 | master |
| 192.168.150.101 | 7003 | master |
| 192.168.150.101 | 8001 | slave |
| 192.168.150.101 | 8002 | slave |
| 192.168.150.101 | 8003 | slave |
准备实例和配置
删除之前的7001、7002、7003这几个目录,重新创建出7001、7002、7003、8001、8002、8003目录:
## 进入/tmp目录
cd /tmp
## 删除旧的,避免配置干扰
rm -rf 7001 7002 7003
## 创建目录
mkdir 7001 7002 7003 8001 8002 8003在/tmp下准备一个新的redis.conf文件,内容如下:
port 6379
## 开启集群功能
cluster-enabled yes
## 集群的配置文件名称,不需要我们创建,由redis自己维护
cluster-config-file /tmp/6379/nodes.conf
## 节点心跳失败的超时时间
cluster-node-timeout 5000
## 持久化文件存放目录
dir /tmp/6379
## 绑定地址
bind 0.0.0.0
## 让redis后台运行
daemonize yes
## 注册的实例ip
replica-announce-ip 192.168.150.101
## 保护模式
protected-mode no
## 数据库数量
databases 1
## 日志
logfile /tmp/6379/run.log将这个文件拷贝到每个目录下:
## 进入/tmp目录
cd /tmp
## 执行拷贝
echo 7001 7002 7003 8001 8002 8003 | xargs -t -n 1 cp redis.conf修改每个目录下的redis.conf,将其中的6379修改为与所在目录一致:
## 进入/tmp目录
cd /tmp
## 修改配置文件
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t sed -i 's/6379/{}/g' {}/redis.conf启动
因为已经配置了后台启动模式,所以可以直接启动服务:
## 进入/tmp目录
cd /tmp
## 一键启动所有服务
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-server {}/redis.conf通过ps查看状态:
ps -ef | grep redis发现服务都已经正常启动:

如果要关闭所有进程,可以执行命令:
ps -ef | grep redis | awk '{print $2}' | xargs kill或者(推荐这种方式):
printf '%s\n' 7001 7002 7003 8001 8002 8003 | xargs -I{} -t redis-cli -p {} shutdown创建集群
虽然服务启动了,但是目前每个服务之间都是独立的,没有任何关联。
我们需要执行命令来创建集群,在Redis5.0之前创建集群比较麻烦,5.0之后集群管理命令都集成到了redis-cli中。
1)Redis5.0之前
Redis5.0之前集群命令都是用redis安装包下的src/redis-trib.rb来实现的。因为redis-trib.rb是有ruby语言编写的所以需要安装ruby环境。
## 安装依赖
yum -y install zlib ruby rubygems
gem install redis然后通过命令来管理集群:
## 进入redis的src目录
cd /tmp/redis-6.2.4/src
## 创建集群
./redis-trib.rb create --replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:80032)Redis5.0以后
我们使用的是Redis6.2.4版本,集群管理以及集成到了redis-cli中,格式如下:
redis-cli --cluster create --cluster-replicas 1 192.168.150.101:7001 192.168.150.101:7002 192.168.150.101:7003 192.168.150.101:8001 192.168.150.101:8002 192.168.150.101:8003命令说明:
redis-cli --cluster或者./redis-trib.rb:代表集群操作命令create:代表是创建集群--replicas 1或者--cluster-replicas 1:指定集群中每个master的副本个数为1,此时节点总数 ÷ (replicas + 1)得到的就是master的数量。因此节点列表中的前n个就是master,其它节点都是slave节点,随机分配到不同master
运行后的样子:
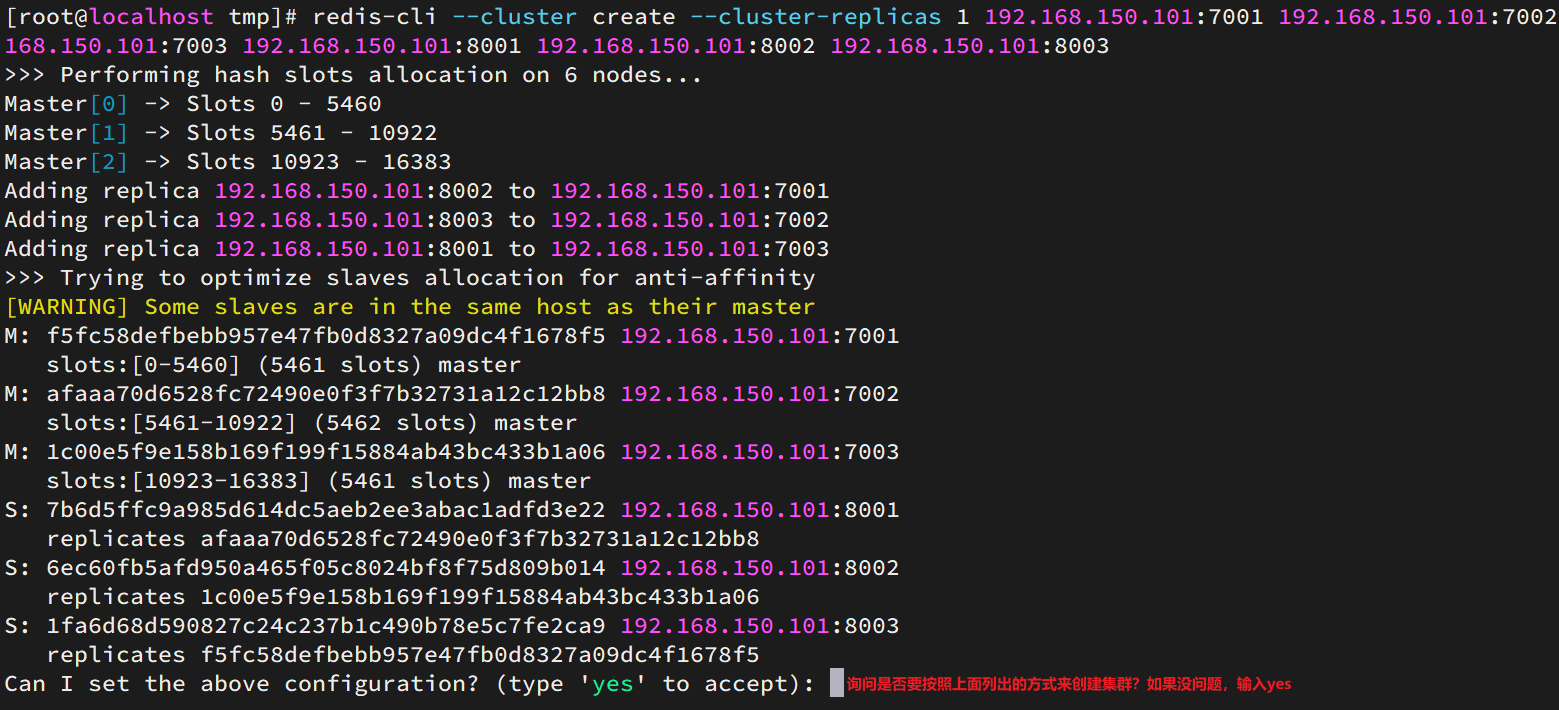
这里输入yes,则集群开始创建:
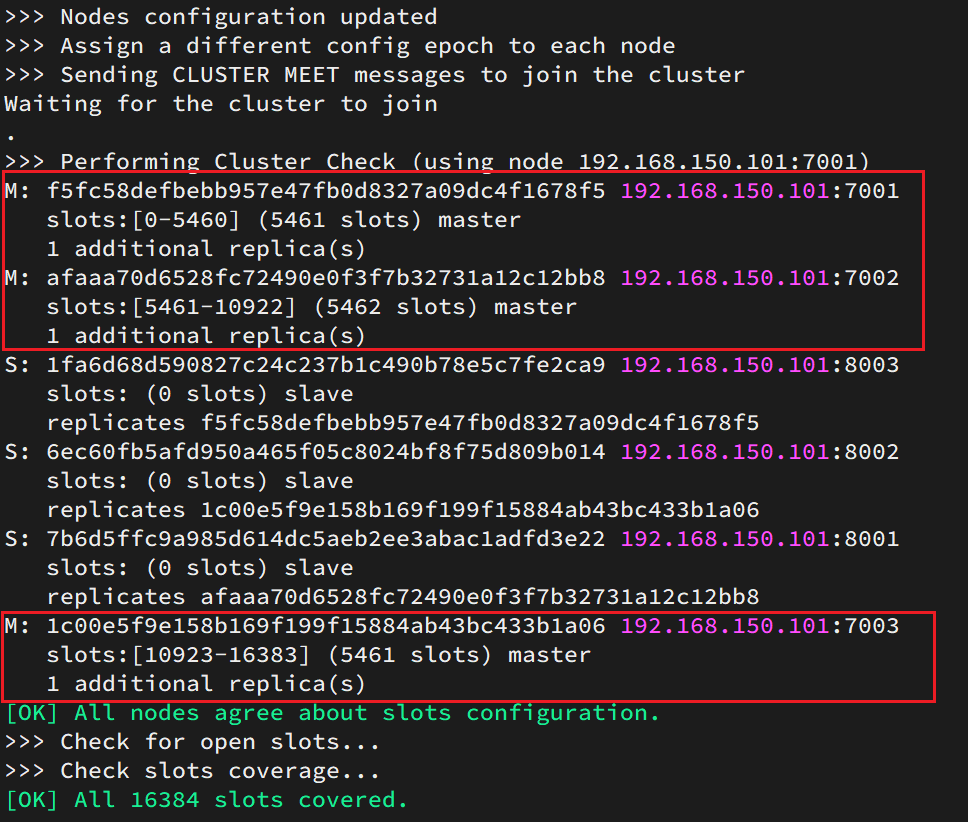
通过命令可以查看集群状态:
redis-cli -p 7001 cluster nodes
测试
尝试连接7001节点,存储一个数据:
## 连接
redis-cli -p 7001
## 存储数据
set num 123
## 读取数据
get num
## 再次存储
set a 1结果悲剧了:
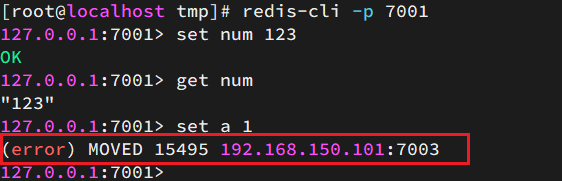
集群操作时,需要给redis-cli加上-c参数才可以:
redis-cli -c -p 7001这次可以了:
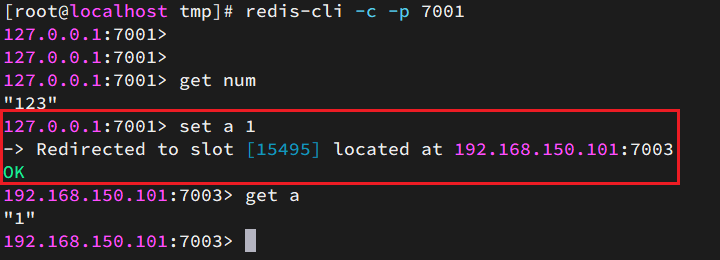
散列插槽
Redis 会把每一个master节点映射到0~16383共16384个插槽(hash slot)上
数据key不是与节点绑定,而是与插槽绑定。(方便集群伸缩)
- key中包含"{}",且“{}”中至少包含1个字符,“{}”中的部分是有效部分
- key中不包含“{}”,整个key都是有效部分
连接集群任何一个节点即可,不同节点会重定向。

如何将同一类数据固定的保存在同一个 Redis 实例?
这一类数据使用相同的有效部分,例如key都以
{typeId}为前缀
集群伸缩
1、添加节点
redis-cli --cluster add-node 192.168.150.101:7004 192.168.150.101:7001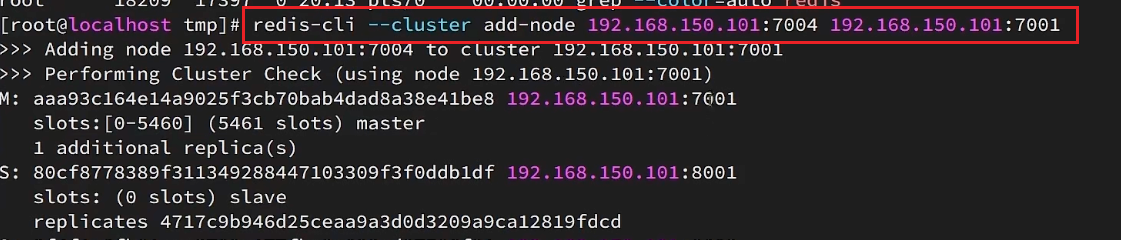
2、分配插槽
redis-cli --cluster reshard 192.168.150.101:7001
故障转移
- 该实例与其它实例失去连接
- 疑似宕机
- 确定下线,自动提升一个slave为新的master
数据迁移
利用cluster failover命令可以手动让集群中的某个master宕机,切换到执行cluster failover命令的这个slave节点,实现无感知的数据迁移。
- 缺省:默认的流程,如图1~6步
- force:省略了对offset的一致性校验
- takeover:直接执行第5步,忽略数据一致性、忽略master状态和其它master的意见

RedisTemplate 访问分片集群
- 引入redis的starter依赖
- 配置分片集群地址(指定分片集群的每一个节点信息)
- 配置读写分离
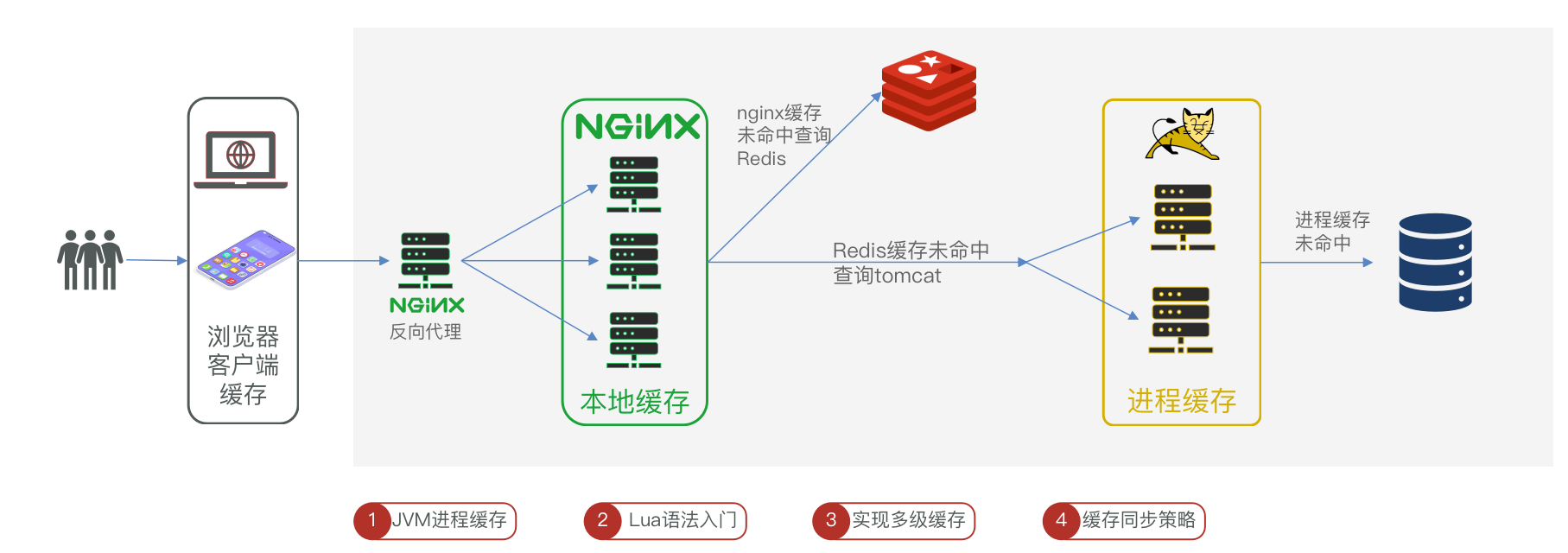
多级缓存
什么是多级缓存
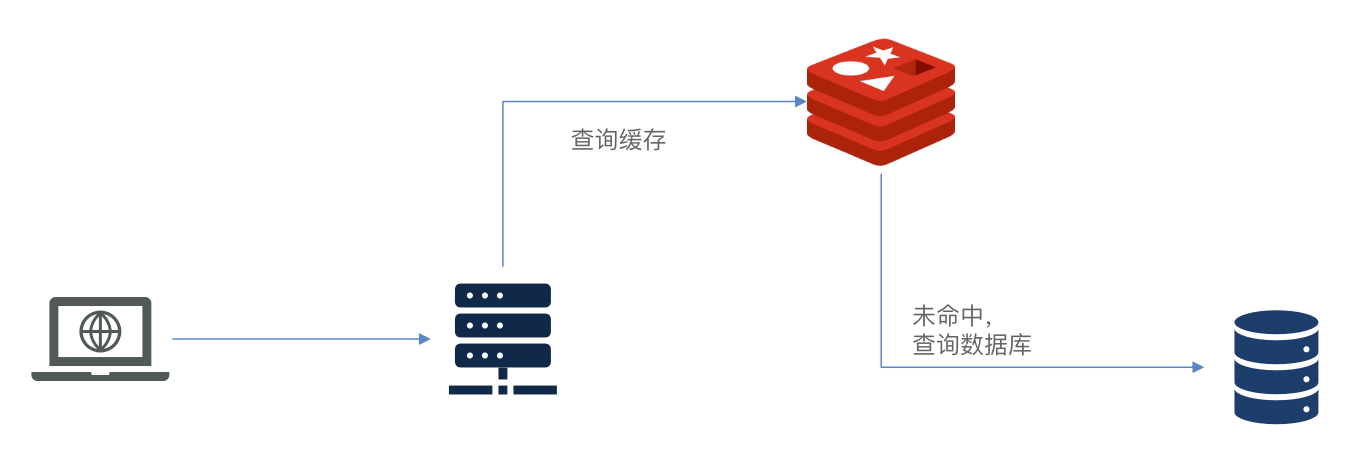
传统缓存的问题
传统的缓存策略一般是请求到达Tomcat后,先查询Redis,如果未命中则查询数据库。
存在下面的问题:
- 请求要经过Tomcat处理,Tomcat的性能成为整个系统的瓶颈
- Redis缓存失效时,会对数据库产生冲击
多级缓存方案
用作缓存的Nginx是业务Nginx,需要部署为集群,再有专门的Nginx用来做反向代理。
JVM进程缓存 Caffeine
初识Caffeine
Caffeine是一个基于Java8开发的,提供了近乎最佳命中率的高性能的本地缓存库。
ben-manes/caffeine: A high performance caching library for Java (github.com)
实例代码
@Test
void testBasicOps() {
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder().build();
// 存数据
cache.put("gf", "迪丽热巴");
// 取数据,不存在则返回null
String gf = cache.getIfPresent("gf");
System.out.println("gf = " + gf);
// 取数据,包含两个参数:
// 参数一:缓存的key
// 参数二:Lambda表达式,表达式参数就是缓存的key,方法体是查询数据库的逻辑
// 优先根据key查询缓存,如果未命中,则执行参数二的Lambda表达式
String defaultGF = cache.get("defaultGF", key -> {
// 这里可以去数据库根据 key查询value
return "柳岩";
});
System.out.println("defaultGF = " + defaultGF);
}缓存驱逐策略
1、基于容量
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
.maximumSize(1) // 设置缓存大小上限为 1
.build();2、基于时间
// 创建缓存对象
Cache<String, String> cache = Caffeine.newBuilder()
// 设置缓存有效期为 10 秒,从最后一次写入开始计时
.expireAfterWrite(Duration.ofSeconds(10))
.build();3、基于引用:利用GC来回收缓存数据(不推荐)
在默认情况下,当一个缓存元素过期的时候,Caffeine不会自动立即将其清理和驱逐。而是在一次读或写操作后,或者在空闲时间完成对失效数据的驱逐。
实现缓存
1、声明Bean
@Configuration
public class CaffeineConfig {
@Bean
public Cache<Long, Item> itemCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
@Bean
public Cache<Long, ItemStock> stockCache(){
return Caffeine.newBuilder()
.initialCapacity(100)
.maximumSize(10_000)
.build();
}
}2、使用Cache对象
@Autowired
private Cache<Long, Item> itemCache;
@Autowired
private Cache<Long, ItemStock> stockCache;
// ...
@GetMapping("/{id}")
public Item findById(@PathVariable("id") Long id) {
return itemCache.get(id, key -> itemService.query()
.ne("status", 3).eq("id", key)
.one()
);
}
@GetMapping("/stock/{id}")
public ItemStock findStockById(@PathVariable("id") Long id) {
return stockCache.get(id, key -> stockService.getById(key));
}Lua语法入门
变量和循环
数据类型:
| 数据类型 | 描述 |
|---|---|
| nil | 这个最简单,只有值nil属于该类,表示一个无效值(在条件表达式中相当于false)。 |
| boolean | 包含两个值:false和true |
| number | 表示双精度类型的实浮点数 |
| string | 字符串由一对双引号或单引号来表示 |
| function | 由 C 或 Lua 编写的函数 |
| table | Lua 中的表(table)其实是一个"关联数组"(associative arrays),数组的索引可以是数字、字符串或表类型。在 Lua 里,table 的创建是通过"构造表达式"来完成,最简单构造表达式是{},用来创建一个空表。 |
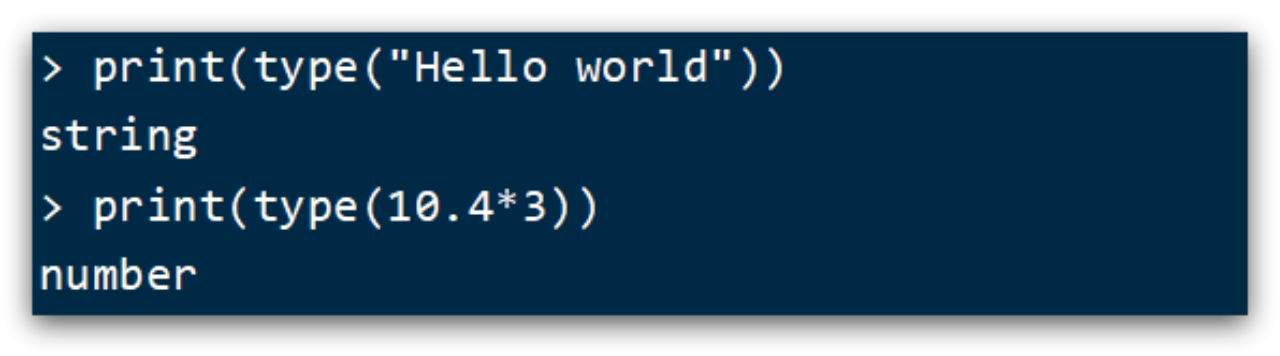
利用type函数测试给定变量或者值的类型
Lua声明变量的时候,并不需要指定数据类型
-- 声明字符串
local str = 'hello'
-- 字符串拼接可以使用 ..
local str2 = 'hello' .. 'world'
-- 声明数字
local num = 21
-- 声明布尔类型
local flag = true
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 声明table,类似java的map
local map = {name='Jack', age=21}
-- 访问数组,lua数组的角标从1开始
print(arr[1])
-- 访问table
print(map['name'])
print(map.name)数组、table都可以利用for循环来遍历
-- 声明数组 key为索引的 table
local arr = {'java', 'python', 'lua'}
-- 遍历数组
for index,value in ipairs(arr) do
print(index, value)
end
-- 声明map,也就是table
local map = {name='Jack', age=21}
-- 遍历table
for key,value in pairs(map) do
print(key, value)
end条件控制、函数
定义函数的语法:
function 函数名(argument1, argument2, ..., argumentn)
-- 函数体
return 返回值
endif、else语法:
if(布尔表达式)
then
--[ 布尔表达式为 true 时执行该语句块 --]
else
--[ 布尔表达式为 false 时执行该语句块 --]
end逻辑运算符:
| 操作符 | 描述 | 实例 |
|---|---|---|
| and | 逻辑与操作符。若 A 为 false,则返回 A,否则返回 B。 | (A and B) 为 false。 |
| or | 逻辑或操作符。若 A 为 true,则返回 A,否则返回 B。 | (A or B) 为 true。 |
| not | 逻辑非操作符。与逻辑运算结果相反,如果条件为 true,逻辑非为 false。 | not(A and B) 为 true。 |
多级缓存
初识 OpenResty
基于 Nginx的高性能 Web 平台,用于方便地搭建能够处理超高并发、扩展性极高的动态 Web 应用、Web 服务和动态网关。
- 具备Nginx的完整功能
- 基于Lua语言进行扩展,集成了大量精良的 Lua 库、第三方模块
- 允许使用Lua自定义业务逻辑、自定义库

OpenResty 的安装
安装
首先你的Linux虚拟机必须联网
1)安装开发库
首先要安装OpenResty的依赖开发库,执行命令:
yum install -y pcre-devel openssl-devel gcc --skip-broken2)安装OpenResty仓库
你可以在你的 CentOS 系统中添加 openresty 仓库,这样就可以便于未来安装或更新我们的软件包(通过 yum check-update 命令)。运行下面的命令就可以添加我们的仓库:
yum-config-manager --add-repo https://openresty.org/package/centos/openresty.repo如果提示说命令不存在,则运行:
yum install -y yum-utils然后再重复上面的命令
3)安装OpenResty
然后就可以像下面这样安装软件包,比如 openresty:
yum install -y openresty4)安装opm工具
opm是OpenResty的一个管理工具,可以帮助我们安装一个第三方的Lua模块。
如果你想安装命令行工具 opm,那么可以像下面这样安装 openresty-opm 包:
yum install -y openresty-opm5)目录结构
默认情况下,OpenResty安装的目录是:/usr/local/openresty
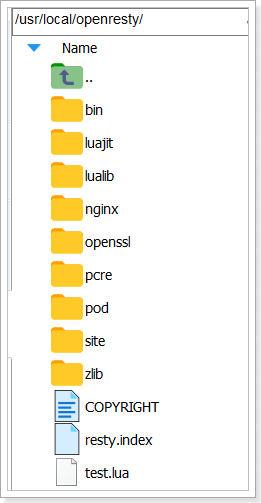
看到里面的nginx目录了吗,OpenResty就是在Nginx基础上集成了一些Lua模块。
6)配置nginx的环境变量
打开配置文件:
vi /etc/profile在最下面加入两行:
export NGINX_HOME=/usr/local/openresty/nginx
export PATH=${NGINX_HOME}/sbin:$PATHNGINX_HOME:后面是OpenResty安装目录下的nginx的目录
然后让配置生效:
source /etc/profile启动和运行
OpenResty底层是基于Nginx的,查看OpenResty目录的nginx目录,结构与windows中安装的nginx基本一致:
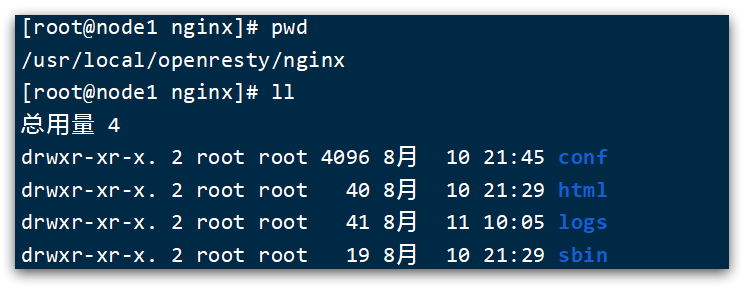
所以运行方式与nginx基本一致:
## 启动nginx
nginx
## 重新加载配置
nginx -s reload
## 停止
nginx -s stopnginx的默认配置文件注释太多,影响后续我们的编辑,这里将nginx.conf中的注释部分删除,保留有效部分。
修改/usr/local/openresty/nginx/conf/nginx.conf文件,内容如下:
#user nobody;
worker_processes 1;
error_log logs/error.log;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
server {
listen 8081;
server_name localhost;
location / {
root html;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
}在Linux的控制台输入命令以启动nginx:
nginx然后访问页面:http://192.168.150.101:8081,注意ip地址替换为你自己的虚拟机IP:
OpenResty快速入门
1、在nginx.conf的http下面,添加对OpenResty的Lua模块的加载
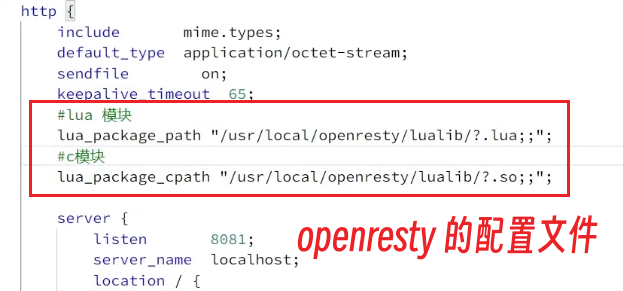
#lua 模块
lua_package_path "/usr/local/openresty/lualib/?.lua;;";
#c模块
lua_package_cpath "/usr/local/openresty/lualib/?.so;;";2、在nginx.conf的server下面,添加对/api/item这个路径的监听
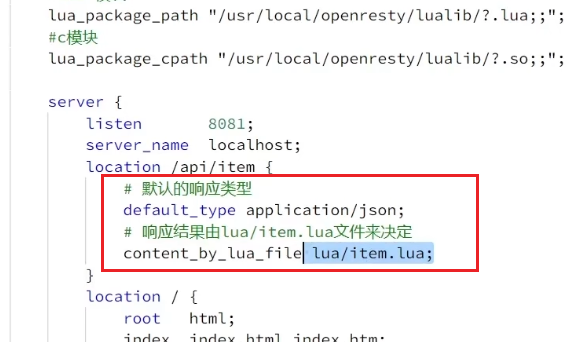
location /api/item {
## 响应类型,这里返回json
default_type application/json;
## 响应数据由 lua/item.lua这个文件来决定
content_by_lua_file lua/item.lua;
}3、在nginx目录创建文件夹:lua,在lua文件夹下,新建文件:item.lua
-- 返回假数据,这里的ngx.say()函数,就是写数据到Response中
ngx.say('{"id":10001,"data":"hello"}')4、重新加载配置
nginx -s reload请求参数处理
路径占位符 /item/1001
# 1.正则表达式匹配:
location ~ /item/(\d+) {
content_by_lua_file lua/item.lua;
}-- 2. 匹配到的参数会存入ngx.var数组中,
-- 可以用角标获取
local id = ngx.var[1]请求头 id: 1001
-- 获取请求头,返回值是table类型
local headers = ngx.req.get_headers()Get请求参数 ?id=1001
-- 获取GET请求参数,返回值是table类型
local getParams = ngx.req.get_uri_args()Post表单参数 id=1001
-- 读取请求体
ngx.req.read_body()
-- 获取POST表单参数,返回值是table类型
local postParams = ngx.req.get_post_args()JSON参数
-- 读取请求体
ngx.req.read_body()
-- 获取body中的json参数,返回值是string类型
local jsonBody = ngx.req.get_body_data()查询Tomcat
nginx内部发送Http请求
nginx提供了内部API用以发送http请求
local resp = ngx.location.capture("/path",{
method = ngx.HTTP_GET, -- 请求方式
args = {a=1,b=2}, -- get方式传参数
body = "c=3&d=4" -- post方式传参数
})注意:这里的path是路径,并不包含IP和端口。这个请求会被nginx内部的server监听并处理。
但是我们希望这个请求发送到Tomcat服务器,所以还需要编写一个server来对这个路径做反向代理:

封装http查询的函数
把http查询的请求封装为一个函数,放到OpenResty函数库中
在/usr/local/openresty/lualib目录下创建common.lua文件
-- 封装函数,发送http请求,并解析响应
local function read_http(path, params)
local resp = ngx.location.capture(path,{
method = ngx.HTTP_GET,
args = params,
})
if not resp then
-- 记录错误信息,返回404
ngx.log(ngx.ERR, "http not found, path: ", path , ", args: ", args)
ngx.exit(404)
end
return resp.body
end
-- 将方法导出
local _M = {
read_http = read_http
}
return _M使用Http函数查询数据
修改item.lua文件
-- 引入自定义工具模块
local common = require("common")
local read_http = common.read_http
-- 获取路径参数
local id = ngx.var[1]
-- 根据id查询商品
local itemJSON = read_http("/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_http("/item/stock/".. id, nil)JSON结果处理
OpenResty提供了一个cjson的模块用来处理JSON的序列化和反序列化。
openresty/lua-cjson: Lua CJSON is a fast JSON encoding/parsing module for Lua (github.com)
-- 引入cjson模块
local cjson = require "cjson"
-- 序列化
local obj = {
name = 'jack',
age = 21
}
local json = cjson.encode(obj)
-- 反序列化
local json = '{"name": "jack", "age": 21}'
local obj = cjson.decode(json);
print(obj.name)Tomcat集群的负载均衡
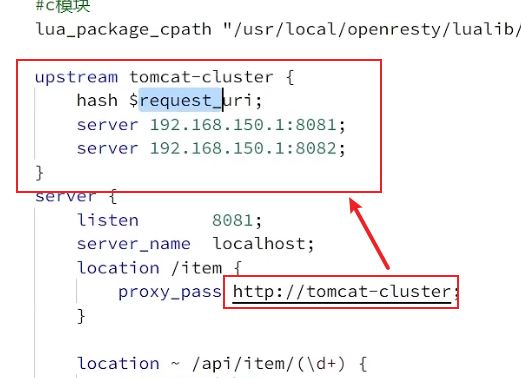
# 反向代理配置,将/item路径的请求代理到tomcat集群
location /item {
proxy_pass http://tomcat-cluster;
}
# tomcat集群配置
upstream tomcat-cluster{
## 对请求的 URI 进行哈希处理
hash $request_uri;
server 192.168.150.1:8081;
server 192.168.150.1:8082;
}
Redis缓存预热
冷启动:服务刚刚启动时,Redis中并没有缓存,如果所有商品数据都在第一次查询时添加缓存,可能会给数据库带来较大压力。
缓存预热:在实际开发中,我们可以利用大数据统计用户访问的热点数据,在项目启动时将这些热点数据提前查询并保存到Redis中。
@Component
public class RedisHandler implements InitializingBean {
@Autowired
private StringRedisTemplate redisTemplate;
@Override
public void afterPropertiesSet() throws Exception {
// 初始化缓存 ...
}
}查询Redis缓存
OpenResty的Redis模块
OpenResty提供了操作Redis的模块
-- 引入redis模块
local redis = require("resty.redis")
-- 初始化Redis对象
local red = redis:new()
-- 设置Redis超时时间
red:set_timeouts(1000, 1000, 1000)封装函数,用来释放Redis连接,其实是放入连接池
-- 关闭redis连接的工具方法,其实是放入连接池
local function close_redis(red)
local pool_max_idle_time = 10000 -- 连接的空闲时间,单位是毫秒
local pool_size = 100 --连接池大小
local ok, err = red:set_keepalive(pool_max_idle_time, pool_size)
if not ok then
ngx.log(ngx.ERR, "放入Redis连接池失败: ", err)
end
end封装函数,从Redis读数据并返回
-- 查询redis的方法 ip和port是redis地址,key是查询的key
local function read_redis(ip, port, key)
-- 获取一个连接
local ok, err = red:connect(ip, port)
if not ok then
ngx.log(ngx.ERR, "连接redis失败 : ", err)
return nil
end
-- 查询redis
local resp, err = red:get(key)
-- 查询失败处理
if not resp then
ngx.log(ngx.ERR, "查询Redis失败: ", err, ", key = " , key)
end
--得到的数据为空处理
if resp == ngx.null then
resp = nil
ngx.log(ngx.ERR, "查询Redis数据为空, key = ", key)
end
close_redis(red)
return resp
end业务实现
-- 封装函数,先查询redis,再查询http
local function read_data(key, path, params)
-- 查询redis
local resp = read_redis("127.0.0.1", 6379, key)
-- 判断redis是否命中
if not resp then
-- Redis查询失败,查询http
resp = read_http(path, params)
end
return resp
endNginx本地缓存
开启共享词典,在nginx.conf的http下添加配置:
## 共享字典,也就是本地缓存,名称叫做:item_cache,大小150m
lua_shared_dict item_cache 150m;
操作共享字典
-- 获取本地缓存对象
local item_cache = ngx.shared.item_cache
-- 存储, 指定key、value、过期时间,单位s,默认为0代表永不过期
item_cache:set('key', 'value', 1000)
-- 读取
local val = item_cache:get('key')修改后的查询逻辑
-- 封装函数,先查询本地缓存,再查询redis,再查询http
local function read_data(key, expire, path, params)
-- 读取本地缓存
local val = item_cache:get(key)
if not val then
-- 缓存未命中,记录日志
ngx.log(ngx.ERR, "本地缓存查询失败, key: ", key , ", 尝试redis查询")
-- 查询redis
val = read_redis("127.0.0.1", 6379, key)
-- 判断redis是否命中
if not val then
ngx.log(ngx.ERR, "Redis缓存查询失败, key: ", key , ", 尝试http查询")
-- Redis查询失败,查询http
val = read_http(path, params)
end
end
-- 写入本地缓存
item_cache:set(key, val, expire)
return val
end
-- 根据id查询商品
local itemJSON = read_data('item:id:' .. id, 1800, "/item/".. id, nil)
-- 根据id查询商品库存
local itemStockJSON = read_data('item:stock:id:' .. id, 60, "/item/stock/".. id, nil)graph
A[开始] --> B{本地缓存命中?}
B -->|是| C[返回缓存数据]
B -->|否| D[记录日志: 本地缓存查询失败]
D --> E[尝试redis查询]
E --> F{Redis命中?}
F -->|是| G[返回Redis数据]
F -->|否| H[记录日志: Redis缓存查询失败]
H --> I[尝试http查询]
I --> J[返回http数据]
J --> K[写入本地缓存]
K --> L[返回数据]
style A fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#f9f,stroke:#333,stroke-width:2px
style C fill:#ccf,stroke:#f66,stroke-width:2px
style D fill:#f9f,stroke:#333,stroke-width:2px
style E fill:#f9f,stroke:#333,stroke-width:2px
style F fill:#f9f,stroke:#333,stroke-width:2px
style G fill:#ccf,stroke:#f66,stroke-width:2px
style H fill:#f9f,stroke:#333,stroke-width:2px
style I fill:#f9f,stroke:#333,stroke-width:2px
style J fill:#ccf,stroke:#f66,stroke-width:2px
style K fill:#ccf,stroke:#f66,stroke-width:2px
style L fill:#ccf,stroke:#f66,stroke-width:2px缓存同步策略
缓存同步策略
设置有效期:给缓存设置有效期,到期后自动删除。再次查询时更新
- 优势:简单、方便
- 缺点:时效性差,缓存过期之前可能不一致
- 场景:更新频率较低,时效性要求低的业务
同步双写:在修改数据库的同时,直接修改缓存
- 优势:时效性强,缓存与数据库强一致
- 缺点:有代码侵入,耦合度高
- 场景:对一致性、时效性要求较高的缓存数据
异步通知:修改数据库时发送事件通知,相关服务监听到通知后修改缓存数据
- 优势:低耦合,可以同时通知多个缓存服务
- 缺点:时效性一般,可能存在中间不一致状态
- 场景:时效性要求一般,有多个服务需要同步
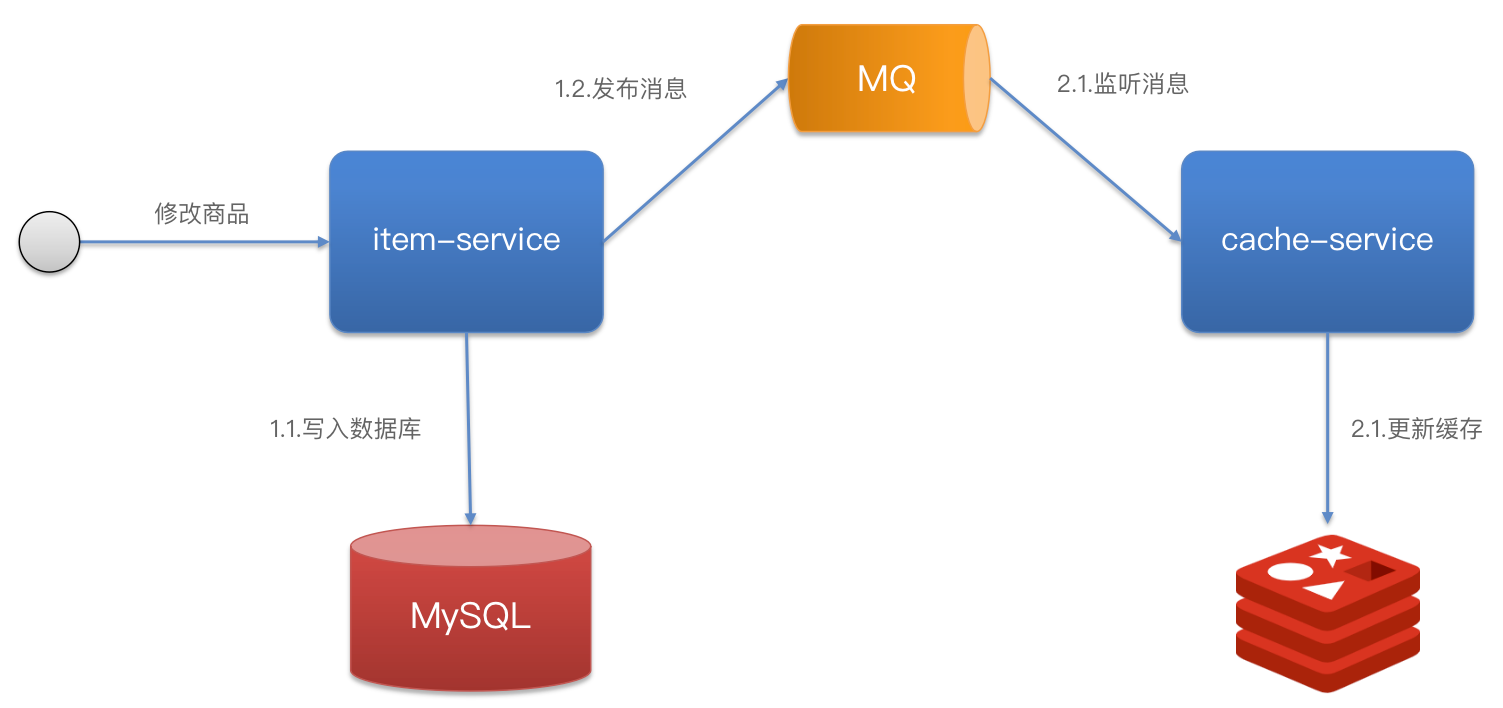
基于MQ的异步通知:
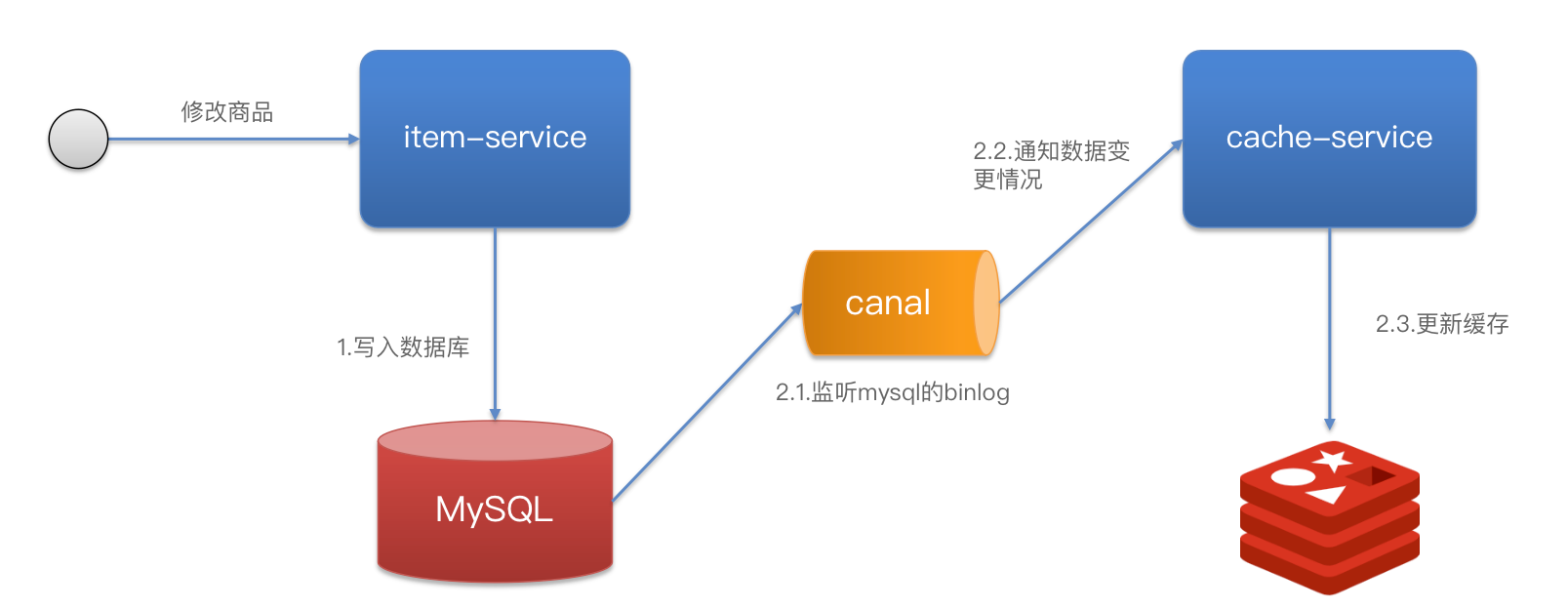
基于Canal的异步通知:
初始Canal
canal是阿里巴巴旗下的一款开源项目,基于Java开发。基于数据库增量日志解析,提供增量数据订阅和消费。Canal是基于mysql的主从同步来实现的。
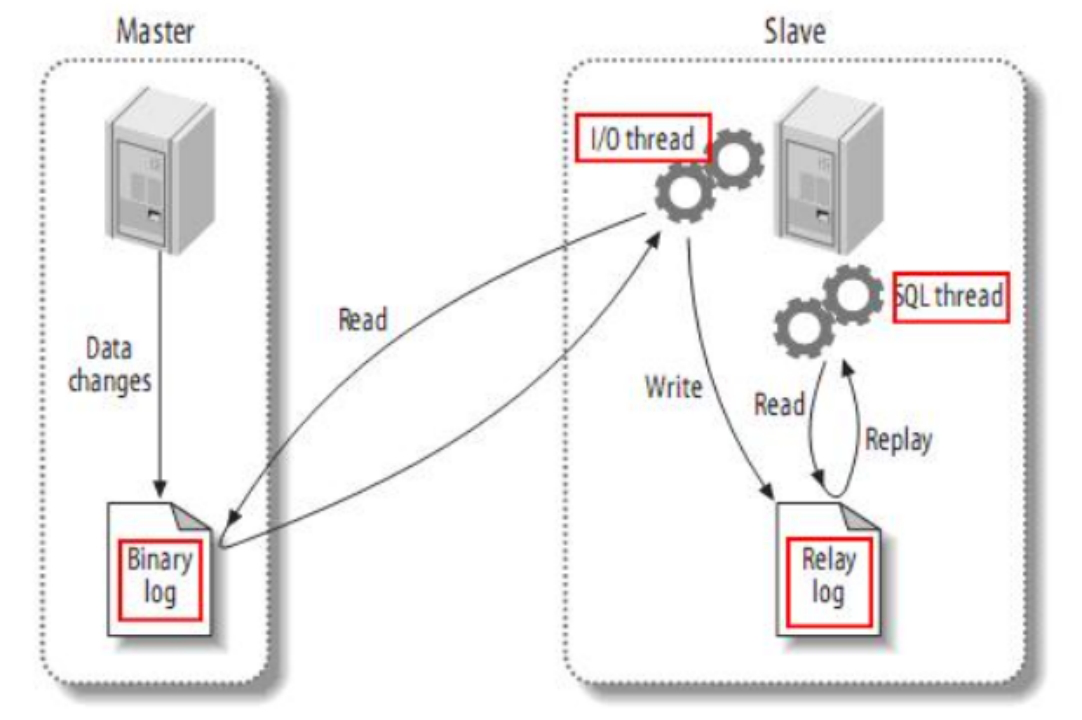
Canal就是把自己伪装成MySQL的一个slave节点,从而监听master的binary log变化。再把得到的变化信息通知给Canal的客户端,进而完成对其它数据库的同步。
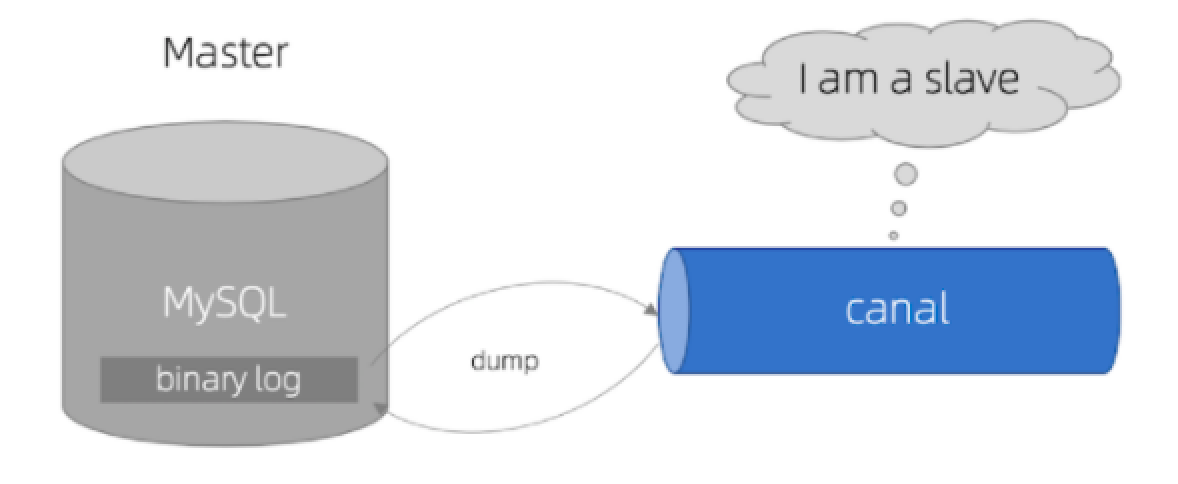
安装和配置 Canal
下面我们就开启mysql的主从同步机制,让Canal来模拟salve
Canal是基于MySQL的主从同步功能,因此必须先开启MySQL的主从功能才可以。
这里以之前用Docker运行的mysql为例:
开启binlog
打开mysql容器挂载的日志文件,我的在/tmp/mysql/conf目录:
修改文件:
vi /tmp/mysql/conf/my.cnf添加内容:
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima配置解读:
log-bin=/var/lib/mysql/mysql-bin:设置binary log文件的存放地址和文件名,叫做mysql-binbinlog-do-db=heima:指定对哪个database记录binary log events,这里记录heima这个库
最终效果:
[mysqld]
skip-name-resolve
character_set_server=utf8
datadir=/var/lib/mysql
server-id=1000
log-bin=/var/lib/mysql/mysql-bin
binlog-do-db=heima设置用户权限
接下来添加一个仅用于数据同步的账户,出于安全考虑,这里仅提供对heima这个库的操作权限。
create user canal@'%' IDENTIFIED by 'canal';
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT,SUPER ON *.* TO 'canal'@'%' identified by 'canal';
FLUSH PRIVILEGES;重启mysql容器即可
docker restart mysql测试设置是否成功:在mysql控制台,或者Navicat中,输入命令:
show master status;
创建网络
我们需要创建一个网络,将MySQL、Canal、MQ放到同一个Docker网络中:
docker network create heima让mysql加入这个网络:
docker network connect heima mysql安装Canal
通过命令导入canal的镜像压缩包:
docker load -i canal.tar然后运行命令创建Canal容器:
docker run -p 11111:11111 --name canal \
-e canal.destinations=heima \
-e canal.instance.master.address=mysql:3306 \
-e canal.instance.dbUsername=canal \
-e canal.instance.dbPassword=canal \
-e canal.instance.connectionCharset=UTF-8 \
-e canal.instance.tsdb.enable=true \
-e canal.instance.gtidon=false \
-e canal.instance.filter.regex=heima\\..* \
--network heima \
-d canal/canal-server:v1.1.5说明:
-p 11111:11111:这是canal的默认监听端口-e canal.instance.master.address=mysql:3306:数据库地址和端口,如果不知道mysql容器地址,可以通过docker inspect 容器id来查看-e canal.instance.dbUsername=canal:数据库用户名-e canal.instance.dbPassword=canal:数据库密码-e canal.instance.filter.regex=:要监听的表名称
表名称监听支持的语法:
mysql 数据解析关注的表,Perl正则表达式.
多个正则之间以逗号(,)分隔,转义符需要双斜杠(\\)
常见例子:
1. 所有表:.* or .*\\..*
2. canal schema下所有表: canal\\..*
3. canal下的以canal打头的表:canal\\.canal.*
4. canal schema下的一张表:canal.test1
5. 多个规则组合使用然后以逗号隔开:canal\\..*,mysql.test1,mysql.test2监听Canal
Canal提供了各种语言的客户端,当Canal监听到binlog变化时,会通知Canal的客户端。
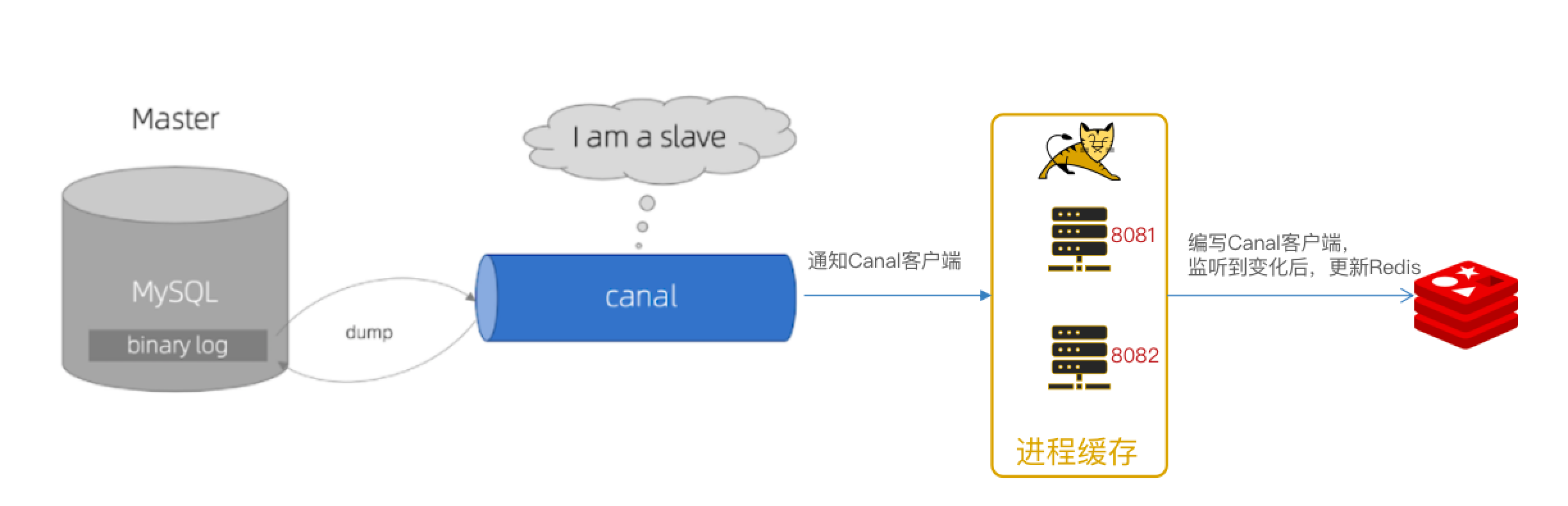
使用第三方开源的canal-starter
NormanGyllenhaal/canal-client: spring boot canal starter 易用的canal 客户端 canal client (github.com)
<!--canal-->
<dependency>
<groupId>top.javatool</groupId>
<artifactId>canal-spring-boot-starter</artifactId>
<version>1.2.1-RELEASE</version>
</dependency>canal:
destination: heima ## canal实例名称,要跟canal-server运行时设置的destination一致
server: 192.168.150.101:11111 ## canal地址package com.heima.item.canal;
// 指定要监听的表
@CanalTable("tb_item")
@Component
// 指定表关联的实体类
public class ItemHandler implements EntryHandler<Item> {
// 监听到数据库的增、改、删 的消息
@Override
public void insert(Item item) {
// 新增数据到redis
}
@Override
public void update(Item before, Item after) {
// 更新redis数据
// 更新本地缓存
}
@Override
public void delete(Item item) {
// 删除redis数据
// 清理本地缓存
}
}@Data
@TableName("tb_item")
public class Item {
@TableId(type = IdType.AUTO)
// 标记表中的id字段
@Id
private Long id;
// 标记表中与属性名不一致的字段
@Column(name = "name")
private String name;
private Date updateTime;
@TableField(exist = false)
// 标记不属于表中的字段
@Transient
private Integer stock;
@TableField(exist = false)
// 标记不属于表中的字段
@Transient
private Integer sold;
}